点云分类的自动放大框架 PointAugment( 三 )
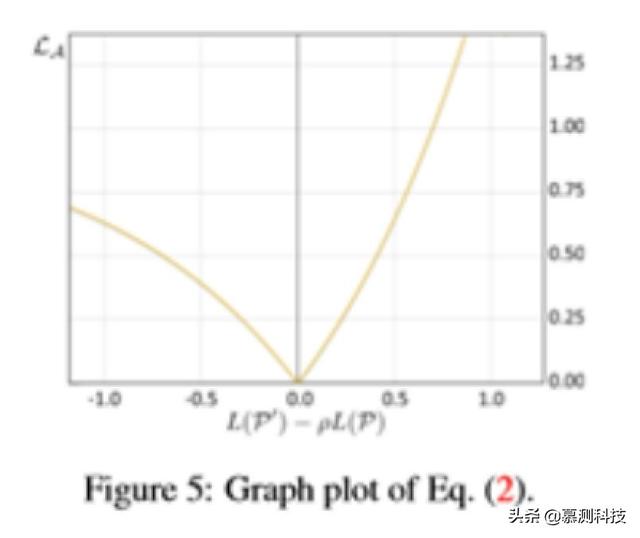
4.2. Augmentor loss为了使网络学习最大化 , 由放大器生成的放大样本 P′应满足两个要求:(i)P′比 P 更具挑战性 , 即目标是 L(P′)≥L(P);(ii)P′不应失去形状特异性 , 这意味着应该描述一个与 P 不太远(或不同)的形状 。 为了达到要求(i) , 一个简单的方法来描述放大器(表示为 LA)的损失函数是使 P 和 P′上的交叉熵损失之差最大化 , 或者等效地最小化 。
 文章插图
文章插图
4.3. Classi?er loss分类 C 的目标是正确预测 P 和 P′ 。 另外 , 无论输入 P 或 P′ , C 都应该具有学习稳定的每形状全局特征的能力 。
4.4. End-to-end training strategy算法 1 总结了端到端训练策略 。 总的来说 , 在训练过程中 , 该程序交替地优化和更新放大器 A 和分类器 C 中的可学习参数 , 同时调整另一个参数 。
4.5. Implementation details使用 PyTorch[21]实现 PointAugment 。 具体来说 , 将训练阶段的数量设为 S=250 , 批量大小为 B=24 。 为了训练放大器 , 采用了学习率为 0.001 的 Adam 优化器 。 为了训练分类人员 , 遵循发布的代码和文件中各自的原始配置 。 具体来说 , 对于 PointNet、PointNet++和 RSCNN , 使用的 Adam 优化器的初始学习率为 0.001 , 该值逐渐降低 , 每 20 个时期衰减率为 0.5 。
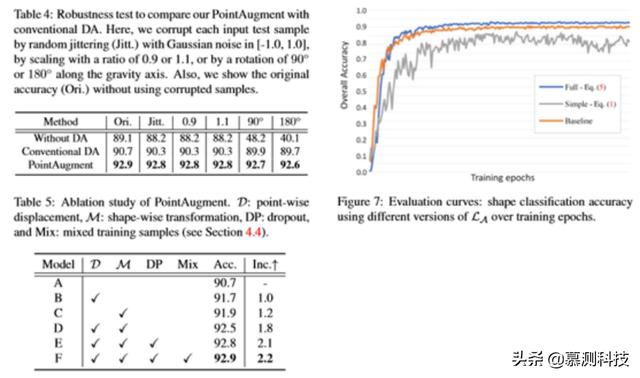
对于 DGCNN , 使用动量为 0.9、基本学习率为 0.1 的 SGD 解算器 , 该解算器使用余弦退火策略衰减[9] 。 还需要注意的是 , 为了减少模型振荡[5] , 遵循[31]使用混合训练样本来训练点放大 , 混合训练样本包含一半原始训练样本 , 另一半包含先前放大的样本 , 而不是只使用原始训练样本 。 详见[31] 。 此外 , 为了避免过度拟合 , 设置了 0.5 的脱落概率来随机丢弃或保持回归的形状方向变换和点方向位移 。 在测试阶段 , 遵循之前的网络[23 , 24] , 将输入的测试样本输入到经过训练的分类器 , 以获得预测的标签 , 而不需要任何额外的计算成本 。
 文章插图
文章插图
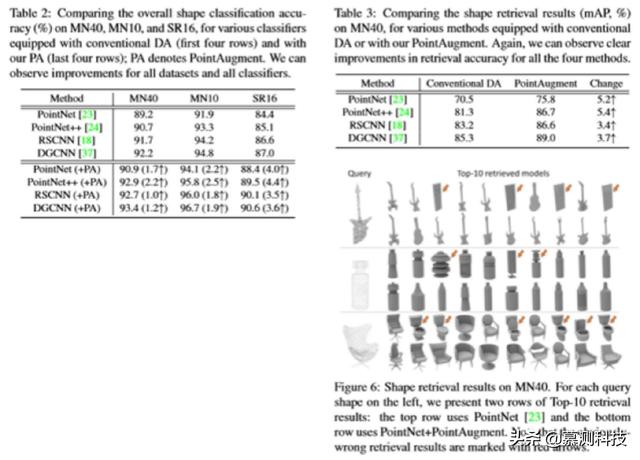
5. Experiments在点放大上做了大量的实验 。 首先 , 介绍了实验中使用的基准数据集和分类器 。 然后 , 在形状分类和形状检索方面评估 PointAugment 。 接下来 , 将对 PointAugment 的健壮性、损耗配置和模块化设计进行详细分析 。 最后 , 提出进一步的讨论和未来可能的扩展 。
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
致谢本论文由 iSE 实验室 2021 级学生王哲转述 。
- 原来华为手机是开会神器,60秒输出500字,一键自动记录
- 搭建自己的云签到平台,解放双手每日自动签到-超详细
- 网络安全:如何使用MSFPC半自动化生成强大的木码?「下集」
- 面向销售自动化的基于数据扩增和真实图像合成的鲁棒多目标检测
- 不怕恶劣天气的芯片要来了,或让自动驾驶汽车视野更广无盲点
- 特斯拉全自动驾驶新测试版本数天内发布
- IntelliJ IDEA 如何设置自动下载源代码和文档
- 开发好物推荐9之自动生成在线接口+文档-Knife4j
- 微信打开这个功能,手机秒变扫描仪,扫描文档自动识别
- 京东|京东探索稀疏三维空间点云Global Context学习方法获认可