文章插图
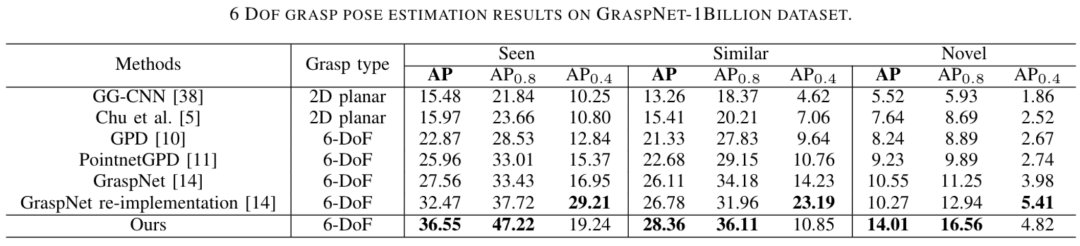
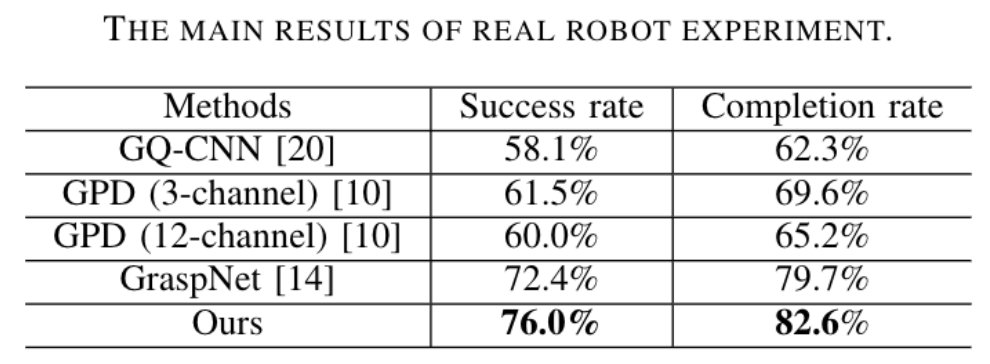
图 5 GraspNet-1Billion数据集实验结果同时作者使用Kinova Jaco2机器人及Realsense在真实场景中进行评测,同样优于 Baseline 方法:
文章插图
这篇工作将杂乱场景下的机器人抓取问题分为实例分割、抓取姿态估计及碰撞检测三个子任务并进行联合优化学习。实验表明,算法能够在杂乱场景中准确地估计出物体级别、无碰撞的六自由度抓取姿态,达到业界领先水平。[1] Fang, Hao-Shu, et al. "Graspnet-1billion: A large-scale benchmark for general object grasping."Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.[2] Qin, Yuzhe, et al. "S4g: Amodal single-view single-shot se (3) grasp detection in cluttered scenes." Conference on robot learning. PMLR, 2020.[3] Ten Pas, Andreas, et al. "Grasp pose detection in point clouds." The International Journal of Robotics Research 36.13-14 (2017): 1455-1473.[4] De Brabandere, Bert, Davy Neven, and Luc Van Gool. "Semantic instance segmentation with a discriminative loss function." arXiv preprint arXiv:1708.02551 (2017).

文章插图
雷锋网雷锋网雷锋网