Apache|Uber 大规模运行 Apache Pinot实践
Pinot 是一个实时分布式的 OLAP 数据存储和分析系统。使用它实现低延迟可伸缩的实时分析。Pinot 从脱机数据源(包括 Hadoop 和各类文件)和在线数据源(如 Kafka)中获取数据进行分析。Pinot 被设计成可进行水平扩展。Pinot 特别适合这样的数据分析场景:查询具有大量维度和指标的时间序列数据、分析模型固定、数据只追加以及低延迟,以及分析结果可查询。本文介绍了 Pinot 在 Uber 的应用情况。
引言
Uber 有一个复杂的“市场”,由乘客、司机、食客、餐厅等组成。在全球范围内运营该市场需要实时的情报和决策。例如,识别延迟的 Uber Eats 订单或放弃的购物车有助于我们的社区运营团队采取纠正措施。对于日常运营、事件分类和财务情报来说,拥有一个包含不同事件的实时仪表板是至关重要的,这些事件包括消费者需求、司机可用性或城市中发生的行程等等。
在过去的几年里,我们已经建立了一个自主服务平台来支持这样的用例,以及 Uber 不同部门的许多其他用例。该平台的核心构件是 Apache Pinot,这是一个分布式的在线分析处理(OnLine Analytical Processing,OLAP)系统,该系统用于对 TB 级数据执行低延迟的分析查询。在本文中,我们介绍了这一平台的细节,以及它如何融入 Uber 的生态系统。我们重点介绍了 Pinot 在 Uber 内部的演变,以及我们如何从少数用例扩展到多集群,全主动部署,为数百个用例提供支持,以毫秒级的延迟查询 TB 级规模的数据。
用例概述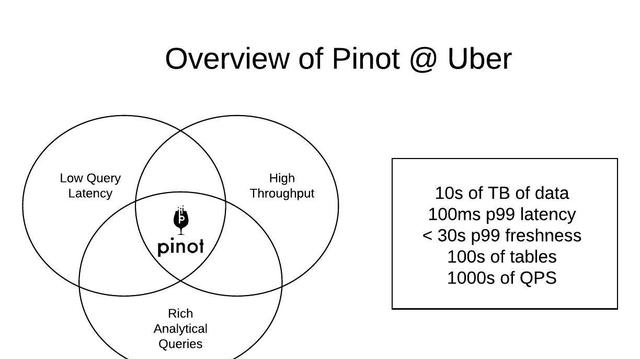
文章插图
上图描述了实时分析用例的典型需求。Uber 内部的不同用例可以分为以下几个大类:
仪表板
Uber 的许多工程团队使用 Ponot 为各自的产品构建定制的仪表板。 Uber Eats Restaurant Manager (餐厅经理)就是其中的一个例子: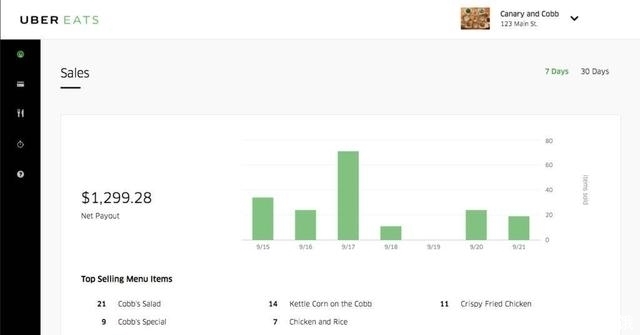
文章插图
这个仪表板可以让餐厅老板从 Uber Eats 订单中获得有关客户满意度、热门菜单、销售和服务质量分析的信息。Pinot 支持以不同的方式对原始数据进行切片和分片,并支持低延迟查询,从而为餐厅老板带来丰富的体验。
类似地,我们的城市运营团队已经构建了定制的仪表板,利用 Pinot 的实时和历史数据相结合的能力,获取供需、异常事件(例如,最近五分钟内延迟的订单)、实时订单等方面的指标。这是我们日常运营的重要工具,有助于及早发现问题。
分析应用程序
另一类用例源于作为许多后端服务的一部分执行分析查询的需求。这类用例的主要区别要求是数据的新鲜度和查询延迟,他们本质上需要是实时性的。例如,实时识别 Uber 乘客分组的地理热点对于良好的用户体验至关重要。同样,立即识别出司机取消或遗弃的 Uber Eats 购物车,可以快速采取纠正措施(以消息 / 奖励的形式)。
近实时探索
数据探索通常是在传统的批处理和仓库系统(如 Hadoop)上完成的。但是,有许多情况下,用户需要能够对实时数据执行复杂的 SQL 查询。例如,工程师经常需要通过加入微服务记录的各种事件来对事件进行分流。在其他情况下,实时时间可能需要与 Hive 中的批数据集连接。在 Uber 内部,我们在 Apache Pinot 之上提供了一个丰富的(Presto)SQL 接口,以开启对底层实时数据集上的探索。此外,该接口与我们所有的内部商业智能工具(如 Dashbuilder)无缝对接,这对我们所有的客户都非常有用。例如,下面是一张简单的 Sunburst 图表,显示了 Uber Eats 在五分钟内的订单明细,针对特定地区按工作状态分组。这是使用 Dashbuilder 通过在 Pinot 之上运行 Presto 查询在几秒钟之内构建的。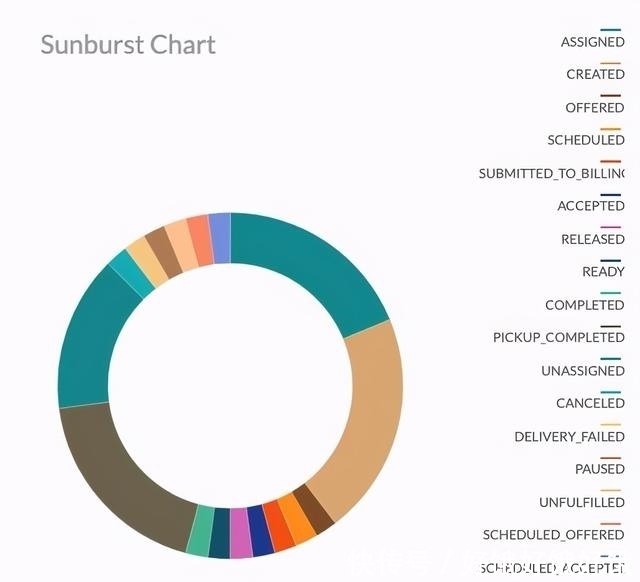
文章插图
今天,生产中数百个关键业务用例由 Apache Pinot 提供支持。在过去的几年里,我们已经从一个 10 节点的小型集群发展到每个区域数百个节点。由 Pinot 管理的总数据占用空间已经从早期的几十 GB 增长到今天的几十 TB。同样地,每个区域的每秒查询量也增加了 30 倍(今天生产中的每秒查询量高达数千次)。
在下面的章节中,我们将详细介绍我们的平台,讨论 Uber 对 Apache Pinot 做出的独特贡献,并详细阐述在大规模运营该平台的过程中所学到的经验教训。
Uber 的 Pinot 平台
为了服务这样的用例,我们围绕 Apache Pinot 构建了一个自助服务平台,如下图所示: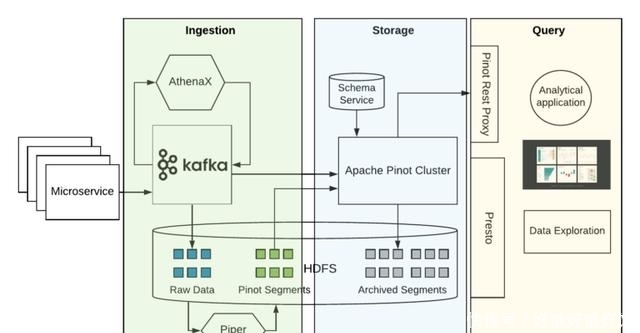
- 全自动|马斯克:特斯拉两周内大规模推送全自动驾驶(FSD)测试版
- 蔚来和小鹏|小鹏蔚来大规模断网,最后背锅的竟是中国移动
- 小基站带来新机遇!明年5G大规模室内建设将开始
- 大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率
- 腾讯云造了一个“智慧胶囊”,打开了5G大规模应用的大门
- Kubernetes 运维小记:node 为系统保留最低资源
- 在kubernetes中部署企业级ELK并使用其APM
- 部署|亚马逊云服务推出简化Apache Airflow部署与使用的托管服务
- Kubernetes上对应用程序进行故障排除的技巧
- 环闪|华为Mate40Pro环闪保护壳颇具创意,友商或大规模模仿