反例指导的数据扩增
 文章插图
文章插图
摘要我们提出了一个新颖的框架 , 用于扩增机器学习的反例数据集 。 反例是分类错误的示例 , 对重新训练和改进模型具有重要意义 。 我们框架的关键组件包括一个反例生成器 , 它生成由模型和错误表错误分类的数据项 。 错误表是一种新颖的数据结构 , 用于存储与错误分类有关的信息 。 它可用于解释模型的漏洞 , 并用于有效地生成扩增的反例 。 我们将提出的框架与经典的扩增技术进行了比较——基于深度神经网络的自动驾驶中目标检测的案例研究 , 从而证明了该框架的有效性 。
介绍由机器学习算法(尤其是深度神经网络)生成的模型正被部署在值得高度关注的领域中 , 需要更高的准确性和保证力 。 然而使用深度学习来学习高精度模型受到大量数据需求的限制 , 甚至进一步受到劳动密集型标签的需求的限制 。 数据扩增通过使用保留标签的变换扩大训练集来克服数据的不足 。 传统的数据扩增方案涉及几何变换 , 这些变换会改变图像的几何形状(例如 , 旋转 , 缩放 , 裁切或翻转) , 以及改变颜色通道的光度转换 。 这些技术的有效性最近已得到证明 。 像前面提到的方法一样 , 传统的扩增方案将数据添加到训练集中 , 希望提高模型的准确性 , 而无需考虑模型已经学习了哪些特征 。 最近 , 一种复杂的数据扩增技术被提出 , 该技术使用生成对抗网络(一种能够生成合成数据的特殊类型的神经网络)来充实训练集 。 也有诸如hard negative mining之类的扩增技术 , 它们以有针对性的否定示例充实训练集 , 目的是减少误报 。
在这项工作中 , 我们提出了一种新的扩增方案 , 即以反例为指导的数据扩增 。 主要思想是仅使用新的分类错误的示例来扩增训练集 , 而不是使用原始训练集中的修改后的图像 。 提出的扩增方案包括以下步骤:1)生成被模型误分类的合成图像 , 即反例; 2)将反例添加到训练集中; 3)在扩增数据集上训练模型 。 可以重复这些步骤 , 直到达到所需的精度为止 。 请注意 , 我们的扩增方案取决于生成错误分类图像的能力 。 因此 , 我们开发了一种与采样器配合使用的图像生成器 , 以生成作为模型输入提供的图像 。 这些图像以一种能够自动添加地面真实值标签的方式生成 。 分类错误的图像构成了增加集并被添加到训练集 。 除图片外 , 图像生成器还提供有关分类错误的图像的信息 , 例如元素的位置 , 亮度 , 对比度等 。 此信息可用于查找反例中经常出现的特征 。 我们在称为“错误表”的数据结构中收集有关反例的信息 。 错误表对于提供有关反例的说明以及查找可能导致图像分类错误的重复模式非常有用 。 错误表分析还可以用于生成可能是反例的图像 , 从而有效地构建扩增集 。
主要贡献如下:
- 以反例为指导的数据扩增方法 , 仅将错误分类的示例迭代添加到训练集中;
- 合成图像生成器 , 提供逼真的示例;
- 错误表存储有关反例的信息 , 它的分析提供了解释 , 促进生成反例图像 。
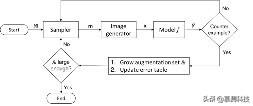
总览图 1 总结了提出的反例指导的扩增方案 。 该程序将修改空间 M(即图像生成器可能配置的空间)作为输入 。 基于领域知识将空间 M 构造为“语义修改”空间;即 , 每个修改都必须在使用机器学习模型的应用领域中具有含义 。 这使我们能够执行更多有意义的数据扩增而不仅仅是通过扰动输入向量(例如 , 在图像中对抗性选择和修改少量像素值)进行对抗性数据生成 。
 文章插图
文章插图图 1:反例指导的扩增方案
在每个循环中 , 采样器都会从 M 中选择一个修改 m 。 采样是通过一种可以由预计算误差表(该数据结构存储有关模型误分类的图像信息的数据结构)所偏向的采样方法确定的 。 图像生成器将采样的修改呈现为图片 x 。 图像 x 被提供作为返回预测 y 的模型 f 的输入 。 我们检查 x 是否为反例也就是 y 是否错误 。 如果是 , 我们将 x 添加到扩增集 A 中 , 并将 x 的信息(例如 m , y)存储在误差表中 , 供采样器在下一次迭代中使用 。 重复循环 , 直到扩增集 A 足够大(或已充分覆盖 M) 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面