持续定义 SaaS 模式云数据仓库 + Serverless
一、Serverless简介【持续定义 SaaS 模式云数据仓库 + Serverless】下图是MaxCompute的Serverless架构 , 主要包括数据接入服务、多计算环境、储存服务和管理几个模块 。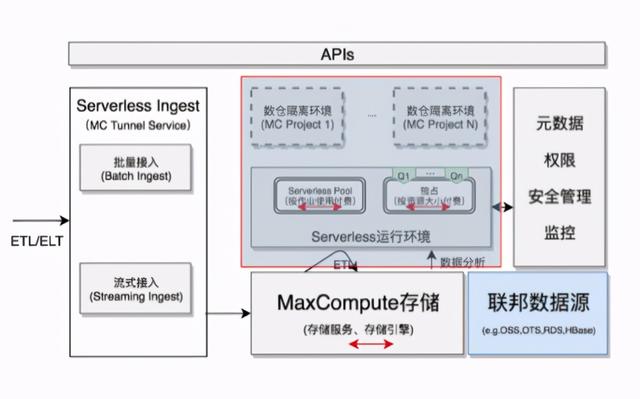 文章插图
文章插图
其中各个模块的主要特点如下:
(1)Serverless的数据接入服务
- 提供Tunnel批量、流式导入 , 转换为MC列存格式、自动伸缩等功能 , 且免费;
- 可以免费使用LOAD/UNLOAD命令进行OSS导入/导出 。
- Severless计算资源池 , 大规模计算资源池 , On-demand按需提供 , 按作业付费;
- 独占计算资源:支持包年包月付费、Workload管理(负载隔离、优先级、分时伸缩等);
- 运行环境(runtime)支持ETL/OLAP/ML等大数据分析使用场景 。
- 与计算无关 , 独立伸缩 , 提供GB-EB级别的存储服务;
- 按实际存储大小付费 , 降低成本;
- 无需指定 , 默认面向分析优化(列压、压缩);
- 支持区分/分桶/Zorder等优化手段 。
- 开箱即用 , 内建了完整的管理能力 , 以API/sdk/web-console管理;
- 平台则无需用户运维 , 降低成本 。
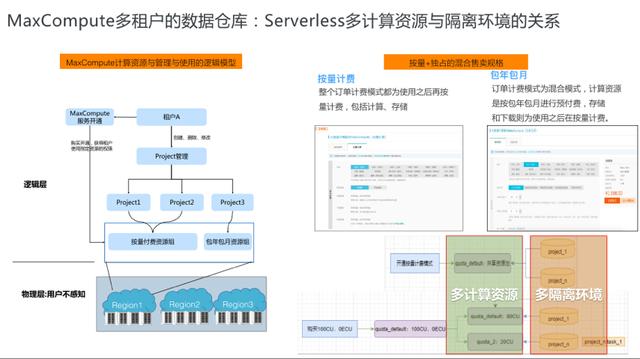
下图所示的是MaxCompute计算资源与管理与使用的逻辑模型 。 对于MaxCompute中的Project , 实际上对应的是一个逻辑的数据仓库的隔离单元 , 我们可以根据不同的管理目标创建不同的Project , 比如我们可以分别创建面向测试的Project和面向开发的Project , 两个项目之间有独立的数据和权限管理体系 , 并不互通 , 达到管理的隔离作用 。 当然 , 只有这样的隔离空间还不足够 , 因为我们的计算任务需要绑定计算资源 , 我们可以将Project与付费方式绑定 , 根据需求 , 对不同的Project设置不同的计费方式 , 使得不同的隔离空间使用不同的计算资源 。
 文章插图
文章插图在上述的体系之下 , MaxCompute有着一些独特的特点 , 首先就是有一个多租户环境 , 我们在开通了MaxCompute可以根据不同的管理需求创建多个隔离的数据仓库空间 , 对于企业来说 , 可以购买多组逻辑上的计算资源 , 这种多计算资源、多隔离环境 , 可以更好地满足不同的场景需要 。 如下图所示 , 理想中的Serverless资源模型要求我们很好的规划资源的利用方式才能够完美的适配我们的实际需求(图中黑线) 。
 文章插图
文章插图但是 , 实际上我们的客户有不同的资源需求 , 有着众多的差异化需求场景 , 其场景主要有:
- 稳定的周期性作业场景;
- 业务高度增长、需求快速变化的场景;
- 常规需求伴随着突发需求的场景;
- 测试/开发需求的场景 。
(1)业务敏捷性需求
- 长期处于成长期 , 处理能力能满足业务自然增长的需要 , 特别是业务快速变化的阶段;
- 可以是企业的初期 , 也可以是创新部门的创业业务;
- 每天、每月周期性的峰谷波动巨大 , 以峰值容量规划 , 成本和SLA难以平衡;
- 需要常规算力+弹性算力 , 根据调度/人为指定作业资源策略;
- 基线作业 , 与非关键作业的SLA需求不同 , 基线产出时间需要保障;
- 非关键作业尽可能低成本处理 , 同时不影响关键作业;
- 对CU的容量规划 , 相互转换以及测算;
- 固定资源的精细化的Workload管理 。
二、Serverless助力业务敏捷那么 , MaxCompute的Serverless如何满足上述的场景和需求呢?如果是一个业务快速发展、快速变化的企业 , 我们建议使用MaxCompute的Serverless按需使用的计算资源 。 从管理上来讲的话 , 我们可以建立不同的Project去做一些隔离的划分 , 比如说建立一套开发测试环境 , 一套生产环境 。 对于有些分析师来讲 , 他们往往随机地需要对一些明细数据做大量的探索 , 或做机器学习分析 , 往往有一些突发的算力需求 , 且这个算力需求的规模可能非常大 , 这个时候往往这些作业要和其他的环境隔离 , 因为他们是低频的 , 但是却需要对海量数据做分析 。
- 紧固件|66家落户9家已投产!阳东紧固件产业持续壮大
- QQ|QQ更新:可以自定义ID了
- 增值业务营|陌陌Q3净利润6.538亿元,持续23个季度盈利
- 个性|腾讯QQ上线QID服务 自定义专属ID创造个性社交体验
- 曹斌|对话东软睿驰曹斌:软件定义汽车时代,未来最赚钱的还是主机厂
- 手机|Redmi Note9 Pro重新定义千元机
- 持续|十一月推荐手机系列,iQOO今年多款机型热度持续
- 主业|美团Q3主业全面恢复正增长 新业务持续投入、亏损增至20亿元
- 付费|谁在定义未来三十年?音频内容付费,60后人数同比增154%,00后增94%
- 身份|QQ正式上线QID功能,用户可自定义专属身份卡