GPU到底有多快?( 二 )
 文章插图
文章插图
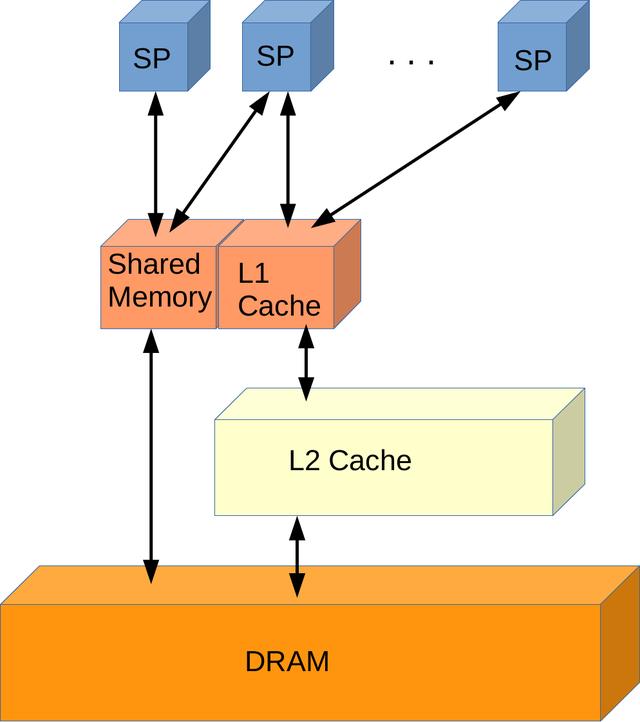
> Fermi Memory Hierarchy (Image by author)
开普勒架构开普勒包括多达15个SM和六个64位存储器控制器 。每个SM具有192个单精度CUDA内核 , 64个双精度单元 , 32个SFU , 32个LD / ST单元和16个纹理单元 。
 文章插图
文章插图
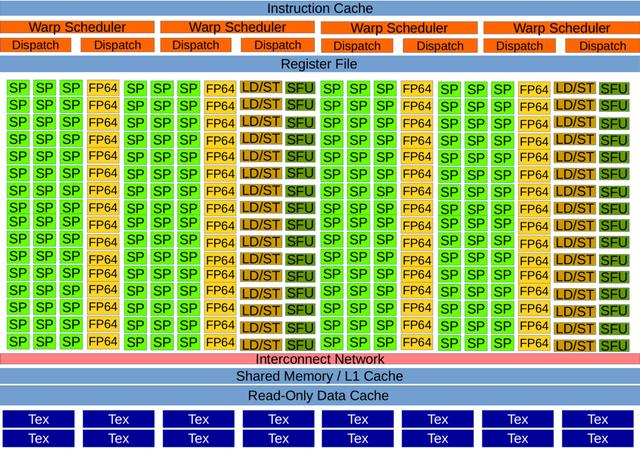
> Kepler Streaming Multiprocessor (Image by author)
另外 , 四个warp调度程序每个都有两个调度单元 , 它们允许同时发布和执行四个warp 。它还将每个线程访问的寄存器数量从Fermi中的63个增加到255个; 它引入了改组指令 , 并通过在全局内存中引入对FP64原子的本机支持来改进原子操作 。它还介绍了CUDA动态并行 , 即从内核启动内核的能力 。此外 , 内存层次结构与Fermi相似 。
 文章插图
文章插图
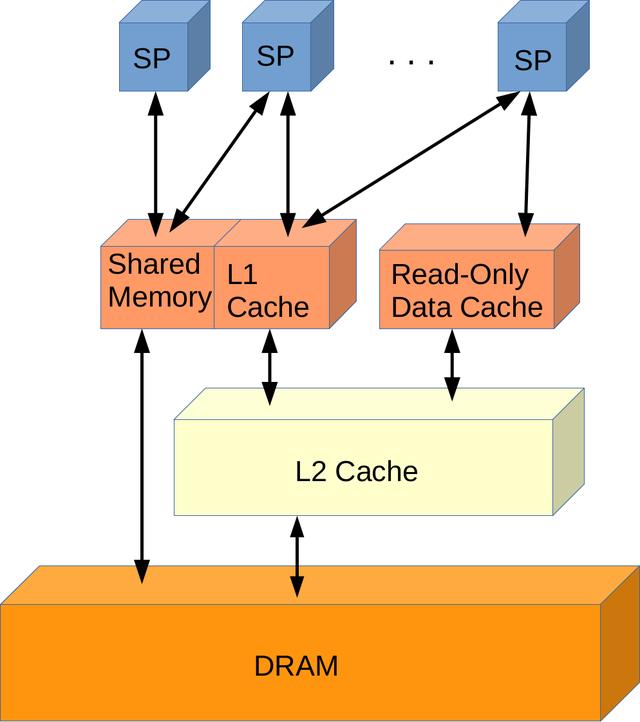
> Kepler Memory Hierarchy (Image by author)
通过允许在L1缓存和共享内存之间分割32 KB / 32 KB , 改进了64 KB共享内存/ L1缓存 。它还将共享内存库的宽度从Fermi中的32位增加到64位 , 并引入了48 KB只读数据缓存来缓存常量数据 。L2缓存也增加到1536 KB , 使Fermi L2缓存容量增加了一倍 。此外 , 开普勒计算功能由3.x代码表示 。
麦克斯韦架构Maxwell最多包含16个SM和四个内存控制器 。每个SM已重新配置以提高每瓦性能 。它包含四个Warp调度程序 , 每个调度程序每个时钟周期可以为每个warp调度两个指令 。SM分为四个32-CUDA核心处理模块 , 每个模块具有八个纹理单元 , 8个SFU和8个LD / ST单元 。
 文章插图
文章插图
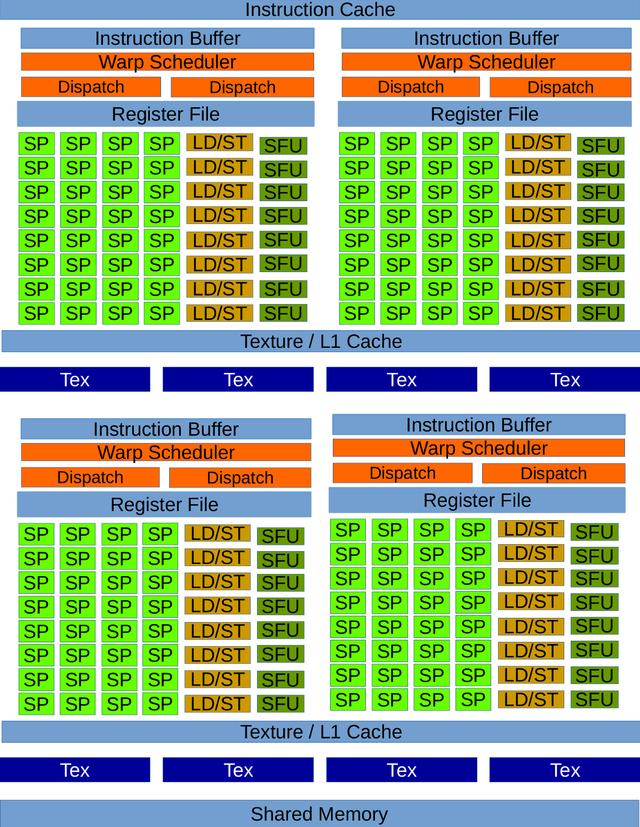
> Maxwell Streaming Multiprocessor (Image by author)
关于内存层次结构 , 它具有96 KB的专用共享内存(尽管每个线程块最多只能使用48 KB) , 而L1缓存与纹理缓存功能共享 。L2缓存提供2048 KB的容量 。内存带宽也增加了 , 从开普勒的192 GB /秒增加到了224 GB /秒 , 并且为共享内存中的FP32原子引入了本机支持 。Maxwell表示为计算能力5.x 。
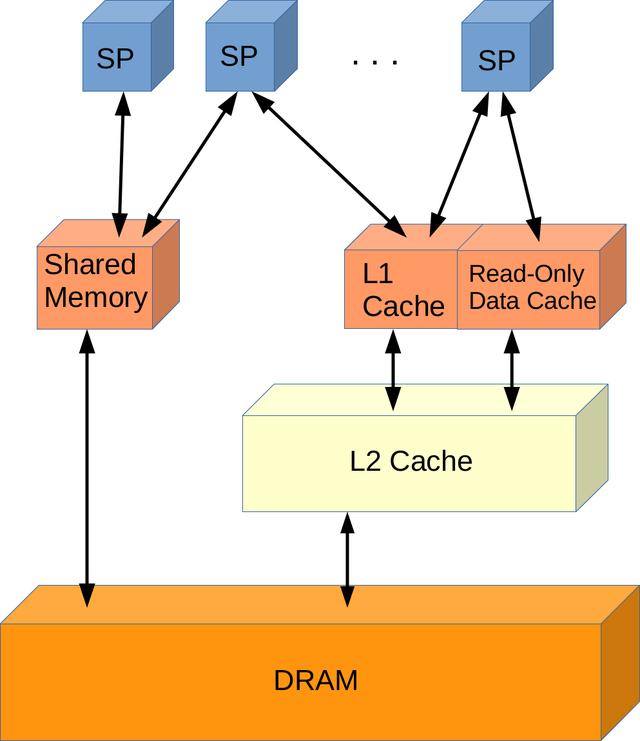 文章插图
文章插图
> Maxwell Memory Hierarchy (Image by author)
帕斯卡架构一个Pascal板由多达60个SM和8个512位存储器控制器组成 。每个SM具有64个CUDA核心和四个纹理单元 。它具有与Kepler和Maxwell相同数量的寄存器 , 但是提供了更多的SM , 因此总体上有更多的寄存器 。它被设计为支持比以前的体系结构更多的活动扭曲和线程块 。共享内存带宽加倍 , 以更高效地执行代码 。它允许加载/存储指令的重叠以增加浮点利用率 , 还改善了warp调度 , 其中每个warp调度程序都能够在每个时钟上调度两个warp指令 。CUDA内核能够处理16位和32位指令和数据 , 从而促进了深度学习程序的使用 , 而且还为数字程序提供了32个FP64 CUDA内核 。全局内存本机支持也已扩展为包括FP64原子 。
 文章插图
文章插图
> Pascal Streaming Multiprocessor (Image by author)
内存层次结构配置也已更改 。每个内存控制器都连接到512 KB的L2缓存 , 提供4096 KB的L2缓存 , 并引入了HBM2内存 , 提供了732 GB / s的带宽 。它为每个SM提供64 KB的共享内存 , 以及一个L1高速缓存 , 该L1高速缓存也可以用作纹理高速缓存 , 该纹理高速缓存用作合并缓冲区以增加扭曲数据的局部性 。它的计算能力由6.x代码表示 。
- AMD 专利展现 MCM 模块化芯片设计,GPU 将采用多核封装
- Sonnet更新便携式eGPU Breakaway Puck系列产品线
- “滑向2022”新浪杯高山滑雪公开赛,与华为WATCH GT2 Pro一起雪战到底
- 英特尔Xe GPU在Linux 5.11上的性能表现不错
- 一文读懂,书架箱和落地箱到底哪个好?
- Win10 真的要兼容安卓 App 了,微软到底想玩什么
- 全球移动网速比拼:美国63兆,韩国166兆,中国网速有多快?
- 20款游戏实战!酷睿i7-10750H、锐龙9 4900H到底谁更强?
- 手机出现“自动更新”,到底要不要更新?答案已确认
- 华硕和宏碁即将推出发烧级笔电 采用AMD Zen 3 移动处理器和NVIDIA 3080 GPU