基于注意力的多行人属性识别的深度学习模型
论文题目《An Attention-Based Deep Learning Model for Multiple Pedestrian Attributes Recognition 》
链接:
【基于注意力的多行人属性识别的深度学习模型】作者单位:清华大学
年份:2020
1. 论文主要解决什么问题?行人属性预测是一个多任务学习问题 。 为了共享特征表达 , 传统的多任务学习方法通常学习特征或者特征子空间的线性组合 。 但是这种组合排除了通道之间的复杂的相互依赖性 。 更何况 , 空间信息交换也很少被考虑 。 论文提出了协同注意力共享(CAS)模型来提取具有判断力的通道和空间区域 , 以便在多任务学习中很好地共享特征 。
说人话:以前多任务的方法真弱鸡 , 很多都只是把特征简单相加 , 不考虑特征通道信息依赖性和空间信息的交互?
2. 论文如何解决问题?行人属性分类方法中 , 常用的网络结构如如图1所示: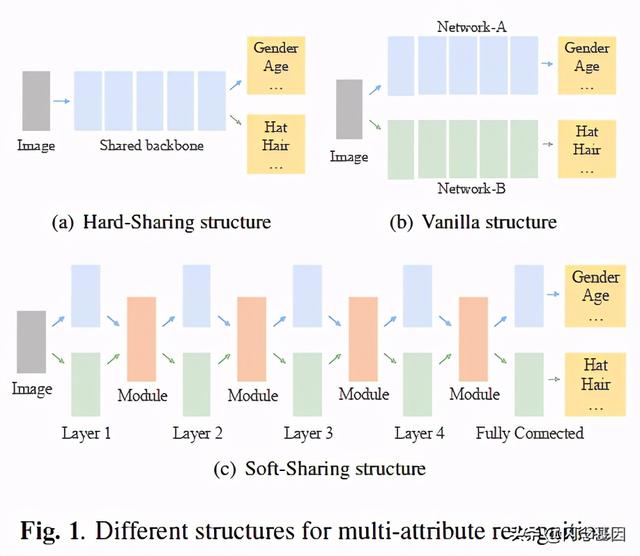 文章插图
文章插图
- Hard-Sharing 结构 , 但是可能容易产生负转移问题 , 也就是说对一个某个行人属性进行预测的时候可能容易被其他属性所影响 。
- Vanilla 结构 , 它集成了两个独立的网络结构 , 分别负责预测不同的属性 。 联系紧密的属性就分成同一个组 , 由同一个网络负责 。 但是两个网络之间没有任何的交互 , 一些有用的相关信息可能没有被利用起来 。
- Soft-Sharing 结构 , 集成Hard-Sharing 和Vanilla 结构的优点 , 每一层利用一个模块来决定哪些特征该共享哪些不该共享 。
作者提出的CAS模型如图2所示:
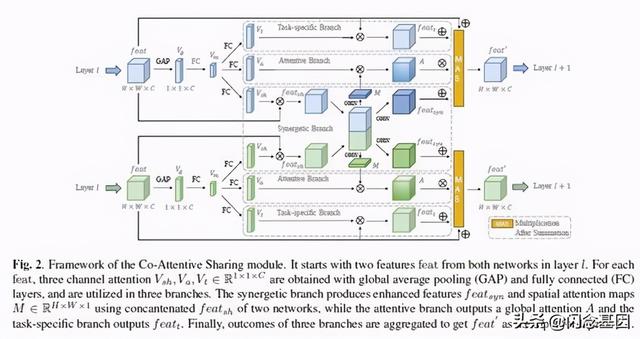 文章插图
文章插图这一种Soft-Sharing 结构 , 由两个网络及其中间的交互模块组成 。 上下两个网络结构是一致的 , 输入特征$ feat $ 经过GAP(全局平均池化)得到$V_g$ , 然后把$V_g$“喂入”全连接层便可得到中间向量$V_m$ 。
- 协同分支(Synergetic Branch):该分支的输入为$V_{sh}$ , 它由上面的网络$A$和下面的网络$B$的中间向量$V_m$经过全连接层得到的结果 。 $V_{sh} $与该层的$feat$进行$element-wise$相乘操作 , 结果分别记为$feat^A$和$feat^{B}$ 。 然后对$feat^A_{sh}$和$feat^{B}_{sh}$进行通道接拼 , 得到$feat_{cat}$ 。 然后$concat(Avg(feat_{cat}),Max(feat_{cat}))$ , 对其结果进行卷积操作 , 结果记为$M$ 。 其中$Avg$和$Max$分别是通道上的平均值和最大值函数 。 $feat_{cat}$经过卷积得到$feat_{sym}$ 。 协同分支的输出便是$M$和$feat_{sym}$了 。 其中$M$将会被送入到注意力分支 。
- 注意力分支(Attentive Branch):该分支的输入为$V_a$ , 它由$V_m$经过全连接层所得到 。 然后$V_a$与协同分支的输出$M$进行$element-wise$相乘 , 其结果记为$A$ 。
- 任务分支(Task-specific Branch):该分支的输入为$V_t$ , 它也是由$V_m$经过全连接层所得到 。 然后$V_a$与该层的$feat$进行$element-wise$相乘 , 其结果记为$feat_t$ 。
- 分支聚合:$feat$ , $feat_{sym}$和$feat_t$进行$element-eise$的相加,其结果与$A$进行$element-wise$相乘 。 得到的结果将"喂入"下一层网络 。
- 结果超过了传统共享单元的方法 , 与SOTA的相比 , 也达到了更好的结果 。
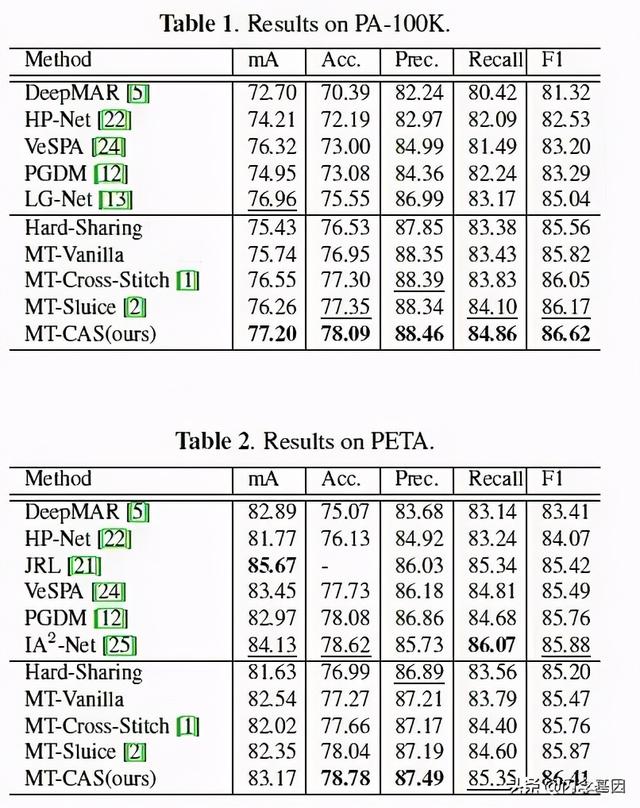 文章插图
文章插图4.对我们有什么指导意义?
- 多任务学习中 , Soft-Sharing 结构优于Hard-Sharing 结构和Vanilla 结构 。
- 空间信息对于行人属性识别还是很重要的 , 对特征$element-wize$相加操作可能不太有利用提取空间区域信息 , 但是concat操作应该还是有用的 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面