ML 流水线涉及许多方面,从训练和执行模型的硬件,到 ML 架构的各个组件,都可以进行效率优化,同时保持或提高整体性能。
与前几年相比,这些线程中的每一个都可以以显著的乘法因子提高效率,并且综合起来可以将计算成本(包括二氧化碳当量排放量)降低几个数量级。
更高的效率促成了许多关键的进步,这些进步将继续显著提高机器学习的效率,使更大、更高质量的机器学习模型能够以高效的方式开发,并进一步使访问公平化。
ML 加速器性能的持续改进
每一代 ML 加速器都在前几代的基础上进行了改进,使每个芯片的性能更快,并且通常可以扩大整个系统的规模。
去年,谷歌发布了其TPUv4 系统,这是谷歌的第四代张量处理单元,它在 MLPerf 基准测试中比 TPUv3 提升了 2.7 倍。TPUv4 芯片的峰值性能是 TPUv3 芯片的约 2 倍,每个 TPUv4 pod 的规模为 4096 个芯片(是 TPUv3 pod 的 4 倍),每个 pod 的性能约为 1.1 exaflops(而每个 TPUv3 pod约为 100 petaflops)。拥有大量芯片并通过高速网络连接在一起的 Pod 可以提高大型模型的效率。
此外,移动设备上的机器学习能力也在显着提高。Pixel 6 手机采用全新的 Google Tensor 处理器,该处理器集成了强大的 ML 加速器,以更好地支持重要的设备功能。

文章插图
左:TPUv4 主板;中:TPUv4 pod的一部分;右图:在 Pixel 6 手机中的 Google Tensor 芯片。
Jeff Dean表示,谷歌使用 ML 来加速各种计算机芯片的设计也带来了好处,特别是在生产更好的 ML 加速器方面。
ML 编译和 ML 工作负载优化的持续改进
即使硬件不变,编译器的改进和机器学习加速器系统软件的其他优化也可以显著提高效率。
例如,“A Flexible Approach to Autotuning Multi-pass Machine Learning Compilers”展示了如何使用机器学习来执行编译设置的自动调整,用于同一底层硬件上的一套 ML 程序,以获得 5-15% 的全面性能提升(有时甚至高达2.4 倍改进)。
此外,GSPMD 描述了一种基于 XLA 编译器的自动并行化系统,该系统能够将大多数深度学习网络架构扩展到加速器的内存容量之外,并已应用于许多大型模型,例如 GShard-M4、LaMDA、BigSSL、ViT、MetNet -2 和 GLaM,在多个领域产生了最先进的成果。
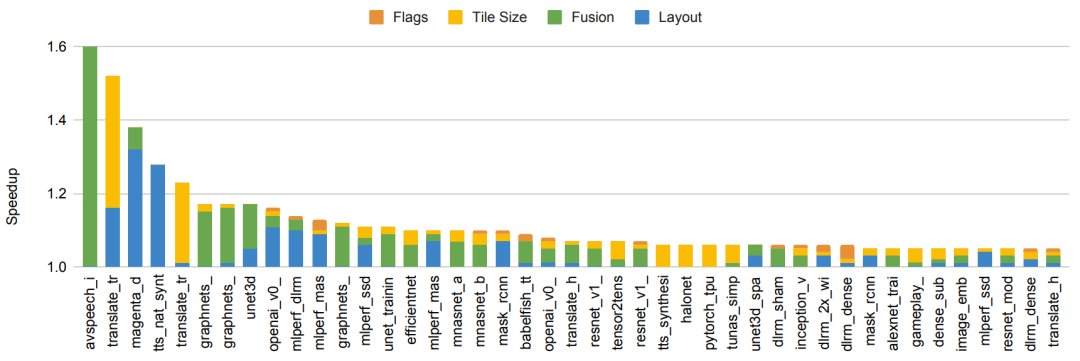
文章插图
图注:通过在 150 个 ML 模型上使用基于 ML 的编译器自动调整实现端到端模型加速。图中包括实现 5% 或更多改进的模型。条形颜色代表优化不同模型组件的相对改进。
人类创造的更高效模型架构
【 Jeff De2021谷歌年度 Jeff】模型架构的持续改进大大减少了为许多问题实现给定精度水平所需的计算量。
例如,谷歌在 2017 年开发的 Transformer 架构能够提高在多个 NLP 基准上的当前最佳水平,同时使用比其他各种常用方法少 10 到 100 倍的计算来实现这些结果,例如 LSTM 和其他循环架构。
同样,尽管使用的计算量比卷积神经网络少 4 到 10 倍,但视觉 Transformer 能够在许多不同的图像分类任务上显示出改善的最先进结果。
机器驱动的更高效模型架构的发现
神经架构搜索(NAS)可以自动发现对给定问题域更有效的新 ML 架构。NAS 的一个主要优点是它可以大大减少算法开发所需的工作量,因为 NAS 只需要对每个搜索空间和问题域组合进行单次检验。
此外,虽然执行 NAS 的初始工作在计算上可能很昂贵,但由此产生的模型可以大大减少下游研究和生产设置中的计算,从而大大降低总体资源需求。
例如,发现 Evolved Transformer 的单次搜索仅产生了 3.2 吨二氧化碳当量(远低于其他地方报告的 284 吨二氧化碳当量),但产生了一个比普通的 Transformer 模型效率高 15-20%的模型。
最近,谷歌利用 NAS 发现了一种更高效的架构,称为 Primer(也已开源),与普通的 Transformer 模型相比,它可以将训练成本降低 4 倍。通过这种方式,NAS 搜索的发现成本通常可以从使用发现的更有效的模型架构中收回,即使它们仅应用于少数下游任务(NAS 结果可被重复使用数千次)。
文章插图
- 安卓|谷歌发布Android 13开发者预览版,首批适配多款谷歌手机
- Google|先有谷歌后有脸书,傲慢正在一步步瓦解美国的优势,将加速其衰落
- pi|安卓13来了!谷歌Android 13首个开发者预览版发布
- iPad|谷歌为iPad用户操碎了心
- cm英国批准谷歌淘汰Cookie计划:已消除竞争担忧
- 自动驾驶|马斯克要开放自动驾驶给所有车企使用,和谷歌开源安卓然后断供华为是一个道理
- Google|为让安卓机与苹果一样流畅,ARM替谷歌出手,做了回“恶人”
- 安卓|ARM、谷歌一起动手,落后5年后,安卓机终于要跟上苹果步伐了
- 安卓谷歌正在开发单独的 UWB API,允许第三方安卓 App 使用
- Sidney|谷歌5号员工Ray Sidney否认是谷爱凌生父