打工四年总结的数据库知识点( 四 )
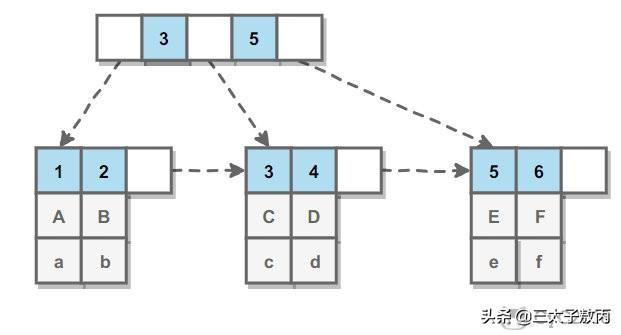 文章插图
文章插图辅助索引的叶子节点的 data 域记录着主键的值 , 因此在使用辅助索引进行查找时 , 需要先查找到主键值 , 然后再到主索引中进行查找 , 这个过程也被称作回表 。
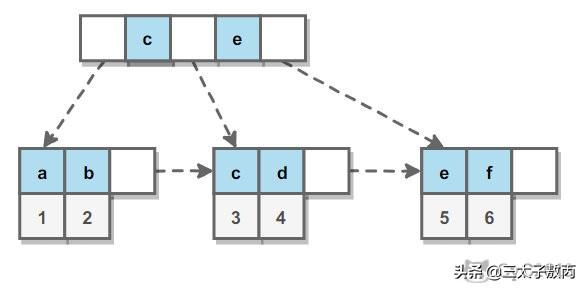 文章插图
文章插图哈希索引哈希索引能以 O(1) 时间进行查找 , 但是失去了有序性:
- 无法用于排序与分组;
- 只支持精确查找 , 无法用于部分查找和范围查找 。
全文索引MyISAM 存储引擎支持全文索引 , 用于查找文本中的关键词 , 而不是直接比较是否相等 。
查找条件使用 MATCH AGAINST , 而不是普通的 WHERE 。
全文索引使用倒排索引实现 , 它记录着关键词到其所在文档的映射 。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引 。
空间数据索引MyISAM 存储引擎支持空间数据索引(R-Tree) , 可以用于地理数据存储 。 空间数据索引会从所有维度来索引数据 , 可以有效地使用任意维度来进行组合查询 。
必须使用 GIS 相关的函数来维护数据 。
索引优化独立的列在进行查询时 , 索引列不能是表达式的一部分 , 也不能是函数的参数 , 否则无法使用索引 。
例如下面的查询不能使用 actor_id 列的索引:
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;多列索引在需要使用多个列作为条件进行查询时 , 使用多列索引比使用多个单列索引性能更好 。 例如下面的语句中 , 最好把 actor_id 和 film_id 设置为多列索引 。SELECT film_id, actor_ id FROM sakila.film_actorWHERE actor_id = 1 AND film_id = 1;索引列的顺序让选择性最强的索引列放在前面 。索引的选择性是指:不重复的索引值和记录总数的比值 。 最大值为 1 , 此时每个记录都有唯一的索引与其对应 。 选择性越高 , 每个记录的区分度越高 , 查询效率也越高 。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高 , 因此最好把 customer_id 列放在多列索引的前面 。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity,COUNT(*)FROM payment;staff_id_selectivity: 0.0001customer_id_selectivity: 0.0373COUNT(*): 16049前缀索引对于 BLOB、TEXT 和 VARCHAR 类型的列 , 必须使用前缀索引 , 只索引开始的部分字符 。前缀长度的选取需要根据索引选择性来确定 。
覆盖索引索引包含所有需要查询的字段的值 。
具有以下优点:
- 索引通常远小于数据行的大小 , 只读取索引能大大减少数据访问量 。
- 一些存储引擎(例如 MyISAM)在内存中只缓存索引 , 而数据依赖于操作系统来缓存 。 因此 , 只访问索引可以不使用系统调用(通常比较费时) 。
- 腾讯申请「打工鹅」商标,网友:“虾仁猪心”
- 库克靠打工实现1个亿“小目标”iPhone 12全球热销功不可没
- 支付宝打造的天价蚂蚁森林,四年时间过去了,现在长成什么样了?
- 没有人在意你的网易云年终总结
- 商标|腾讯申请打工鹅商标
- 资深打工人回血神器,荣泰RT6908S按摩椅评测
- 腾讯企鹅跟上“打工人”热潮!背后暗藏港股之王的成功秘诀
- 腾讯申请“打工鹅”商标
- 腾讯云交出阶段性年终总结,发布5G产品矩阵
- 小白财经|一图看懂5G毫米波