面向销售自动化的基于数据扩增和真实图像合成的鲁棒多目标检测( 四 )
4.2 实验装置训练数据集:本文讨论的所有训练图像合成方法都需要单个产品图像作为种子 。 我们使用 293 个产品作为种子合成训练图像 。 表 1 总结了每种方法的合成图像总数 。 对于非扩增方法 , 我们选取单个产品 , 并在不同的方向下捕捉图像 , 通常每个产品的方向从 5 到 7 个不等 。
 文章插图
文章插图
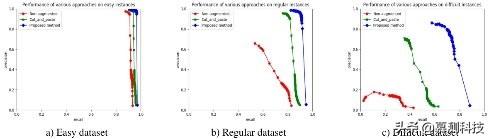
图 8 不同难度的测试数据集
 文章插图
文章插图
图 9 所提出的真实感图像合成方法中不同重叠指数值的 PR 曲线
 文章插图
文章插图
图 10 不同训练图像合成方法的 PR 曲线
测试数据集:测试数据集包含图 1 所示 POS 系统捕捉到的真实(非合成)图像 。 每个图像由多个不出现在训练数据集中的产品组成 。 我们根据产品之间的接近程度将数据集分为三组 , 难度各不相同:简单(总共 300 个图像)、常规(总共 600 个图像)和困难(总共 100 个图像) , 如图 8 所示 。 简单数据集包含的图像中 , 各个产品之间的距离相当大 。 常规数据集包含的图像中 , 单个产品放得很近 , 相邻产品之间有一点重叠 。 这个数据集代表了我们在使用 POS 系统时经常遇到的图像 。 困难的数据集包含图像 , 其中单个产品放置在尽可能低的距离 。 用于测试数据集的单个产品的总数是 153 。
4.3 结果和性能分析在这三个测试中 , 我们评估了各个方法的目标检测性能数据集 。 我们使用精确性 , 召回率 , 地面真实箱的平均重叠(AOGB)作为评估标准当预测边界框与背景真实边界框之间的 IoU 大于 0.5 时 , 预测被视为正确精度和召回率定义为 ,
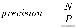 文章插图
文章插图
,
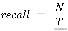 文章插图
文章插图
, 其中 N 是正确预测的数量 , P 是预测的总数 , 它是基本真实的总数实例 。 我们定义 AOGB 为经过正确预测的具有地面真实边界框的预测边界框的平均 IoU 。 我们选择更快的 RCNN 作为目标检测器 , 因为它在 MS-COCO 数据集上的性能最好 , 而 ResNet-101 作为特征提取器 , 学习率为 0.003 。 我们为表 1 中的所有方法分别对探测器进行了 200K 步的端到端训练 。
表 2 置信阈值为 0.8 时重叠指数不同值的性能
 文章插图
文章插图
表 3 置信阈值为 0.8 时不同训练图像合成方法的性能
 文章插图
文章插图
值得注意的是 , 对于 0.1 的高重叠指数 , 检测器的整体性能比简单的剪切粘贴方法和非扩增方法都要差 。 这是因为积极的合并会导致过度闭塞的训练实例 , 而使用我们的 POS 系统是不太可能遇到的 。 另一方面 , 如果我们将图像约束为不存在任何遮挡 , 则相对于剪切粘贴方法(表 2)我们获得了一个性能增益 , 但是对于遮挡和拥塞不够健壮 。 在我们的例子中 , 我们期望测试数据有拥塞 , 但不是完全阻塞 。 当我们在所有的图像中都有最优的阻塞指数时 , 也就是说 , 当我们在所有的图像中重叠时 , 我们也能达到最佳的阻塞指数 。
5 结论在这项工作中 , 我们提出了一种藉由合成真实训练影像的资料扩充方法 , 以使在拥挤的环境下能够进行稳健的零售商品侦测 , 以实现 POS 自动化 。 该方法包括两个关键步骤:精确的掩模提取和单个产品的合并 。 提出的掩模提取方法具有自动化程度高、精度高的特点接近 。 而且提出的产品合并方法通过重叠索引控制合成训练图像的分布 。 我们研究了重叠指数的影响 , 即产品放置的距离 。 我们的研究表明 , 通过选择重叠指数的最佳值 , 由该方法合成的图像训练出的目标检测器在拥塞情况下可以实现鲁棒检测 。 实验结果表明 , 与使用一幅图像一个产品的基本非扩增训练数据集相比 , 该方法的查准率和查全率分别提高了 46.2%(从 0.67 到 0.98)和 40%(从 0.60 到 0.84) 。
- Java基础知识回顾,还记得吗?
- 网络安全:如何使用MSFPC半自动化生成强大的木码?「下集」
- 报道称,华为可能很快将生产和销售汽车零部件,甚至造车
- 数据产品经理PRD—以阿里云会议产品为例(下)
- GitOps—通过CI/CD自动化构建虚拟机模版
- 人工智能如何彻底改变从IVR到销售辅导的商务电话
- 瑞萨电子推出面向物联网基础设施系统的第二代多相数字控制器和智能功率级单元模块(SPS)
- 「购买手机附送充电器」背后的经济学原理
- 特斯拉FSD升级价格降低1000美元:面向增强版Autopiolot车主
- Linux PC供应商ZaReason宣布关闭:销售Linux硬件已十多年