hive学习笔记之四:分区表( 二 )
 文章插图
文章插图
- 查看数据:
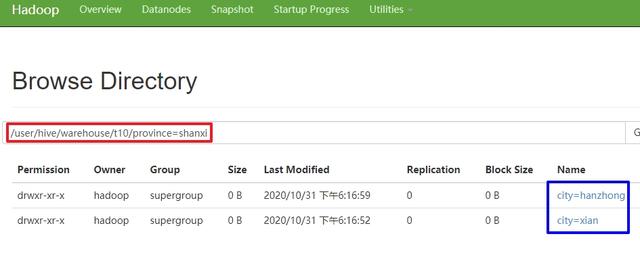
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t10/province=shanxi/city=hanzhong/009.txttom,11jerry,12- 以上就是静态分区的基本操作 , 可见静态分区有个不便之处:新增数据的时候要针对每一个分区单独使用load命令去操作 , 这时候使用动态分区来解决这个麻烦;
- 动态分区的特点就是不用指定分区目录 , 由hive自己选择;
- 执行以下命令开启动态分区功能:
set hive.exec.dynamic.partition=true- 名为hive.exec.dynamic.partition.mode的属性 , 默认值是strict , 意思是不允许分区列全部是动态的 , 这里改为nostrict以取消此禁制 , 允许全部分区都是动态分区:
set hive.exec.dynamic.partition.mode=nostrict;- 建一个外部表 , 名为t11 , 只有四个字段:
create external table t11 (name string, age int, province string, city string) row format delimited fields terminated by ',' location '/data/external_t11';- 创建名为011.txt的文件 , 内容如下:
tom,11,guangdong,guangzhoujerry,12,guangdong,shenzhentony,13,shanxi,xianjohn,14,shanxi,hanzhong- 将011.txt中的四条记录载入表t11:
load data local inpath '/home/hadoop/temp/202010/25/011.txt' into table t11;- 接下来要 , 先创建动态分区表t12 , 再把t11表的数据添加到t12中;
- t12的建表语句如下 , 按照province+city分区:
create table t12 (name string, age int) partitioned by (province string, city string)row format delimited fields terminated by ',';- 执行以下操作 , 即可将t11的所有数据写入动态分区表t12 , 注意 , 要用overwrite:
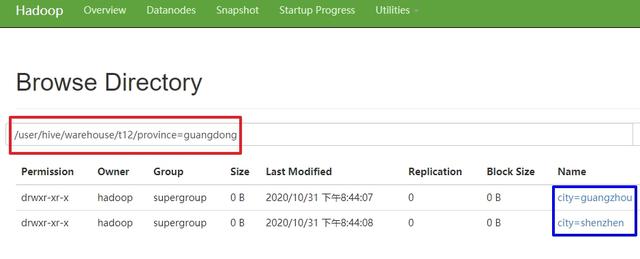
insert overwrite table t12 partition(province, city) select name, age, province, city from t11;- 通过hdfs查看文件夹 , 可见一级和二级子目录都符合预期:
 文章插图
文章插图- 最后检查二级子目录下的数据文件 , 可以看到该分区下的记录:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t12/province=guangdong/city=guangzhou/000000_0tom,11至此 , 分区表的学习就完成了 , 希望能给您一些参考;欢迎关注我的公众号:程序员欣宸
 文章插图
文章插图- 截图|笔记本截图快捷键是什么
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 每日|【每日idea 分享】12月1日:带朋友一起网上购物;线上笔记本应用程序
- 用于|用于半监督学习的图随机神经网络
- 复习|期末整理复习笔记?MHMO魅蒙iPad专用笔助提高效率
- 今日|“舜网”学习强国号今日上线 济南报业全媒体矩阵再添新成员
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 效果|这个让你相见恨晚的技巧,能让PPT排版更加有设计感,推荐学习
- 学习C语言的软件,就突然被我绿了?
- 学习python第二弹