干货!分布式架构演进总结( 二 )
 文章插图
文章插图
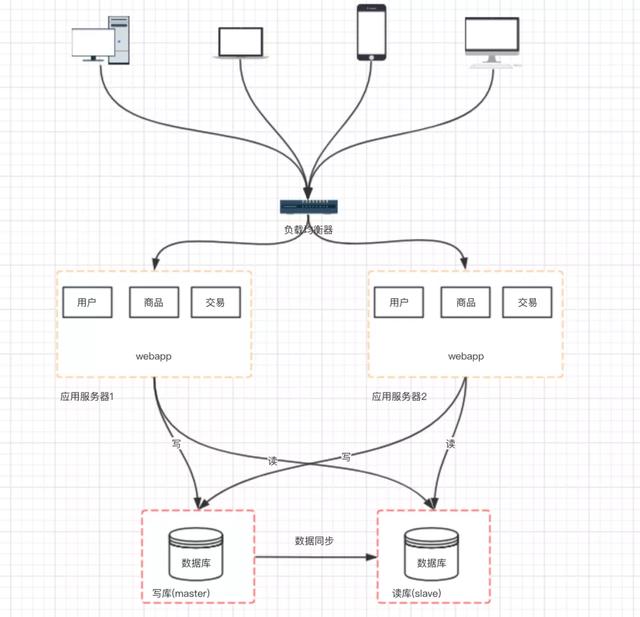
这个架构设计的变化会带来如下几个问题:
- 主从数据库之间的数据需要同步(可以使用 mysql 自带的 master-slave 方式实现主从复制 )
- 应用中需要根据业务进行对应数据源的选择( 采用第三方数据库中间件 , 例如 mycat )
 文章插图
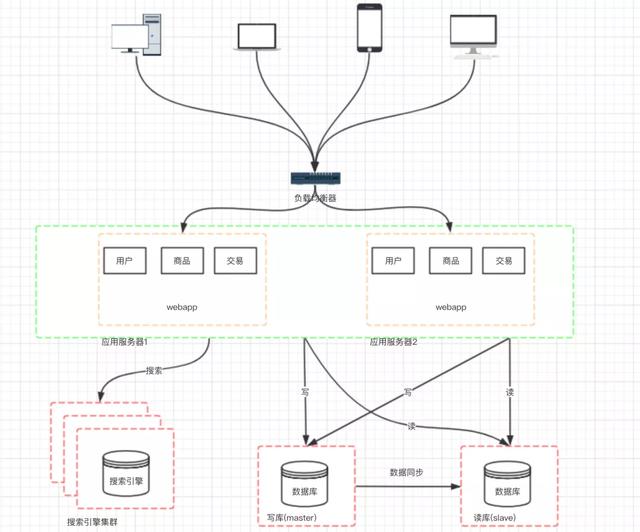
文章插图八、阶段六:引入缓存机制缓解数据库的压力然后 , 随着访问量的持续不断增加 , 逐渐会出现许多用户访问同一内容的情况 , 那么对于这些热点数据 , 没必要每次都从数据库重读取 , 这时我们可以使用到缓存技术 , 比如 redis、memcache 来作为我们应用层的缓存 。 另外在某些场景下 , 如我们对用户的某些 IP 的访问频率做限制 ,那这个放内存中就又不合适 , 放数据库又太麻烦了 , 那这个时候可以使用 Nosql 的方式比如 mongDB 来代替传统的关系型数据库 。
 文章插图
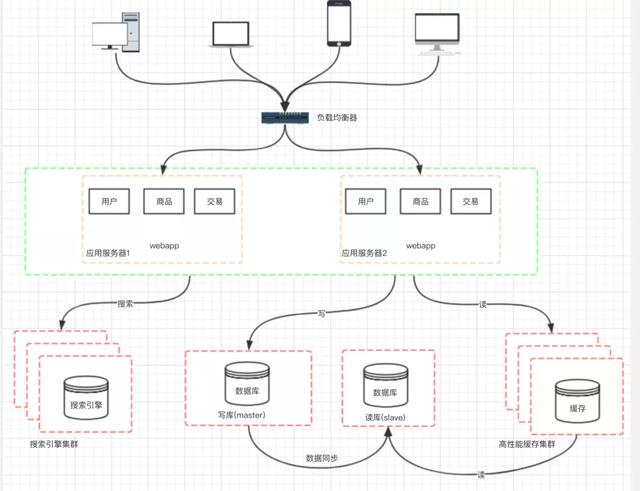
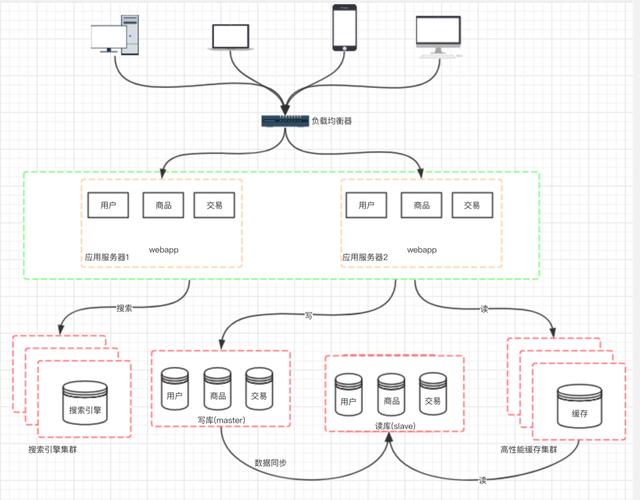
文章插图九、阶段七:数据库的水平/垂直拆分我们的网站演进的变化过程 , 交易、商品、用户的数据都还在同一 个数据库中 , 尽管采取了增加缓存 , 读写分离的方式 , 但是随着数 据库的压力持续增加 , 数据库的瓶颈仍然是个最大的问题 。 因此我 们可以考虑对数据的垂直拆分和水平拆分 。
 文章插图
文章插图垂直拆分:把数据库中不同业务数据拆分到不同的数据库 。
水平拆分:把同一个表中的数据拆分到两个甚至更多的数据库中 , 水平拆分的原因是某些业务数据量已经达到了单个数据库的瓶颈 , 这时可以采取将表拆分到多个数据库中 。
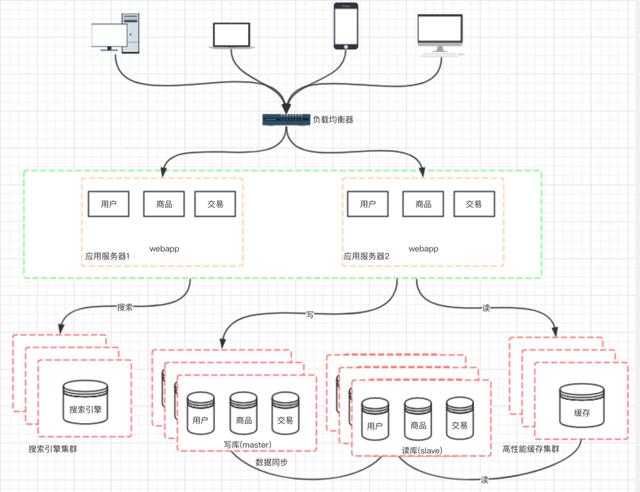 文章插图
文章插图十、阶段八:应用的拆分随着业务的发展 , 业务量越来越大 , 应用的压力越来越大 。 工程规模也越来越庞大 。 这个时候就可以考虑将应用拆分 , 按照领域模型将我们的用户、商品、交易拆分成多个子系统 。
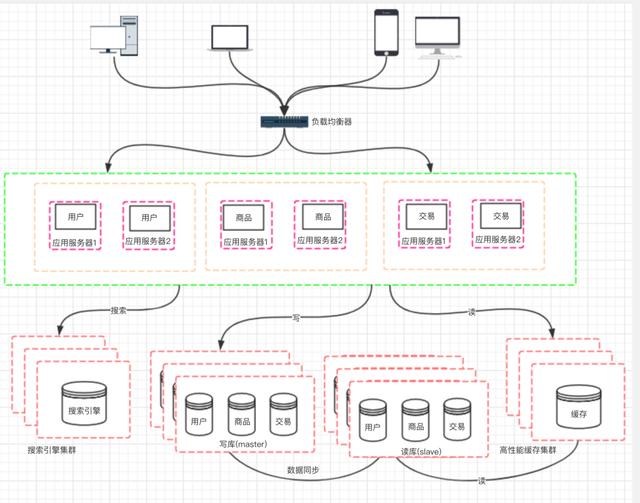 文章插图
文章插图这样拆分以后 , 可能会有一些相同的代码 , 比如用户操作 , 在商品和交易都需要查询 , 所以会导致每个系统都会有用户查询访问相关操作 。 这些相同的操作一定是要抽象出来 , 否则就是一个坑 。 所以通过走服务化路线的方式来解决 。
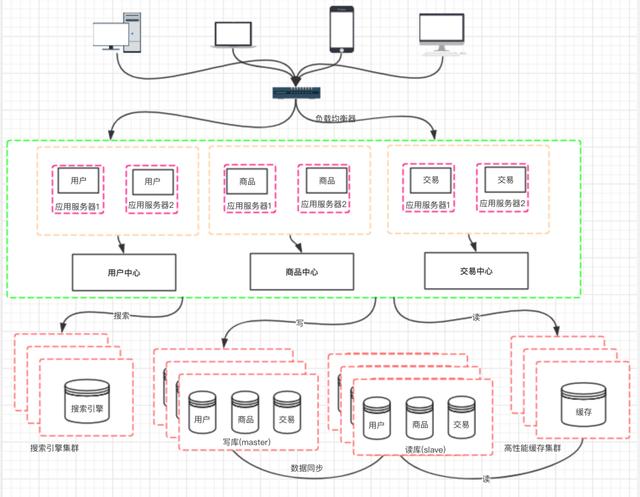 文章插图
文章插图那么服务拆分以后 , 各个服务之间如何进行远程通信呢? 通过 RPC 技术 , 比较典型的有:dubbo、webservice、hessian、http、RMI 等等 。 前期通过这些技术能够很好的解决各个服务之间通信问题 , 但是 ,互联网的发展是持续的 , 所以架构的演变和优化也还在持续 。
【干货!分布式架构演进总结】原文来自:作者:在途中#
- IT|信服云为IT基础架构演进提供新思路
- AI芯片“点燃”北京!GTIC 2020 AI芯片创新峰会大咖演讲全干货
- 高通骁龙888正式发布 首发Cortex X1架构集成5G基带
- 一款非常特殊的锐龙迷你:还是12nm Zen+架构
- 分布式锁的这三种实现90%的人都不知道
- 大小公司都适用的架构选型工具箱(涵盖上百个组件)
- 信服云为IT基础架构演进提供新思路
- 又爆新作!阿里甩出架构师进阶必备神仙笔记,底层知识全梳理
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- 关于Netty ByteBuf 的零拷贝