OCR in the Wild:文本检测和识别的SOTA
作者:Noé
编译:ronghuaiyang
导读
回顾了场景文本检测和识别领域的3篇论文 , 分别是检测 , 识别以及端到端的方法 。
基于深度学习的方法可以在自然图像中检测和识别复杂的文本实例 。 文章插图
文章插图
介绍光学字符识别(OCR)包括自动解码图像中的文本实例 。 此任务的复杂性因应用而异 。 一方面 , 从扫描的报纸上阅读单词是比较容易的 , 因为文本是直的 , 一致的 , 和背景有很好的对比 。 另一方面 , 在自然图像中使用创造性字体的弯曲文本实例不仅读起来更有挑战性(文本识别):它还需要一个棘手的初步步骤来定位图像中的文本(文本检测) 。 传统的计算机视觉技术可以很好地处理前者 , 而后者需要先进的(SOTA)深度学习方法结合CNNs和RNNs 。
阅读场景文本 , 即阅读文本实例“in the wild” , 需要两个步骤:
- 文本检测:找到图像中的文本实例的位置 。
- 文本识别:解码检测到的文本实例的每个字符 。
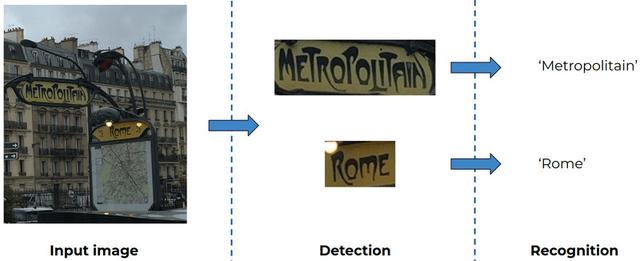 文章插图
文章插图由于字体的复杂性 , 上图中的“Metropolitain”和“Rome”这两个单词很有挑战性!
为了更好地理解场景文本检测和识别 , 本文会讨论:
- Textsnake [Long et al. ,2018] , 一种文本检测算法 , 能够处理非常复杂的文本形状 。
- MORAN [Luo et al. ,2019] , 一种使用校正网络和注意力机制纠正和阅读复杂文本框的文本识别算法 。
- FOTS [Liu et al. ,2018] , 一种共享检测步骤和识别步骤卷积的端到端方法 , 提高了鲁棒性和效率 。
- 一个有趣的实验结果 , 将FOTS和Textsnake结合 。
U-net用在上下文检测中下图显示的编码器每一步的分割图是在那一层执行一次反卷积的结果(图像来自[Zhang et al. ,2019]) 。 这种可视化强调了编码器是如何以失去空间信息的代价逐步提取深度特征的 。 因此 , 逐步地将编码的映射合并到解码的映射(灰色箭头)可以取回编码期间丢失的空间信息 。
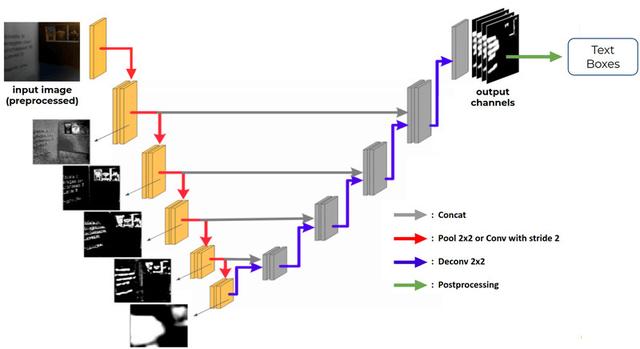 文章插图
文章插图给出了U-net的总体结构 , 并在每个编码步骤中给出了深层次特征的可视化描述 。 每一步的卷积和通道的数量取决于主干架构 。
Textsnake: A Flexible Representation for Detecting Text of Arbitrary Shapes [Long et al., 2018]与大多数检测算法不同 , Textsnake处理任意形状的文本结构 。 为此 , 算法计算一条1像素的粗线 , 穿过文本实例的中心 , 如下图中的绿色所示 。 与这条线的每个点相关的半径r使绘制描绘文本区域的圆成为可能 。 此外 , 角度θ表示用于拉平文本时所必要的旋转 。
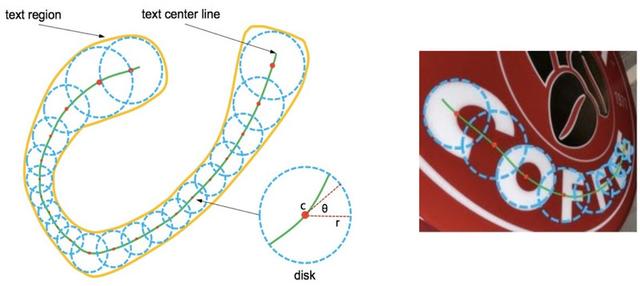 文章插图
文章插图输出通道如下:
- TR (Text Region): 指示了文本和非文本区域的分割图 。
- TCL (Text Center Line): 穿过文本实例中心的区域 。
- radius, cos θ, sin θ: 用来构建圆所需的参数 。
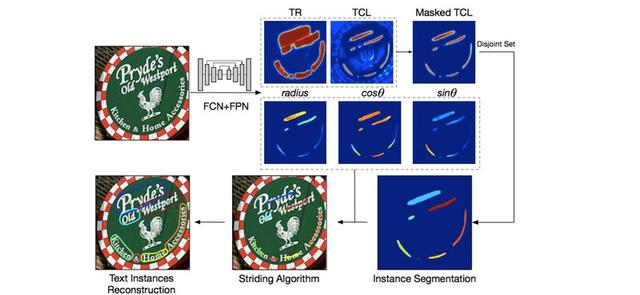 文章插图
文章插图Textsnake的输出以及文本框重建pipeline
Textsnake只需要文本框坐标来训练 。 事实上 , 训练TCL图不需要任何额外的标记 , 因为它的GT可以直接从边界框计算出来(更多细节见论文) 。
该算法可以在in the wild场景准确检测出复杂文本框的轮廓 。 下图b和c展示了Textsnake的将文本拉平的能力 。 它在稍微弯曲的文本实例上执行得非常好 。 但是 , 随着角度的增加 , 从“STARBUCKS”的首字母和尾字母可以看出 , 矫正的质量会下降 。
 文章插图
文章插图Textsnake的结果 , (a) 绿色: ground truth. 黄色: 检测到的文本轮廓 。 (b) 文本确认和矫正 。 (c) 和 (b) 一样 , 但是用的是我们自己的实现
文本识别文本识别主要有两种方法 , 都是使用CNN对图像进行预处理 , 然后使用RNN对文本进行解码 。
- JBL PARTYBOX ONTHEGO体验 转为派对打造
- play|“玩手机”用英文怎么说?play the phone?!
- 公司|小米道歉
- 监控平台选Prometheus还是Zabbix?
- 英威腾DA180-N带你开启EtherCAT总线新时代
- OLED屏已在准备!华为P50曝光
- 内存泄露原因找到了,罪魁祸首是Java TheadLocal
- Go 监控的标配:实战 Prometheus
- 教你使用Prometheus监控MySQL与MariaDB
- 本周末,来成都国际音响展聆听真力The Ones