Kylin 在贝壳的性能挑战和 HBase 优化实践( 二 )
RegionServer IO瓶颈1)现象我们发现在构建早高峰时 , HBase响应时间的P99会随之升高的 , 通过监控发现是由于 RegionServer机器的IO Wait偏高导致的 。
【Kylin 在贝壳的性能挑战和 HBase 优化实践】还有一种场景是用户构建时间范围选择过大 , 导致网卡被打满 , 之前有个用户构建了一年的数据 , 还有构建三四个月数据 , 这两种情况都会造成RegionServer机器IO出现瓶颈导致Kylin查询超时 。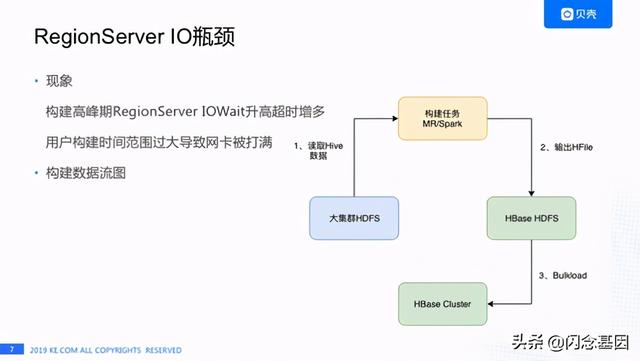 文章插图
文章插图
上图是Cube数据构建流程 , 首先HBase集群和公司大的Hadoop集群是独立的两套HDFS集群 , 每天构建是从大集群的HDFS去读取Hive的数据 , 构建任务直接输出HFile到HBase的HDFS集群 , 最后执行Bulkload操作 。 由于HBase HDFS集群机器较少 , 构建任务写数据过快导致DataNode/RegionServer机器IO Wait升高 , 怎么解决这个问题呢?
2)解决方案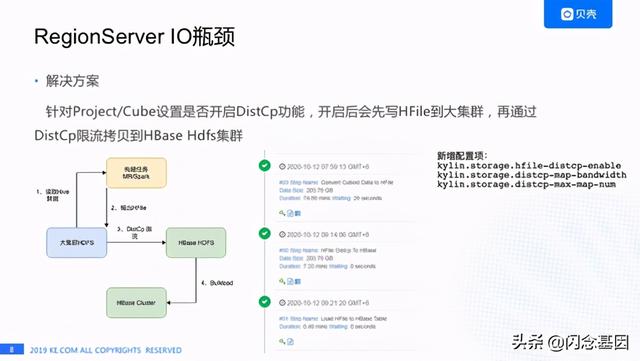 文章插图
文章插图
我们想用HBase比较常用的方式就是DistCp来 解决这个问题, 左下角这张图是我们的改进方案 , 就是我们设置构建任务的输出路径到Hadoop的大集群 , 而不是到HBase的HDFSB及群 , 再通过DistCp限流的拷贝HFile到HBase的HDFS集群 , 最后做Bulkload操作 。 之前提到我们有800多个Cube , 并不是所有的Cube都需要走这套流程 ,因为限流拷贝的话肯定会影响数据的产出时间 , 我们设计了针对Project或者是Cube设置开启这个功能 ,我们通常会对数据量比较大的Cube开启DistCp限流拷贝 , 其他Cube还是使用之前的数据流程 。
中间这个图是一个构建任务的截图 , 第一步是生成HFile , 第二步是DistCp , 最后再Bulkload , 这个功能我们新增了一些配置项 , 比如说第一个是否开启DictCp , 第二个是每个Map带宽是多少 , 再有就是最大有多少Map 。 通过这个功能我们基本上解决了构建高峰IOWait会变高的情况 。
慢查询治理–超时定位链路优化1)现象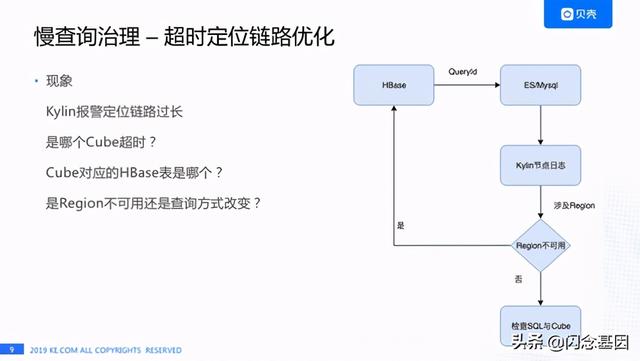 文章插图
文章插图
慢查询治理遇到的第一个问题就是超时定位链路特别长 。 我们收到Kylin报警时首先会想知道:
- 是哪个Cube超时了?
- Cube对应的HBase表是哪个?
- 是Region不可用还是查询方式变了?
2)解决方案
 文章插图
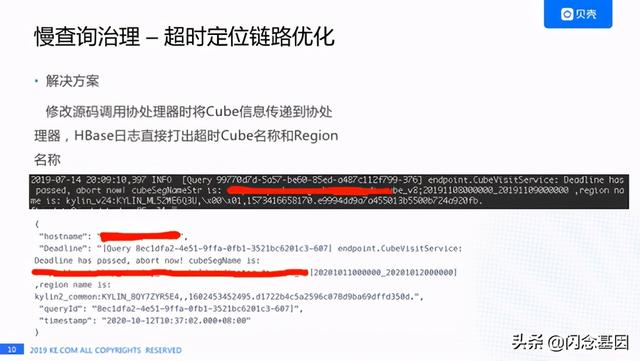
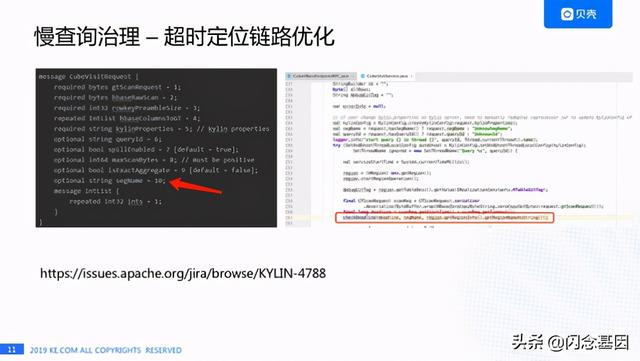
文章插图针对这个痛点给我们做了如下改进:我们直接把Cube信息和Region的信息打在HBase的日志里 。 中间这个黑色的部分就是HBase的日志 , 我们可以看到这个查询已经终止了 , Cube的名字是什么 , Region的名字是什么 , 下面的白色部分是通过天眼系统配置的报警信息 , 这个报警是直接报到企业微信的 , 我们能马上知道这个Deadline涉及的Cube和Region , 能马上做一个检测是这个表不可用了还是查询方式改变了 , 大大节省了定位问题的时间 。
 文章插图
文章插图这个是为了解决超时链路过长我们对Kylin做的一些代码改动 , 首先我们在Protobuf文件中加了一个segmentName字段 , 然后在协处理器类中获取了Region名字 , 在协处理器调用checkDeadLine方法检查时传入segmentName和regionName , 最后日志会打印出来segment名称和Region的信息 。这个功能已经反馈给社区了 , 见:
慢查询治理-队列堆积定位1)现象
 文章插图
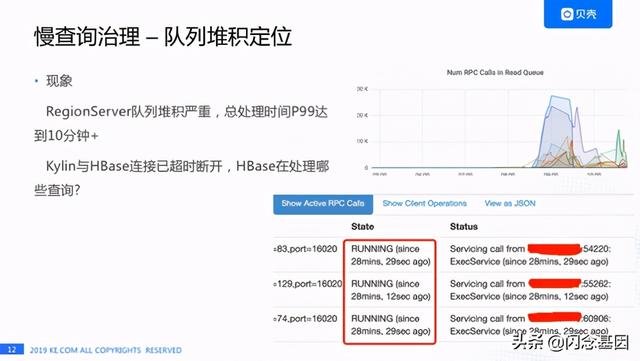
文章插图有一天我们发现Kylin HBase RegionServer队列堆积非常严重 , RegionServer的P99的响应时间已经达到了10多分钟的级别 , 大家看右上角是HBase关于队列的监控情况 , 一些机器的堆积已将近3W 。 我们当时非常疑惑 , 因为Kylin和HBase之间RPC的超时时间是10秒 , 在10秒之后Kylin和HBase的连接都已经断开了 , HBase到底处理什么查询 , 右下角是HBase RegionServer UI页面的截图 , 在这个截图里我们发现一些查询其实已经执行了快半个小时了 , 这半个小时是在执行什么呢?
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 行业|现在行业内客服托管费用是怎么算的
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 看过明年的iPhone之后,现在下手的都哭了