「基础」奇异值分解的原理与应用( 三 )
运行这个示例 , 首先显示定义的矩阵 , 然后显示计算出的伪逆 。
 文章插图
文章插图
我们可以通过 SVD 采用人工的方式计算伪逆 , 并将结果与 pinv 函数的结果进行比较 。
首先我们必须计算 SVD 。 然后我们必须计算 s 数组中每个值的倒数 。 然后将这个 s 数组转换成一个对角矩阵 , 它额外增加了一行 0 以使其变成矩形形式 。 最后 , 我们可以根据这些元素计算伪逆 。
具体实现方式为:
 文章插图
文章插图
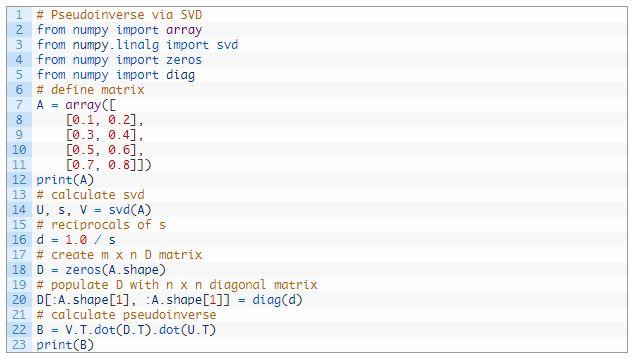
下面列出了完整的示例 。
 文章插图
文章插图
运行这个示例 , 首先显示定义的矩形矩阵 , 然后显示其伪逆 , 结果与上面 pinv 函数的结果一致 。
 文章插图
文章插图
用于降维的 SVD
SVD 的一大常见应用是降维 。
【「基础」奇异值分解的原理与应用】具有大量特征的数据(比如特征数(列数)多于观察数(行数))也许可以被归约成与所涉预测问题最相关的更小特征子集 。
其结果是一个秩更低的矩阵 , 据说接近原始矩阵 。
为了做到这一点 , 我们可以在原来的数据上执行一次 SVD 操作并选择 Sigma 中前 k 个最大的奇异值 。 这些列可以从 Sigma 中选择得到 , 行可以从 V^T 中选择得到 。
然后可以重建原始向量 A 的近似 B 。
 文章插图
文章插图
在自然语言处理中 , 这种方法可以被用在文档中词出现情况或词频的矩阵上 , 并被称为隐含语义分析(Latent Semantic Analysis)或隐含语义索引(Latent Semantic Indexing) 。
在实践中 , 我们可以保留和使用被称为 T 的描述性数据子集 。 这是矩阵的密集总结或投射 。
 文章插图
文章插图
此外 , 这种变换既可以在原来的矩阵 A 上计算和应用 , 也可以在其它类似的矩阵上计算和应用 。
 文章插图
文章插图
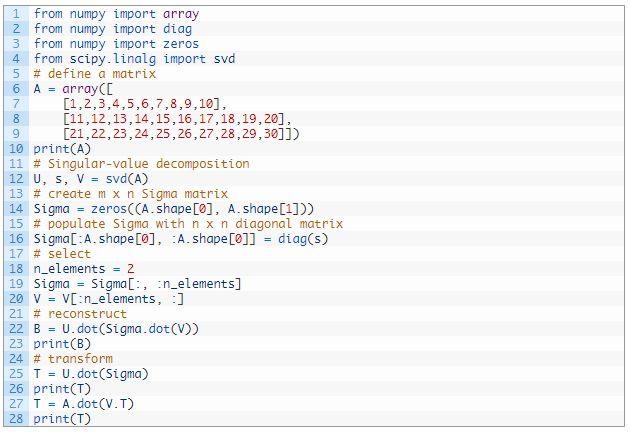
下面的示例是使用 SVD 的数据归约 。
首先定义一个 3×10 的矩阵 , 其列数多于行数 。 然后计算 SVD 并且只选取其前两个特征 。 这些元素再重新结合起来 , 得到原始矩阵的准确再现 。 最后计算转换的方式有两种 。
 文章插图
文章插图
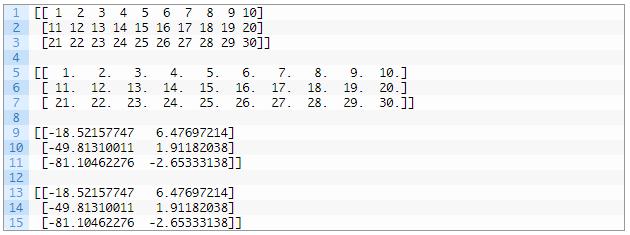
运行这个示例 , 首先显示定义的矩阵 , 然后是重建的近似矩阵 , 然后是原始矩阵的两个同样的变换结果 。
 文章插图
文章插图
scikit-learn 提供了直接实现这种功能的 TruncatedSVD 类 。
TruncatedSVD 的创建必须指定所需的特征数或所要选择的成分数 , 比如 2 。 一旦创建完成 , 你就可以通过调用 fit 函数来拟合该变换(比如:计算 V^Tk) , 然后再通过调用 transform 函数将其应用于原始矩阵 。 结果得到上面被称为 T 的 A 的变换 。
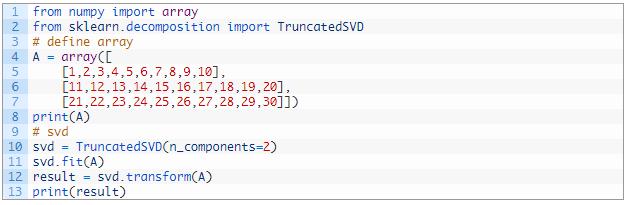
下面的示例演示了 TruncatedSVD 类 。
 文章插图
文章插图
运行这个示例 , 首先显示定义的矩阵 , 然后是该矩阵变换后的版本 。
- Java基础知识回顾,还记得吗?
- 零基础小白入门必看篇:学习Python之面对对象基础
- 大数据专业大一新生,只有数学等基础课程,还可以自学哪些内容
- 学习大数据需要具备哪些基础知识,以及应该重视哪些环节
- Linux基础入门vim常用命令详解
- 0基础大数据学习——加米谷大数据开发就业班开新班啦
- 瑞萨电子推出面向物联网基础设施系统的第二代多相数字控制器和智能功率级单元模块(SPS)
- 零基础想学好编程!C语言最难啃的3块硬骨头,你全吃透了吗?
- PyQt5基础开发(6)
- 菜鸟谈VBA最基础入门