新闻推荐系统源代码之推荐业务逻辑控制中心
 文章插图
文章插图
在前面的文章中 , 我们实现了召回和排序 , 接下来将进入推荐逻辑处理阶段 , 通常称为推荐中心 , 推荐中心负责接收应用系统的推荐请求 , 读取召回和排序的结果并进行调整 , 最后返回给应用系统 。 推荐中心的调用流程如下所示: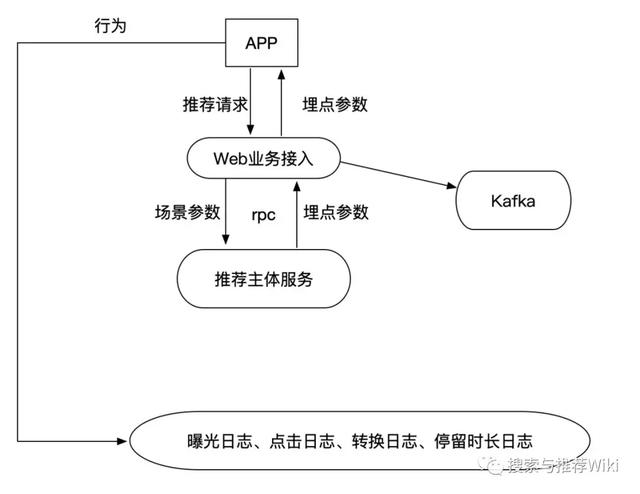 文章插图
文章插图
推荐接口设计通常推荐接口包括 Feed 流推荐和相似文章推荐
- Feed 流推荐:根据用户偏好 , 获取推荐文章列表(这里的时间戳用于区分是刷新推荐列表还是查看历史推荐列表) 参数:用户 ID , 频道 ID , 推荐文章数量 , 请求推荐的时间戳 结果:曝光参数 , 每篇文章的行为埋点参数 , 上一条推荐的时间戳
- 相似文章推荐:当用户浏览某文章时 , 获取该文章的相似文章列表 参数:文章 ID , 推荐文章数量 结果:文章 ID 列表
{"param": '{"action": "exposure", "userId": 1, "articleId": [1,2,3,4],"algorithmCombine": "c1"}',"recommends": [{"article_id": 1, "param": {"click": "{"action": "click", "userId": "1", "articleId": 1, "algorithmCombine": 'c1'}", "collect": "...", "share": "...","read":"..."}},{"article_id": 2, "param": {"click": "...", "collect": "...", "share": "...", "read":"..."}},{"article_id": 3, "param": {"click": "...", "collect": "...", "share": "...", "read":"..."}},{"article_id": 4, "param": {"click": "...", "collect": "...", "share": "...", "read":"..."}}]"timestamp": 1546391572}这里接口采用 gRPC 框架 , 在 user_reco.proto 文件中定义 Protobuf 序列化协议 , 其中定义了 Feed 流推荐接口:rpc user_recommend(User) returns (Track) {} 和相似文章接口:rpc article_recommend(Article) returns(Similar) {}syntax = "proto3";message User {string user_id = 1;int32 channel_id = 2;int32 article_num = 3;int64 time_stamp = 4;}// int32 ---> int64 article_idmessage Article {int64 article_id = 1;int32 article_num = 2;}message param2 {string click = 1;string collect = 2;string share = 3;string read = 4;}message param1 {int64 article_id = 1;param2 params = 2;}message Track {string exposure = 1;repeated param1 recommends = 2;int64 time_stamp = 3;}message Similar {repeated int64 article_id = 1;}service UserRecommend {rpc user_recommend(User) returns (Track) {}rpc article_recommend(Article) returns(Similar) {}}接着 , 通过如下命令生成服务端文件 user_reco_pb2.py 和客户端文件 user_reco_pb2_grpc.pypython -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. user_reco.proto定义参数解析类 , 用于解析推荐请求的参数 , 包括用户 ID、频道 ID、文章数量、请求时间戳以及算法名称class Temp(object):user_id = -10channel_id = -10article_num = -10time_stamp = -10algo = ""定义封装埋点参数方法 , 其中参数 res 为推荐结果 , 参数 temp 为用户请求参数 , 将推荐结果封装为在 user_reco.proto 文件中定义的 Track 结构 , 其中携带了文章对埋点参数 , 包括了事件名称、算法名称以及时间等等 , 方便后面解析用户对文章对行为信息def add_track(res, temp):"""封装埋点参数:param res: 推荐文章id列表:param temp: rpc参数:return: 埋点参数文章列表参数单文章参数"""# 添加埋点参数track = {}# 准备曝光参数# 全部字符串形式提供 , 在hive端不会解析问题_exposure = {"action": "exposure", "userId": temp.user_id, "articleId": json.dumps(res),"algorithmCombine": temp.algo}track['param'] = json.dumps(_exposure)track['recommends'] = []# 准备其它点击参数for _id in res:# 构造字典_dic = {}_dic['article_id'] = _id_dic['param'] = {}# 准备click参数_p = {"action": "click", "userId": temp.user_id, "articleId": str(_id),"algorithmCombine": temp.algo}_dic['param']['click'] = json.dumps(_p)# 准备collect参数_p["action"] = 'collect'_dic['param']['collect'] = json.dumps(_p)# 准备share参数_p["action"] = 'share'_dic['param']['share'] = json.dumps(_p)# 准备detentionTime参数_p["action"] = 'read'_dic['param']['read'] = json.dumps(_p)track['recommends'].append(_dic)track['timestamp'] = temp.time_stampreturn trackAB Test 流量切分由于推荐算法和策略是需要不断改进和完善等 , 所以 ABTest 也是推荐系统不可或缺的功能 。 可以根据用户 ID 将流量切分为多个桶(Bucket) , 每个桶对应一种排序策略 , 桶内流量将使用相应的策略进行排序 , 使用 ID 进行流量切分能够保证用户体验的一致性 。 通常 ABTest 过程如下所示: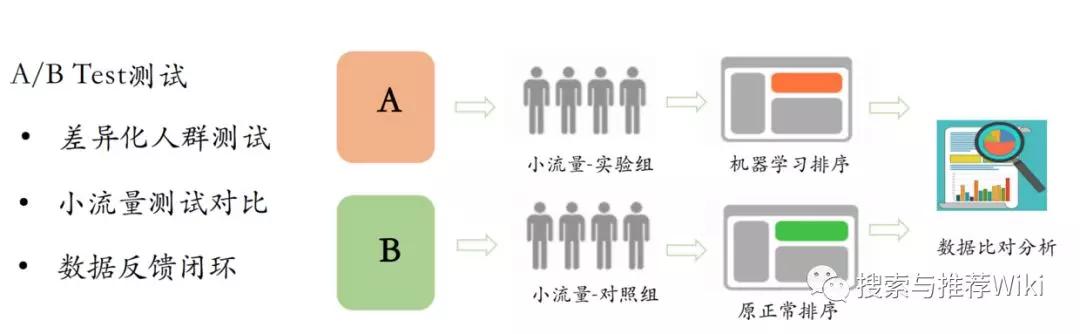 文章插图
文章插图通过定义 AB Test 参数 , 可以实现为不同的用户使用不同的推荐算法策略 , 其中 COMBINE 为融合方式 , RECALL 为召回方式 , SORT 为排序方式 , CHANNEL 为频道数量 , BYPASS 为分桶设置 , sort_dict 为不同的排序服务对象 。 可以看到 Algo-1 使用 LR 进行排序 , 而 Algo-2 使用 Wide&Deep 进行排序
- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- Win10系统桌面|手机桌面秒变Win10电脑系统,这波操作太给力了!
- 系统|电子邮箱系统哪家好?邮箱登陆入口是?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 计算机学科|机器视觉系统是什么
- 系统|vivo系统迎来“大换血”,OriginOS体验报告来了
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 智能手机|斗球新闻:Reliance Jio与Vivo合作在印度推出Jio独家智能手机
- 美国|知名科技博主:“想法采用曲线”与新闻媒体的未来