知识蒸馏方法的演进历史综述( 二 )
 文章插图
文章插图
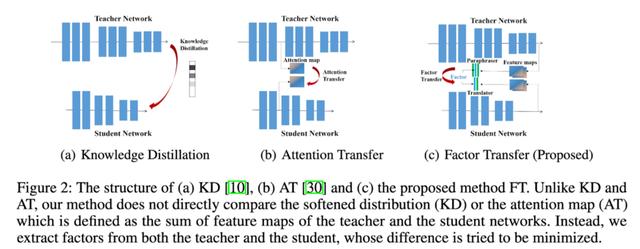
他们在模型中增加了另一个模块 , 他们称之为paraphraser 。 它基本上是一个不减少尺寸的自编码器 。 从最后一层开始 , 他们又分出另外一层用于reconstruction loss 。
学生模型中还有另一个名为translator的模块 。 它把学生模型的最后一层的输出嵌入到老师的paraphraser维度中 。 他们用老师潜在的paraphrased 表示作为hints 。
学生模型应该能够为来自教师网络的输入构造一个自编码器的表示 。
AComprehensive Overhaul of Feature Distillation在2019年 , A Comprehensive Overhaul of Feature Distillation发布于ICCV 2019 。
 文章插图
文章插图
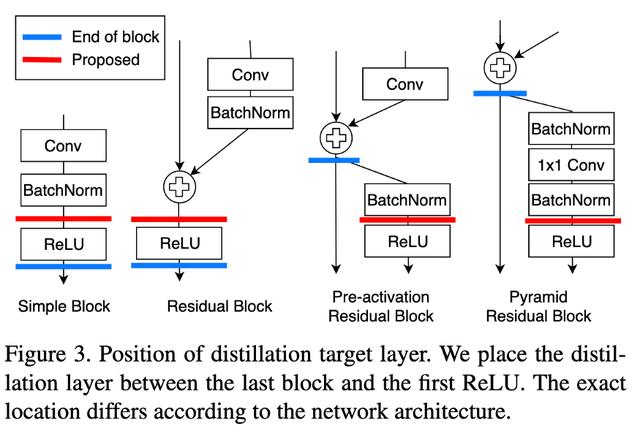
他们认为我们获取hints的位置不是最佳的 。 通过ReLU对输出进行细化 , 在转换过程中会丢失一些信息 。 他们提出了marginReLU激活函数(移位的ReLU) 。 “在我们的margin ReLU , 积极的(有益的)信息被使用而没有任何改变 , 而消极的(不利的)信息被压制 。 结果表明 , 该方法可以在不遗漏有益信息的情况下进行蒸馏 。 “
他们采用了partial L2 distance函数 , 目的是跳过对负区域信息的蒸馏 。 (如果该位置的学生和老师的特征向量都是负的 , 则没有损失)
Contrastive Representation Distillation发表于ICLR 2020 。 在这里 , 学生也从教师的中间表示进行学习 , 但不是通过MSE损失 , 他们使用了对比损失 。
总的来说 , 这些不同的模型采用了不同的方法
- 增加蒸馏中传递信息的量 。 (特征表示、Gram矩阵、注意力图、Paraphrased表示、pre-ReLU特征)
- 通过调整损失函数 , 使蒸馏过程更有效(对比损失 , partial L2 distance)
- KD的Gram矩阵 = Neural Style Transfer + KD
- KD的注意力图 = Attention is all you need + KD
- Paraphrased表示 KD = Autoencoder + KD
- Contrastive表示蒸馏 = InfoNCE + KD
- GANs for KD(即改变特征表示之间的GAN损失的对比损失)
- 弱监督KD(Self-Training with Noisy Student Improves ImageNet classification)
更多内容 , 请关注微信公众号“AI公园” 。
- 系统性学习Node.js(5)—手写 fs 核心方法
- Java基础知识回顾,还记得吗?
- 「技术」这样的思路,让控制器中按键处理数据的方法变得简单了
- Nginx服务器屏蔽与禁止屏蔽网络爬虫的方法
- 不需要负样本对的SOTA的自监督学习方法:BYOL
- 分析|用数据量化方法透视不确定性世界
- 原来微信自带扫描仪,学会这2个方法,纸质档一键电子化,很简单
- APP制作开发难不难?有简单快捷又省钱的方法吗?
- 电脑显示Windows即将过期,三种方法0技术激活win10
- #iPhone改图标#教程来咯