针对单样本学习的多级语义特征扩增技术
 文章插图
文章插图
引用:Chen, Zitian, et al. "Multi-level semantic feature augmentation for one-shot learning." IEEE Transactions on Image Processing 28.9 (2019): 4594-4605.
摘要:快速从有限的样本中识别和学习新概念的能力使得人类能够快速适应新环境 。 通过将新颖概念与已经学习并存储在内存中的概念进行语义关联 , 可以使深度学习模型获得这种能力 。 通过语义概念空间 , 计算机可以开始理解类似的功能 。 概念空间是一个高维语义空间 , 其中相似的抽象概念彼此靠近而相异的抽象概念却相距很远 。 在本文中 , 我们提出了一种基于此核心思想的单样本学习方法 。 我们的方法将新的实例映射到概念空间 , 将该概念与概念空间中的现有实例相关联 , 并使用这些关系在概念之间进行插值来生成新实例 。 此外 , 我们提出了直接利用语义来直接合成实例特征的自动编解码器网络(称为双重 TriNet) 。 TriNet 的编码器部分学习如何将 CNN 的多层视觉特征映射到语义向量 。 在语义空间中 , 我们搜索相关性高的概念 , 然后由 TriNet 的解码器部分将其投影回图像特征空间 。 值得注意的是 , 这种看似简单的扩增策略会导致图像特征空间中复杂的特征分布 , 从而显着提高性能 。
背景:A.小样本学习 Few-Shot Learning
小样本学习的动机是人类在面对少量新样本时 , 能够利用已有知识来快速学习 。 通常业界有两种解决办法:
- 基于监督学习 , 利用一个已有的富样本生成器来直接训练分类器 , 例如基于实例的学习模型、无参模型、深度生成模型、基于贝叶斯的自动编解码器等;
- 基于迁移学习 , 基于已有的训练参数来认识新样本 , 即在预先训练好的模型上进行 fine-tuning , 包括元学习算法;
标准的数据扩增技巧通常应用在图像域 , 包括翻转、旋转、噪化以及随机裁切 。 此后 , 更多高级的扩增方法被研究出来 , 主要分为以下 6 类:
- 通过半监督或变换的方式获取未进行标记数据的流形信息;
- 从现有的训练模型中自适应地学习;
- 从相邻的类目中借取数据样本;
- 通过渲染虚拟数据样本;
- 利用 GAN 来生成新数据样本;
- 基于属性制导的扩增和特征空间迁移来合成所需的样本;
- 半监督算法依赖于流形假设 , 但在实际中几乎不可被验证;
- 迁移学习会饱受负样本的影响 , 从使得模型泛化能力变差;
- 基于已有样本渲染、组合出新样本需要丰富的领域知识;
C.子结构嵌入
最常用的一种办法是将视觉特征投影到高维空间 , 同时在高维空间中嵌入所需的语义信息 , 此后可以再利用一个解码器将高维特征重新映射回低维空间 。
方法:
- 问题定义:
- 思路与方案:
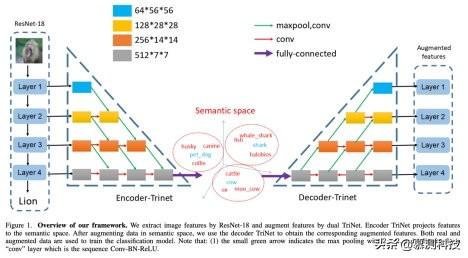 文章插图
文章插图 文章插图
文章插图 文章插图
文章插图实验结果:以下是作者所给出的实验结果
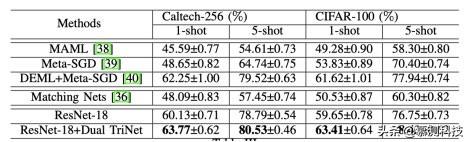 文章插图
文章插图可以看到 , ResNet-18 和 Dual TriNet 在 Caltech-256 以及 CIFAR-100 的小样本分类问题均取得了最好的效果 。
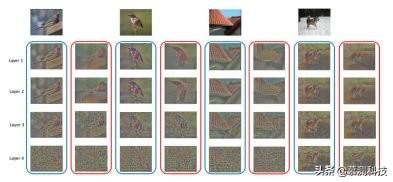 文章插图
文章插图上图展示了原始 feature map 以及经过数据增强后的 feature map 。
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 培训班|单县残联举办残疾人电子商务培训班
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 公式|?有人把 5G 讲得这么简单明了
- 砍单|iPhone12之后,拼多多又将iPhone12Pro拉下水
- 误导|苹果又吃巨额罚单,因iPhone防水宣传有误导被重罚9400万
- 简单|互联网巨头夺走菜贩生计?未必那么简单
- 名单|河南8个项目入选国家级示范名单