打通IO栈:一次编译服务器性能优化实战( 四 )
如果因为之前读写过或者被预读加载进来 , 要读取数据刚好在缓存中命中 , 就可以直接从缓存中读取 , 不需要深入到磁盘 。 不管是同步写还是异步写 , 都会把数据copy到缓存 , 差别在于异步写只是copy且把页标识脏后直接返回 , 而同步写还会调用类似fsync()的操作等待回写 , 详细可以看内核函数generic_file_write_iter() 。 异步写产生的脏数据会在“合适”的时候被内核工作队列writeback进程回刷 。
那么 , 什么时候是合适的时候呢?最多能缓存多少数据呢?对此次优化的服务器而言 , 毫无疑问延迟回刷可以在频繁的删改文件中减少写磁盘次数 , 缓存更多的数据可以更容易合并随机IO请求 , 有助于提升性能 。
在/proc/sys/vm中有以下文件与回刷脏数据密切相关:
配置文件功能默认值dirty_background_ratio触发回刷的脏数据占可用内存的百分比0dirty_background_bytes触发回刷的脏数据量10dirty_bytes触发同步写的脏数据量0dirty_ratio触发同步写的脏数据占可用内存的百分比20dirty_expire_centisecs脏数据超时回刷时间(单位:1/100s)3000dirty_writeback_centisecs回刷进程定时唤醒时间(单位:1/100s)500
对上述的配置文件 , 有几点要补充的:
- XXX_ratio 和 XXX_bytes 是同一个配置属性的不同计算方法 , 优先级 XXX_bytes > XXX_ratio
- 可用内存并不是系统所有内存 , 而是free pages + reclaimable pages
- 脏数据超时表示内存中数据标识脏一定时间后 , 下次回刷进程工作时就必须回刷
- 回刷进程既会定时唤醒 , 也会在脏数据过多时被动唤醒 。
更完整的功能介绍 , 可以看内核文档Documentation/sysctl/vm.txt , 也可看我写的一篇总结博客《Linux 脏数据回刷参数与调优》
对当前的案例而言 , 我的配置如下:
dirty_background_ratio = 60dirty_ratio = 80dirty_writeback_centisecs = 6000dirty_expire_centisecs = 12000这样的配置有以下特点:- 当脏数据达到可用内存的60%时唤醒回刷进程
- 当脏数据达到可用内存的80%时 , 应用每一笔数据都必须同步等待
- 每隔60s唤醒一次回刷进程
- 内存中脏数据存在时间超过120s则在下一次唤醒时回刷
# cat /etc/sysctl.conf...vm.dirty_background_ratio = 60vm.dirty_ratio = 80vm.dirty_expire_centisecs = 12000vm.dirty_writeback_centisecs = 6000Request层在异步写的场景中 , 当脏页达到一定比例 , 就需要通过通用块层把页缓存里的数据回刷到磁盘中 。 bio层记录了磁盘块与内存页之间的关系 , 在request层把多个物理块连续的bio合并成一个request , 然后根据特定的IO调度算法对系统内所有进程产生的IO请求进行合并、排序 。 那么都有什么IO调度算法呢?网上检索IO调度算法 , 大量的资料都在描述Deadline , CFQ , NOOP这3种调度算法 , 却没有备注这只是单队列上适用的调度算法 。 在最新的代码上(我分析的代码版本为 5.7.0) , 已经完全切换到multi-queue的新架构上了 , 支持的IO调度算法就成了mq-deadline , BFQ , Kyber , none 。
关于不同IO调度算法的优劣 , 网上有非常多的资料 , 本文不再累述 。
在《Linux-storage-stack-diagram_v4.10》 对 Block Layer 的描述可以形象阐述单队列与多队列的差异 。
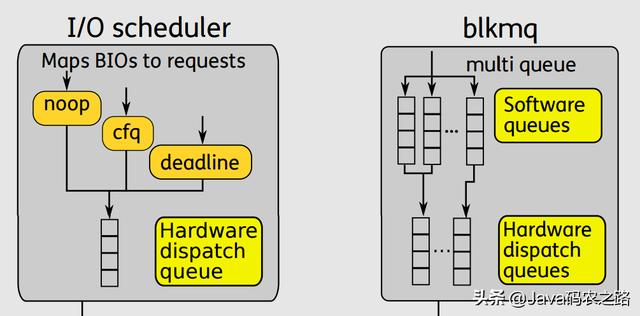 文章插图文章插图
文章插图文章插图单队列的架构 , 一个块设备只有一个全局队列 , 所有请求都要往这个队列里面塞 , 这在多核高并发的情况下 , 尤其像服务器动则32个核的情况下 , 为了保证互斥而加的锁就导致了非常大的开销 。 此外 , 如果磁盘支持多队列并行处理 , 单队列的模型不能充分发挥其优越的性能 。
多队列的架构下 , 创建了Software queues和Hardware dispatch queues两级队列 。 Software queues是每个CPU core一个队列 , 且在其中实现IO调度 。 由于每个CPU一个单独队列 , 因此不存在锁竞争问题 。 Hardware Dispatch Queues的数量跟硬件情况有关 , 每个磁盘一个队列 , 如果磁盘支持并行N个队列 , 则也会创建N个队列 。 在IO请求从Software queues提交到Hardware Dispatch Queues的过程中是需要加锁的 。 理论上 , 多队列的架构的效率最差也只是跟单队列架构持平 。
- 定制|业绩宝APP创始人戴宏伟:依靠人工智能主动获客,打通全链路
- 统计|多久才能换一次手机?统计机构数据有点意外
- 不让|12月第一次统计手机热卖榜 前三果然不让人失望
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- SVIP|QQ开放QID身份号:SVIP也只能花10元修改一次
- 研发|全球目光紧盯英国,倪光南又一次发出警告:必须阻止这一场交易
- 运维|全栈智能业务运维服务商云智慧完成 D3 轮 6000 万美元融资
- 开发|打通数据应用瓶颈 激活应用场景开发
- 最惨|这是 iPhone 12 被黑最惨的一次!
- 产业|新主导力量来了,上海如何实现一次“革命性重塑”?