使用CatBoost和NODE建模表格数据对比测试
来自俄罗斯在线搜索公司Yandex的CatBoost快速且易于使用 , 但同一家公司的研究人员最近发布了一种基于神经网络的新软件包NODE , 声称其性能优于CatBoost和所有其他梯度增强方法 。这是真的吗? 让我们找出如何同时使用CatBoost和NODE!
该文章适用于谁?尽管我是为那些对机器学习特别是表格数据感兴趣的人写这篇博客的 , 但是如果您熟悉Python和scikit-learn库 , 并且希望跟随代码一起学习 , 对您很有帮助 。否则 , 希望您会发现理论和概念方面都很有趣!
CatBoost简介CatBoost是我建模表格数据的首选包 。 这是一个梯度增强决策树的实现 , 只是做了一些微调 , 使其与例如xgboost或LightGBM略有不同 。 它对分类和回归问题都有效 。
关于CatBoost的一些好处:
· 它处理分类特征(虽然不是最优解) , 所以你不需要担心如何编码它们 。
· 它通常只需要很少的参数调优 。
· 它避免了其他方法可能遭受的某些微妙类型的数据泄漏 。
· 它速度很快 , 如果你想让它跑得更快 , 可以在GPU上运行 。
这些因素使得CatBoost对我来说 , 当我需要分析一个新的表格数据集时 , 首先要做的就是使用它 。
CatBoost的技术细节如果你只是想使用CatBoost , 请跳过这一节!
在更技术的层面上 , 关于CatBoost的实现有一些有趣的事情 。 如果您对细节感兴趣 , 我强烈推荐论文Catboost: unbiased boosting with categorical features 。 我只想强调两件事 。
在论文中 , 作者指出 , 标准的梯度增强算法会受到一些微妙的数据泄漏的影响 , 这些泄漏是由模型的迭代拟合方式引起的 。 同样 , 最有效的对分类特征进行数字编码的方法(如目标编码)也容易出现数据泄漏和过拟合 。 为了避免这种泄漏 , CatBoost引入了一个人工时间轴 , 根据训练示例到达的时间轴 , 这样在计算统计数据时只能使用"以前看到的"示例 。
CatBoost实际上并不使用常规决策树 , 而是使用遗忘的决策树 。 在这些树中 , 在树的每一层上 , 相同的特性和相同的分割标准被到处使用!这听起来很奇怪 , 但有一些不错的属性 。 让我们看看这是什么意思 。
 文章插图
文章插图
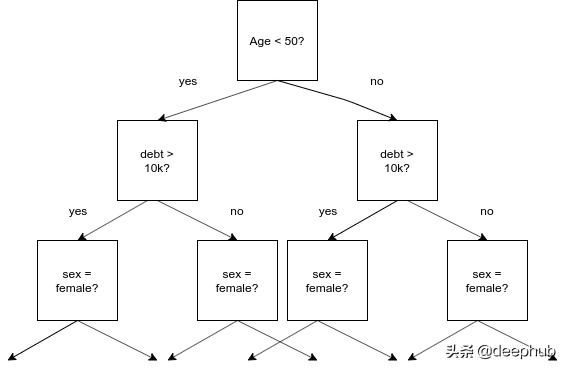
遗忘的决策树 。每个级别都有相同的拆分 。
 文章插图
文章插图
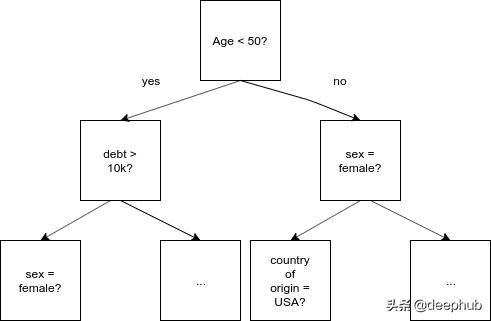
常规决策树 。每个级别上都可以存在任何功能或分割点 。
在普通的决策树中 , 要分割的特性和截止值都取决于到目前为止在树中所走的路径 。 这是有意义的 , 因为我们可以使用我们已经拥有的信息来决定最有意义的下一个问题 。 有了健忘决策树 , 历史就不重要了;我们无论如何都要提出同样的问题 。 这些树被称为"健忘的" , 因为它们总是"忘记"发生过的事情 。
为什么这个有用?健忘决策树的一个很好的特性是 , 一个例子可以非常快速地分类或得分——它总是提出相同的N个二叉问题(其中N是树的深度) 。 对于许多例子来说 , 这可以很容易地并行完成 。 这是CatBoost快速发展的原因之一 。 另一件要记住的事情是我们这里处理的是一个树集合 。 作为一种独立的算法 , 健忘决策树可能没有那么好 , 但树集合的思想是 , 由于错误和偏见被"洗掉" , 一个弱学习者的联盟经常工作得很好 。 通常情况下 , 弱学习者是一棵标准的决策树 , 而在这里 , 它甚至更弱 , 也就是健忘决策树 。 CatBoost的作者认为 , 这种特殊的弱学习者在泛化方面工作得很好 。
安装CatBoost安装CatBoost是非常简单的
pip install catboost
我在Mac上有时会遇到这样的问题 。 在Linux系统上 , 比如我现在输入的Ubuntu系统 , 或者在谷歌Colaboratory上 , 它应该"正常工作" 。 如果安装时一直有问题 , 可以考虑使用Docker镜像 。
- 系统性学习Node.js(5)—手写 fs 核心方法
- 使用半监督学习从研究到产品化的3个教训
- 企业建站使用服务器好还是虚拟主机好?
- 如何使用 lshw 查看 Linux 设备信息
- 低调使用!超级好用的ePub阅读工具!|PC软件
- 世界上第一台计算机是什么?为什么使用二进制而不是十进制?
- 网络安全:如何使用MSFPC半自动化生成强大的木码?「下集」
- 使用手机,体现着一个人的修养涵养
- 亲自使用一周,华为Mate20 Pro是否值得入手?
- ipad一直插电使用好吗?