深入分析JVM:Java垃圾收集算法+常用垃圾收集器解析( 三 )
注意:这里的并行指的是多个GC线程并行 , 但是其他线程还是暂停 , 而并发指的是用户线程和GC线程同时执行 。
ParNew收集器默认开启和CPU个数相同的线程数来进行回收 , 可以使用参数:-XX:ParallelGCThreads来限制线程数ParNew收集器工作原理如下图: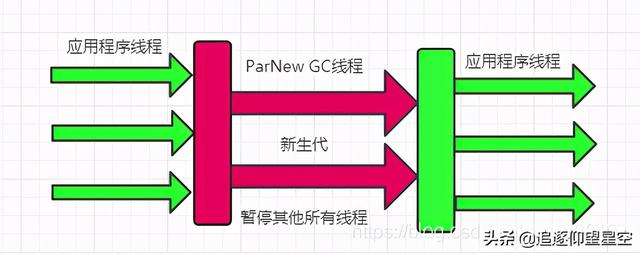 文章插图
文章插图
优点:在多CPU时 , 比Serial效率高 。 缺点:收集过程暂停所有应用程序线程 , 单CPU时比Serial效率差算法:复制算法适用范围:新生代应用:运行在Server模式下的虚拟机中首选的新生代收集器
Parallel Scavenge收集器Parallel Scavenge收集器是一个新生代收集器 , 它也是使用复制算法的收集器 , 和ParNew一样也是一个并行的多线程收集器 , Parallel Scanvenge收集器相比较于ParNew收集器 , 更关注与提升系统的吞吐量 。
吞吐量指的是CPU用于运行用户代码的而时间于CPU总消耗时间的比值 。 即:吞吐量=运行用户代码时间/(运行用户代码时间+GC时间)
Parallel Scavenge收集器提供了两个参数用于精确控制吞吐量:
-XX:MaxGCPauseMillis//GC最大停顿毫秒数 , 必须大于0-XX:GCTimeRatio//设置吞吐量大小 , 大于0小于100 , 默认值为99我们思考一个问题 , 假如我们通过参数把允许最大停顿毫秒数设置的相对较小会怎么样?是不是GC速度就会变快了?
答案是否定的 。 如果设置的时间过短 , Parallel Scavenge收集器会牺牲吞吐量和新生代空间来交换 。 比如新生代400Mb需要GC时间为100ms , 然后手动设置为50ms , 那么就会把新生代调小为200Mb , 这样肯定时间就降下来了 , 然而这种操作可能会降低吞吐量 , 假如说原先是10s触发一次GC,每次100ms , 修改时间后编程5s触发一次GC , 每次70ms , 那么10s触发两次GC时间就变成了140ms , 吞吐量反而降低 。
如果不知道如何设置 , 那么还可以通过参数:-XX:+UseAdaptiveSizePolicy开启自适应策略(GC Ergonomics) , 这样我们就不需要手动设置吞吐量和GC停顿时间了 , 虚拟机会根据运行情况手机监控信息来动态调整 。
Paralled Old收集器Paralled Old收集器是Parallel Scavenge收集器的老年代版本 , 但是这个收集器是jdk1.6之后才出现的 , 所以导致了在Paralled Old收集器出现之前Parallel Scavenge收集器一直找不到合适的“搭档” 。 因为Parallel Scavenge收集器没办法和CMS收集器配合使用(后面会介绍原因) , 所以在Paralled Old收集器出现之前 , 如果新生代选择了Parallel Scavenge收集器 , 那么老年代就只能选择Serial Old收集器 , 而Serial Old收集器是单线程的 , 所以单单只是新生代替换成了多线程的吞吐量收集器Parallel Scavenge , 在性能上并不一定有多少提升 。
在注重吞吐量的业务系统中 , 可以考虑Parallel Scavenge+Paralled Old收集器配合使用 , 结合使用后的工作原理如下图所示: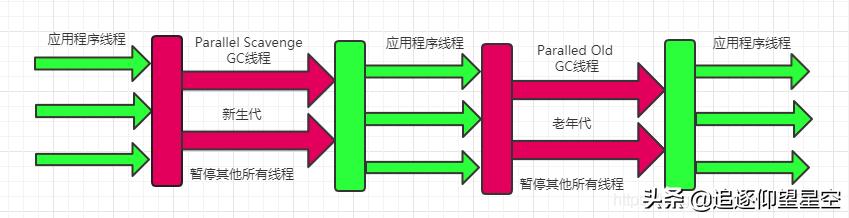 文章插图
文章插图
PS:在jdk1.8中 , 默认收集器就是Parallel Scavenge+Parallel Old组合
CMS(Concurrent Mark Sweep)收集器这是一种以实现GC时最短停顿时间为目标的收集器 , 也是一款真正实现了并发回收的收集器 。 当然 , 虽然是并发的 , 但是仍然需要Stop The World , 只是尽可能将这个时间缩到最短 。
对于任何暂停时间要求较低的应用程序 , 都应该考虑使用此收集器 。 CMS收集器可以通过参数:-XX:+UseConcMarkSweepGC启用 。
CMS收集器是基于算法标记-清除来实现的 , 整个过程分为4步:
- 1、初始标记(inital mark)需要Stop The World 。 标记GC Roots对象 , 因为GC Root对象并不会很多 , 所以这个过程非常快 。
- 2、并发标记(concurrent mark)这个阶段可以和用户线程同时进行 , 也可以分为三步:(1)并发标记(CMS-concurrent-mark):主要是进行GC Roots Tracing 。 就是说根据第1步中找到的GC Root对象 , 开始搜索 , 这个过程相比阶段1是比较慢的 。 (2)预清理(CMS-concurrent-preclean) , 这个阶段是为了处理并发标记之后发生了变化的对象(3)可被终止的预清理(CMS-concurrent-abortable-preclean) , 这个预清理差不多 , 但是是可以被终止的 , 主要是为了尽可能分担下面第3步的工作 , 这个阶段会有一个abort触发条件 , 该阶段存在的目的是希望能发生一次Young GC , 这样就可以减少Young区对象的数量 , 降低重新标记的工作量 , 因为重新标记会扫描整个堆内空间 。 可以通过参数-XX:+CMSScavengeBeforeRemark参数控制在重新标记前发生一次Young GC , 默认为false 。 这个阶段发生的最大时间由-XX:CMSMaxAbortablePrecleanTime控制 , 默认5s
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 三年Java开发,刚从美团、京东、阿里面试归来,分享个人面经
- 《深入理解Java虚拟机》:对象创建、布局和访问全过程
- java面试题整理
- Kotlin集合vs Kotlin序列与Java流
- Java安全之Javassist动态编程
- 推荐Java工程师必看,12个Hadoop领域的上手项目
- 震惊!京东T4大佬面试整整三个月,才写了两份java面试笔记
- 整理:常见的Java开发框架有哪些,看过,就赶紧收藏吧