不需要负样本对的SOTA的自监督学习方法:BYOL( 三 )
接下来 , 我们想知道是否在投影MLP g、预测MLP q或两者中都需要batch normalization 。 我们的实验表明批batch normalization在投影MLP中是最有用的 , 但是网络可以通过batch normalization在任一MLP中学习到有用的表示 。 在MLPs中只需要一个batch normalization就足以让网络学习了 。
每种变化的性能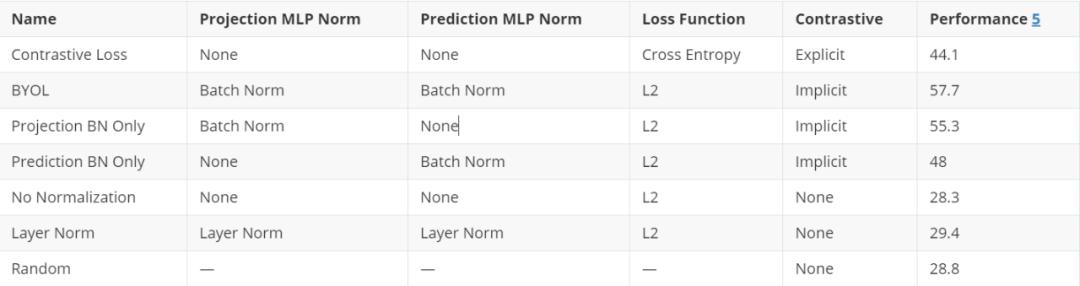 文章插图
文章插图
总结一下到目前为止的发现:在缺乏对比损失函数的情况下 , BYOL训练的成功取决于与minibatch中其他输入的激活相关的batch normalization层 。
为什么batch normalization对于BYOL这么重要:模式坍塌在对比损失函数中使用负样本的一个目的是防止模式坍塌 。 模式坍塌的一个例子是一个网络总是输出[1,0,0,0 , …]作为它的投影向量z 。 如果所有的投影向量z都相同 , 那么网络只需学习q的恒等函数就可以达到完美的预测精度!
batch normalization的重要性在此上下文中变得更加清晰 。 如果在投影层g中使用batch normalization , 那么投影输出向量z就无法坍缩成任何奇异值 , 如[1,0,0,0 , …] , 因为这正是batch normalization所避免的 。 无论如何相似的输入经过batch normalization , 输出将根据学习的平均值和标准偏差重新分配 。 这样就精准地防止了模式坍塌 , 因为在batch normalization , 所有的minibatch的样本无法取相同的值 。
batch normalization在预测MLP中可以产生类似的效果 。 如果minibatch的输入非常相似 , q函数就无法学习identity函数:batch normalization将通过向量空间重新分配激活 , 因此最后一层的预测都非常不同 。 如果这些向量z '在表示空间中被充分地分离(也就是说 , 没有坍塌) , 这个函数只会在预测投影向量z '时成功 , 因为预测的p被在minibatch中可以被很好地分离 。
为什么 batch normalization 是隐式对比学习:所有的样本都在和模式进行比较我们的发现似乎与一个简单的结论一致:防止模式坍塌的一种方法是识别样本之间的共同模式 。 batch normalization在minibatch之间标识这种共同的模式 , 并通过使用minibatch中的其他表示形式(如隐式负样本)来删除它 。 因此 , 我们可以把batch normalization看作是在嵌入式表示上实现对比学习的一种新方法 。
换句话说 , 通过batch normalization , BYOL通过提问来学习 , “这张图像与平均图像有什么不同?”SimCLR和MoCo使用的显式对比方法是这样学习的:“这两个特定图像之间的区别是什么?”这两种方法似乎是相同的 , 因为将一幅图像与许多其他图像进行比较 , 其效果与将它与其他图像的平均值进行比较是一样的 。 例如 , [prototypical contrastive learning]( -learning/)就利用了这种等价性 。
证实了我们的怀疑假设上述情况属实(删除batch normalization会导致BYOL模式坍塌) 。 在这种情况下 , 我们应该期望看到所有的表示和投影(z, z '和p向量)是相等的 —— 这就是我们所看到的 。
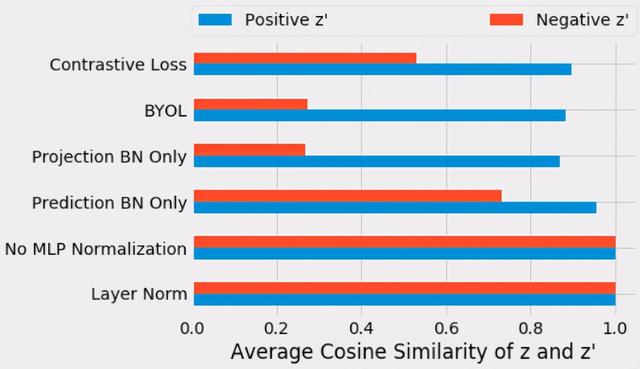
在训练了上述每个变量后 , 我们测量了第一个输入投影向量z与第二个输入投影向量z’的余弦相似度 。 在训练的第10个epochs , 我们测量了正样本投影(蓝色部分)与负样本投影(红色部分)之间的平均余弦相似度 。
在g或q中没有batch normalization , 投影与正样本和负样本高度对齐(0.9999) , 这表明将图像表示压缩为了同一个公共向量 。 因为batch normalization没有引入对比学习 , 它也导致了正样本的和负样本的对齐表示 。 对于标准的BYOL训练(即使用batch normalization) , 我们得到了预期的不同向量 。 正样本之间的投影(0.88)比负样本子之间的投影(0.27)更相似 。
 文章插图
文章插图
- 为什么苹果手机不需要“杀毒软件”?看完答案后,又涨知识了
- 中国手机市场没有绝对的“硬骨头”,苹果也要妥协,12又降价了
- 雷军签名版小米11曝光:绝对的理财产品
- 扫码枪将钱扫走,却不需要密码,安全吗?
- 松山湖科学城打造美好生活样本
- 下沉市场不需要巨头,但很需要社区团购
- 为何谷歌、脸书都热衷黑客马拉松?百度的选择或许是对的
- “朋友圈”寻人只需8小时,互联网需要正能量,不需要巨头卖菜
- leetcode哈希表之好数对的数目
- 毕亚兹Type-C拓展坞评测:不买贵的只买对的,四口足矣