在图上发送消息的神经网络MPNN简介和代码实现
欢迎来到图神经网络的世界 , 在这里我们在图上构建深度学习模型 。 你可以认为这很简单 。 毕竟 , 我们难道不能重用使用正常数据的模型吗?
 文章插图
文章插图
其实不是 。 在图中所有的数据点(节点)是相互连接的 。 这意味着数据不再是独立的 , 这使得大多数标准的机器学习模型毫无用处 , 因为它们的推导都强烈地基于这个假设 。 为了克服这个问题 , 可以从图中提取数字数据 , 或者使用直接对这类数据进行操作的模型 。
创建直接在图上工作的模型更为理想 , 因为我们可以获得更多关于图的结构和属性的信息 。 在本文中 , 我们将研究一种专门为此类数据设计的架构 , 即消息传递神经网络(MPNNs) 。
模型的各种变体 文章插图
文章插图
在将模型标准化为单个MPNN框架之前 , 几位独立研究人员已经发布了不同的变体 。这种类型的结构在化学中特别流行 , 可以帮助预测分子的性质 。
Duvenaud等人在2015年发表了有关该主题的第一批著作之一[1] 。他使用消息传递体系结构从图分子中提取有价值的信息 , 然后将其转换为单个特征向量 。当时 , 他的工作具有开创性 , 因为他使体系结构与众不同 。实际上是最早可以在图上运行的卷积神经网络体系结构之一 。
 文章插图
文章插图
Duvenaud等人创建的消息传递体系结构 。他将模型定义为可区分的层的堆栈 , 其中每一层是传递消息的另一轮 。修改自[1]
Li等人在2016年对此构架进行了另一尝试[2] 。在这里 , 他们专注于图的顺序输出 , 例如在图[2]中找到最佳路径 。为此 , 他们将GRU(门控循环单元)嵌入其算法中 。
尽管这些算法似乎完全不同 , 但是它们具有相同的基本概念 , 即消息在图中的节点之间传递 。我们将很快看到如何将这些模型组合成一个框架 。
将模型统一到MPNN框架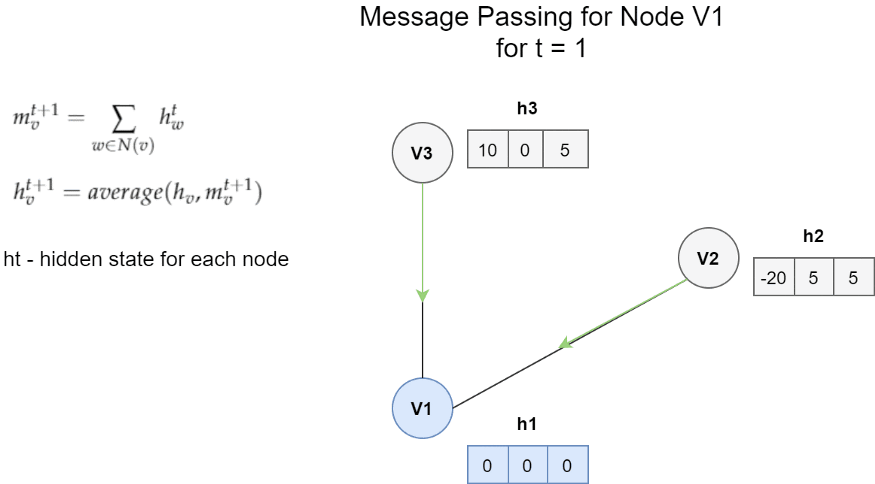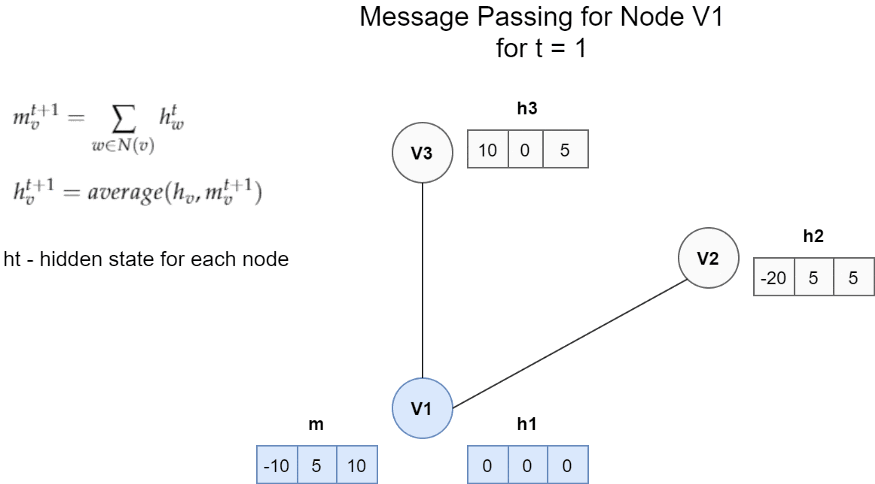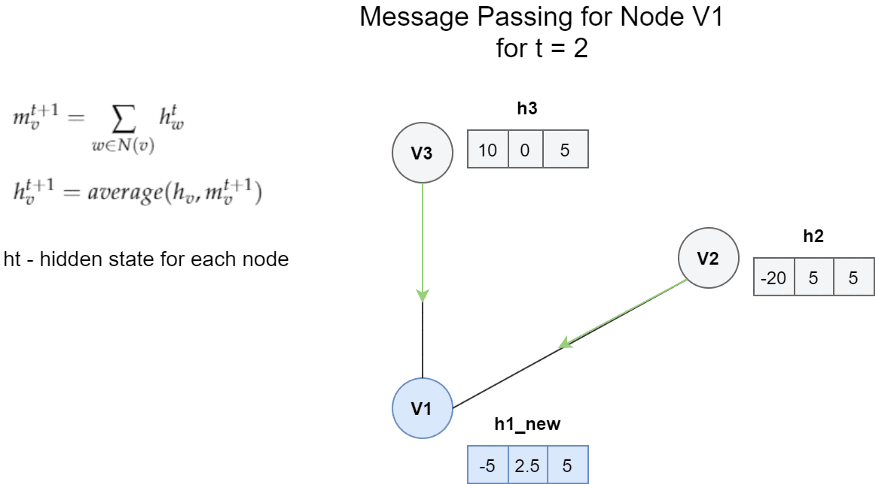 文章插图
文章插图
节点V1的消息传递体系结构的一个非常简单的示例 。在这种情况下 , 一条消息是邻居的隐藏状态的总和 。更新函数是消息m和h1之间的平均值 。
毕竟 , MPNN背后的想法在概念上很简单 。
图中的每个节点都具有隐藏状态(即特征向量) 。对于每个节点Vt , 我们将隐藏状态的函数以及所有相邻节点的边缘与节点Vt本身进行聚合 。然后 , 我们使用获得的消息和该节点的先前隐藏状态来更新节点Vt的隐藏状态 。
【在图上发送消息的神经网络MPNN简介和代码实现】有3个主要方程式定义图[3]上的MPNN框架 。从相邻节点获得的消息由以下公式给出:
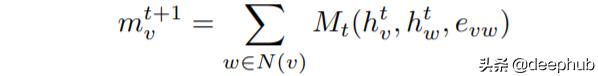 文章插图
文章插图
从邻居节点获取消息 。
它是从邻居获得的所有消息Mt的总和 。Mt是取决于隐藏状态和相邻节点边缘的任意函数 。我们可以通过保留一些输入参数来简化此功能 。在上面的示例中 , 我们仅求和不同的隐藏状态hw 。
然后 , 我们使用一个简单的方程式更新节点Vt的隐藏状态:
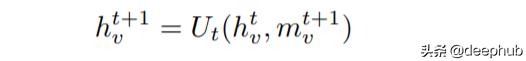 文章插图
文章插图
使用先前的隐藏状态和新消息更新节点的状态 。
简单地说 , 通过用新获得的消息mv更新旧的隐藏状态来获得节点Vt的隐藏状态 。在上述示例的情况下 , 更新函数Ut是先前隐藏状态和消息之间的平均值 。
我们将此消息传递算法重复指定的次数 。之后 , 我们进入最后的读出阶段 。
- 中芯蒋尚义正式发声!5句话点破半导体现状,对华为来说是好消息
- 苹果传出好消息,首发台积电新技术,苹果13性能有望全球第一
- 苹果CEO库克:明天将宣布重大消息 但不是新产品
- 消息称苹果曾试图收购电动汽车公司Canoo,但因分歧失败
- 恐怕有“好戏”看了!红米K40爆出新消息!或许不是骁龙888
- 曝小米MIX 4今年发布:屏下摄像头全面屏
- 被美国政府“拉黑”后,小米回应
- 消息称小米测试 80W 无线闪充:有望上半年量产商用
- “果粉”迎来惊喜,苹果iPhone13消息曝光,这才是想要的
- 8年前索尼手机可升级至Android 11