开启Scrapy爬虫之路!听说你scrapy都不会用?( 三 )
from ..items import CnblogspiderItemclass CnblogsSpider(scrapy.Spider):name = "cnblogs"# 爬虫的名称allowed_domains = ["cnblogs.com"]# 允许的域名start_urls = [""]def parse(self, response):# 实现网页解析# 首先抽取所有文章papers = response.xpath("//*[@class='day']")# 从每篇文章中抽取数据for paper in papers:url = paper.xpath(".//*[@class='postTitle']/a/@href").extract()[0]title = paper.xpath(".//*[@class='postTitle']/a/span/text()").extract()[0]time = paper.xpath(".//*[@class='dayTitle']/a/text()").extract()[0]content = paper.xpath(".//*[@class='postCon']/div/text()").extract()[0]# print(url, title, time, content)item = CnblogspiderItem(url=url, title=title, time=time, content=content)yield itemnext_page = Selector(response).re(u'下一页')if next_page:yield scrapy.Request(url=next_page[0], callback=self.parse)5.3定义item# Define here the models for your scraped items## See documentation in:# import scrapyclass CnblogspiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()url = scrapy.Field()time = scrapy.Field()title = scrapy.Field()content = scrapy.Field()class newCnblogsItem(CnblogspiderItem):body = scrapy.Field()# title = scrapy.Field(CnblogspiderItem.Fields['title'], serializer = my_serializer)5.4构建Item Pipeline# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: # useful for handling different item types with a single interfacefrom itemadapter import ItemAdapterimport jsonfrom scrapy.exceptions import DropItemfrom .items import CnblogspiderItemclass CnblogspiderPipeline(object):def __init__(self):self.file = open('papers.json', 'w', encoding='UTF-8')def process_item(self, item, spider):if item['title']:line = json.dumps(dict(item)) + '\n'# print(type(line))# self.file.write(line.encode())# 注意open "wb" 写入的是字节流 , “w”写入的是str# 使用decode 和 encode进行字节流和str的相互转化self.file.write(line)return itemelse:raise DropItem(f"Missing title in {item}")5.5 激活Item Pipeline定制完Item Pipeline ,它是无法工作的需要进行激活 , 要启用一个Item Pipeline组件必须将它的类添加到settings.py中的ITEM_PIPELINES 变量中自动创建的Scrapy直接把settings.py中的该行取消注释即可
TEM_PIPELINES 变量中可以配置很多个Item Pipeline组件 , 分配给每个类的整型值确定了他们的运行顺序 , item 按数字从低到高的顺序通过Item Pipeline , 取值范围0 ~1000
ITEM_PIPELINES = {'cnblogSpider.pipelines.CnblogspiderPipeline': 300,}激活完成后 , 将命令行切换到项目目录下执行scrapy crawl cnblogs1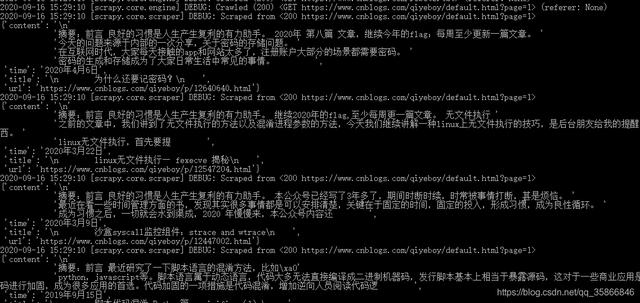 文章插图
文章插图此文转载文 , 著作权归作者所有 , 如有侵权联系小编删除!
原文地址:/article/details
完整项目代码获取视频教程后台私信小编01
- Nginx服务器屏蔽与禁止屏蔽网络爬虫的方法
- Python爬虫入门第一课:如何解析网页
- 阿里旗下云盘(teambition)公测通道开启
- 专栏丨当代“爬虫”现状
- 太火!华为Mate40 RS保时捷设计开启抽签购买模式
- 三大运营商开启清网战略,5G网络成本过高,只能壮士断腕
- 速抢!OPPO Find X2英雄联盟S10限定版开启预约
- 真旗舰?iGame Z490 VulcanX的科学开启指南
- 马云终于不再“仁慈”?开启全面收费,喜欢网购的一定要看
- 爬虫程序优化要点—附Python爬虫视频教程