按关键词阅读:
 文章插图
文章插图
清源 CPM 能够在无监督的设定下达到比随机预测好得多的精确度(TNEWS/IFLYTEK/OCNLI 随机预测精确度分别为 0.25/0.25/0.33) 。
自动问答
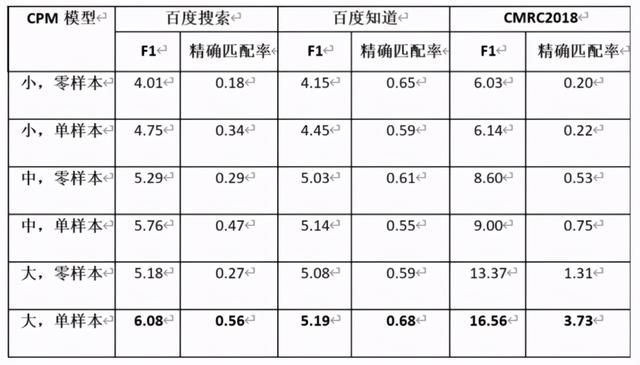
CPM 使用 DuReader 和 CMRC2018 作为自动问答任务的基准 , 要求模型从给定段落中抽取一个片段作为对题目问题的答案 , 其中 DuReader 由百度搜索和百度知道两部分数据组成 。 在无监督的设定下 , 不同规模的 CPM 模型的表现如下表所示:
 文章插图
文章插图
其中单样本是指在测试时 , 从数据集中随机抽取一个正确的「(段落 , 问题 , 答案)」三元组 , 插入到用于评价的样例前 , 作为 CPM 模型生成答案的提示;零样本是指直接使用 CPM 模型预测给定段落和问题的答案 。 在单样本设定下 , CPM 能从给定的样本中学习到生成答案的模式 , 因此效果总是比零样本设定更好 。 由于模型的输入长度有限 , 多样本输入的场景将在未来进行探索 。
模型效果展示
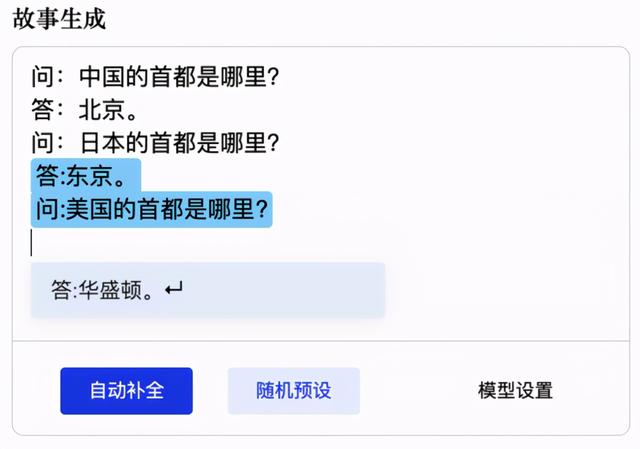
我们可以从以下示例中 , 观察 CPM 预训练中文语言模型的效果 。 比如基于对单个常识性问题的学习 , 依照规律进行提问和正确回答:
 文章插图
文章插图
根据前文真实的天气预报 , 继续报道天气预报(不保证正确性):
 文章插图
文章插图
执行数理推理:
 文章插图
文章插图
甚至续写《红楼梦》片段:
 文章插图
文章插图
据了解 , 清源 CPM 未来计划开源发布更大规模的预训练中文语言模型、以中文为核心的多语言预训练模型、融合大规模知识的预训练语言模型等 。
![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2P452020.html
标题:26亿参数,智源、清华开源中文大规模预训练模型( 二 )