分布式存储 Ceph 的演进经验 · SOSP 2019( 二 )
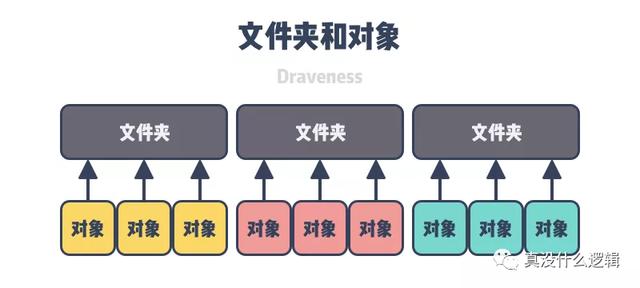
RADOS 集群中的对象会根据文件名的哈希映射到某一个放置组中 , 这些对象在遍历时也会遵循哈希顺序 , 当我们在系统中遇到很长的对象名时 , 可能需要使用扩展属性突破本地文件系统的文件名长度限制 , 查找这些文件时也需要调用 stat 获取文件的真实文件名进行比对 。 为了解决系统的缓慢遍历问题 , 我们使用如下所示的层级结构来存储文件对象:
 文章插图
文章插图]图 5 - 文件夹和对象
查找或者遍历文件时 , 我们会先选择合适的文件夹 , 再遍历文件夹中的对象 , 而为了减少 stat 函数的调用 , 存储后端需要保证每个文件夹中的文件尽可能少;当文件夹中的内容逐渐增加时 , 我们也需要将其中的内容拆分到多个文件夹中 , 不过这个内容分割的过程却是极其耗时的 。
支持新硬件设备因为分布式的文件系统的运行基于本地的文件系统 , 而存储硬件的高速发展会为分布式文件系统带来更多的挑战 。 为了提高存储设备的容量与性能 , HDD、SSD 的提供商通过引入主机管理的 SMR 以及 ZNS 技术对现有的硬件进行改进 , 这些技术对提高分布式文件系统的性能异常重要 , 而存储设备的开发商也在开发新的硬件 , 这也增加了文件系统的适配成本 。
总结【分布式存储 Ceph 的演进经验 · SOSP 2019】传统的分布式文件系统开发者一般都会将本地的文件系统作为它们的存储后端 , 然后尝试基于本地的文件系统构建更加通用的文件系统 , 然而因为底层的工具并不能完全兼容 , 所以这会为项目带来极大的复杂性 , 这是因为很多开发者认为开发新的文件系统可能需要 10 年的时间才能成熟 , 然而基于 Ceph 团队的经验 , 从零开始开发成熟的存储后端并不要那么长的周期 。
从作者的角度来看 , Ceph 的演进过程其实是合理的 , 我们在刚开始构建系统时希望尽可能利用现有的工具减少我们的工作量 , 只有当现有的工具不再趁手时 , 才应该考虑从零构建复杂的系统 , 如果 Ceph 从立项开始就从零构建存储后端 , 可能 Ceph 也不会占领市场并得到今天这样的地位 。
- 创园|中国V谷的云存储之道,马栏山文创园将视频处理效率提升6倍
- 国产电视大厂进军存储行业?康佳PS300移动硬盘体验
- 分布式锁的这三种实现90%的人都不知道
- 软件定义存储之ScaleIO,VMWare环境详细部署和使用
- 次世代Xbox扩展存储卡拆解:群联主控配合海力士存储芯片
- 支持最高80TB存储空间 联想个人云存储X1开箱图赏
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 用QNAP 453Dmini+网件RAX8打造影片存储中心
- 小钱解决大问题,花粉扩容好选择:惠普 NM100 NM存储卡