从入门到掉坑:Go 内存池/对象池技术介绍(含GroupCache详解)( 三 )
3. BigCache相比分布式场景的 GroupCache , 如果你本地依然有千万级的 keys , 那推荐你用 bigcache 。 无数经验证明 , 超大 map 的内存池导致的 GC 延迟 , 是可以通过切 bigcache 解决的 。 那 bigcache 到底怎么做到的?
简单来说:shards map + map[uint]uint + []byte + free link = BigCache
- 定义 shards cache , 避免锁粒度过大
- map 里只存放 uint 避免指针
- 实现一个 queue 结构(实际是[]byte , 通过 uint 下标追加分配)
- 采用 free 链机制 , 删除保留空洞最后一起回收(这块逻辑还蛮复杂的 , 先留个不大不小的坑吧...)
type cacheShard struct {hashmapmap[uint64]uint32// key在entries中的位置entriesqueue.BytesQueue// 实际是[]byte , 新数据来了后copy到尾部}这样 GC 就变成了map 无指针+[]byte 结构的扫描问题了 , 因此性能会高出很多 。坑 4: 两种方式(GroupCache 和 BigCache)对具体业务到底有多大影响?上面只是 map 实现内存池的模拟分析 , 以及两种典型 Cache 库的对比 。 如果你也和我一样 , 问自己“具体两种 Cache 对业务有多大影响呢”?那只能很高兴的对你说:欢迎来到坑底 -_-
我们线上大概需要单机缓存 1000 万左右的 keys 。 首先我尝试模拟业务 , 向两种 Cache 中插入 1000w 数据来测试 GC 停顿 。 然而因为实验代码或其他未知的坑 , 最后认为这个方法不太可侧
最后讨论 , 觉得还是用老办法 , 用 Prometheus 的 histogram 统计耗时分布 。 我们先统计底层存储(Redis)的耗时分布 , 然后再分别统计 BigCache 和 GroupCache 在写入 500w 数据后的实际情况 。 分析结论可知:
40ms 以上请求从 redis 数据看 , 40ms 以上请求占比0.08%;BigCache 的 40ms 以上请求占0.04%(即相反有一半以上超时请求被 Cache 挡住了) GroupCache 则是0.2% , 将这种长时间请求放大了1倍多(推测和 map 的锁机制有关)
10ms-40ms 请求redis 本身这个区间段请求占比24.11%;BigCache 则只有15.51% , 相当于挡掉了33%左右的高延迟请求(证明加热点 Cache 还是有作用的) GroupCache 这个区间段请求占比21.55% , 也比直接用 redis 来得好
详细数据分布:
redis[0.1] 0.00%redis[0.5] 0.38%redis[1] 3.48%redis[5] 71.94%redis[10] 22.90%redis[20] 1.21%redis[40] 0.07%redis[ +Inf] 0.01%bigcache[0.1] 0.40%bigcache[0.5] 16.16%bigcache[1] 14.82%bigcache[5] 53.07%bigcache[10] 14.85%bigcache[20] 0.66%bigcache[40] 0.03%bigcache[ +Inf] 0.01%groupcache[0.1] 0.24%groupcache[0.5] 9.59%groupcache[1] 9.69%groupcache[5] 58.74%groupcache[10] 19.10%groupcache[20] 2.45%groupcache[40] 0.17%groupcache[ +Inf] 0.03%然而我们测完只能大致知道:本地使用 GroupCache 在 500w 量级的 keys 下 , 还是不如 BigCache 稳定的(哪怕 GroupCache 实现了 LRU 淘汰 , 但实际上因为有 Hot/Main Cache 的存在 , 内存利用效率上不如 BigCache)分布式情况下 , GroupCache 和 BigCache 相比又有多少差距 , 这个就只能挖坑等大家一起跳了 。
4. 对象池与零拷贝在实际业务中 , 往往 map 中并不会存储 5000w 级的 keys 。 如果我们只有 50w 的 keys , GC 停顿就会骤减到 4ms 左右(其间 gc worker 还会并行工作 , 避免 STW) 。
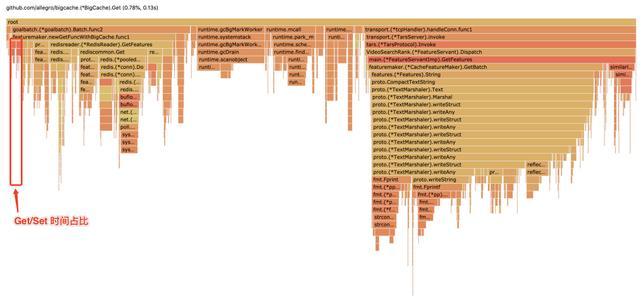
例如无极(腾讯内部的一个配置服务)这类配置服务(或其他高频数据查询场景) , 往往需要 Get(key) 获取对应的结构化数据 。 而从 BigCache , CPU 消耗发现(如图) , 相比网络 IO 和 Protobuf 解析 , Get 占用0.78%、Set 占用0.9% , 基本可以忽略:
 文章插图
文章插图【从入门到掉坑:Go 内存池/对象池技术介绍(含GroupCache详解)】CPU profile
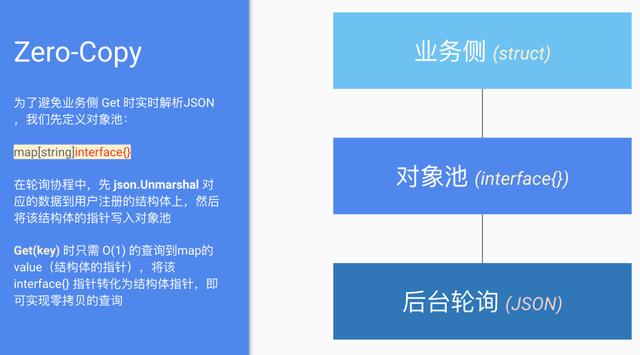
因此优化的思路也很明确 , 我们参考 GroupCache 的 lru 实现 , 将 JSON 提前解析好 , 在业务侧 Get 时直接返回 struct 的指针即可 。 具体流程不复杂 , 直接 ppt 截图:
 文章插图
文章插图zero-copy
我们把接口设计成注册的方式(注册需要解析 JSON 数据的结构) , 然后再 Get 时返回该结构的指针实现零拷贝 。 下面 benchmark 可以反映性能差异和内存分配情况(Client_Get 是实时 JSON 解析 , Filter_Get 是优化的对象池 API) , 可以切实看到0 allocs/op:
goos: linuxgoarch: amd64pkg: open-wuji/go-sdk/wujiclientBenchmarkClient_Get-810000001154 ns/op1.00 hits87 B/op3 allocs/opBenchmarkFilter_Get-84899364302 ns/op1.00 hits7 B/op1 allocs/opBenchmarkClient_GetParallel-88383149162 ns/op1.00 hits80 B/op2 allocs/opBenchmarkFilter_GetParallel-81305368091.4 ns/op1.00 hits0 B/op0 allocs/opPASSokopen-wuji/go-sdk/wujiclient 93.494sSuccess: Benchmarks passed.
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 手机|这个超强App,让手机快3倍,流畅到起飞
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 走向|电商,从货架陈列走向内容驱动
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元