理论+实践,细谈MySQL中的explain执行计划之“谜”( 三 )
 文章插图
文章插图
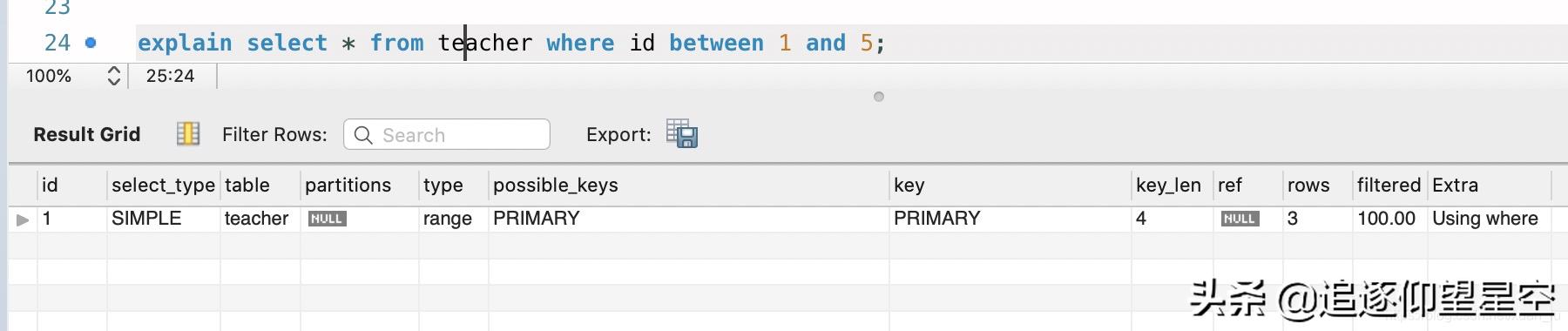
where 语句中使用主键索引作为条件 。
- eq_ref唯一性索引扫描 , 对于每个索引键 , 表中只有一条记录与之匹配 。 常见于主键或 唯一索引扫描 。 primarykey 或 unique key 索引的所有部分被连接使用 , 最多只会返回一条符合条件的记录 。 这可能是在 const 之外最好的连接类型了 , 简单的 select 查询不会出现这种 type 。
文章插图id列都是1 , 当id列值一样时 , 从上到下执行表 。 所以先执行class_teacher表 , 后执行class表 。
- ref相比 eq_ref , 不使用唯一索引 , 而是使用普通索引或者唯一性索引的部分前缀 , 索引要和某个值相比较 , 可能会找到多个符合条件的行 。
 文章插图
文章插图- range使用索引列检索指定范围 , where后面是一个范围查询(between and , in, > ,< ,>=) 。
 文章插图
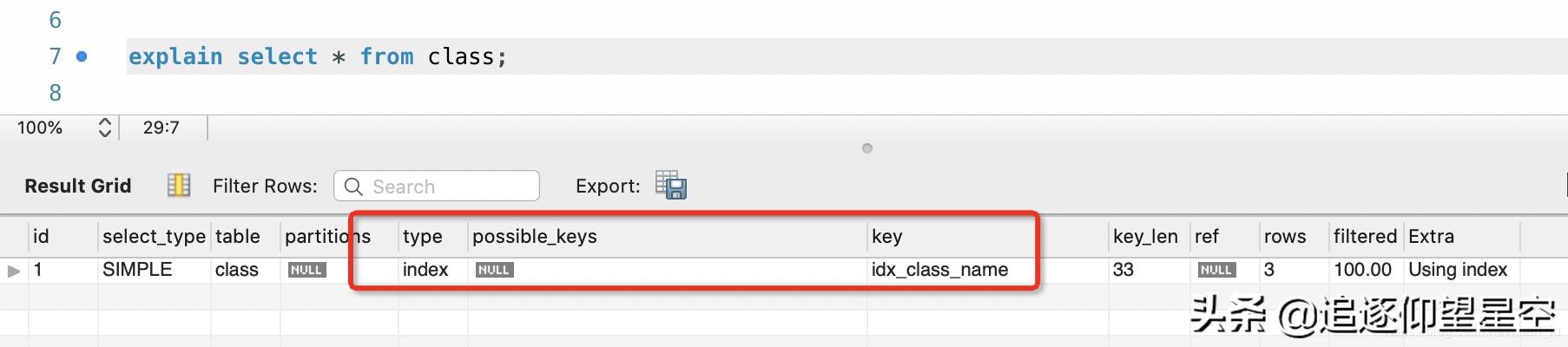
文章插图- index查询全部索引中的数据即只有索引树被扫描;因为索引文件通常比数据文件小,故通常比ALL快一些 。
 文章插图
文章插图注意:class表 , 上面创建表时 , 建立class_name索引;同样的查询用于teacher表中 , 便会全表扫描 。
- allMySQL将遍历全表以找到匹配的行 。 没有建立索引或索引失效 , 查询全表数据 , 开发中应尽量避免 。
 文章插图
文章插图possible_keys指出MySQL能使用哪些索引在表中找到记录 , 查询涉及到的字段上若存在索引 , 则该索引将被列出 , 但不一定被查询使用(该查询可以利用的索引 , 如果没有任何索引显示 null)
 文章插图
文章插图keykey列显示MySQL实际决定使用的键(索引) , 必然包含在possible_keys中如果没有选择索引 , 键是NULL 。 要想强制MySQL使用或忽视possible_keys列中的索引 , 在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX 。
 文章插图
文章插图key_len表示索引中使用的字节数 , 可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度 , 并非实际使用长度 , 即key_len是根据表定义计算而得 , 不是通过表内检索出的)不损失精确性的情况下 , 长度越短越好,长度越短 , 索引校验匹配效率越高 。
下面分别使用普通索引和联合索引看下key_len具体数值;
 文章插图
文章插图使用主键索引 , 使用字节数4;
 文章插图
文章插图使用联合索引 , key_len=8;
下面扩展一下key_len的计算规则:
1)字符串char(n):n字节长度;varchar(n):2字节存储字符串长度 , 如果是utf-8 , 则长度 3n + 2;2)数值类型tinyint:1字节smallint:2字节int:4字节bigint:8字节3)时间类型date:3字节timestamp:4字节datetime:8字节如果字段允许为 NULL , 需要1字节记录是否为 NULL 。 (这是为什么会比正常计算多1的原因) 。 索引最大长度是768字节 , 当字符串过长时 , MySql会做一个类似左前缀索引的处理 , 将前半部分的字符提取出来做索引 。 ref显示在key列索引中 , 表查找值所用到的列或常量 , 一般比较常见为const或字段名称 。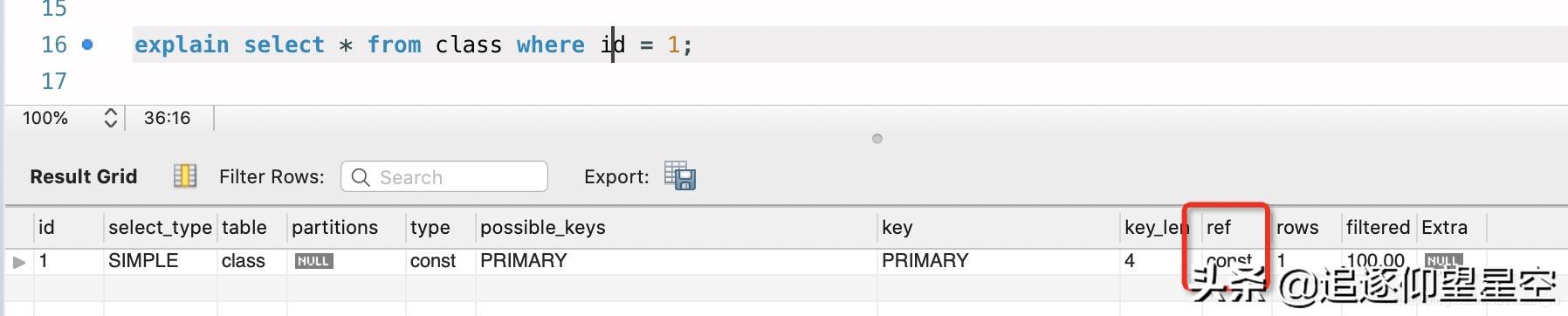 文章插图
文章插图rows估算出结果集行数 , 表示MySQL根据表统计信息及索引选用情况 , 估算的找到所需的记录所需要读取的行数 。
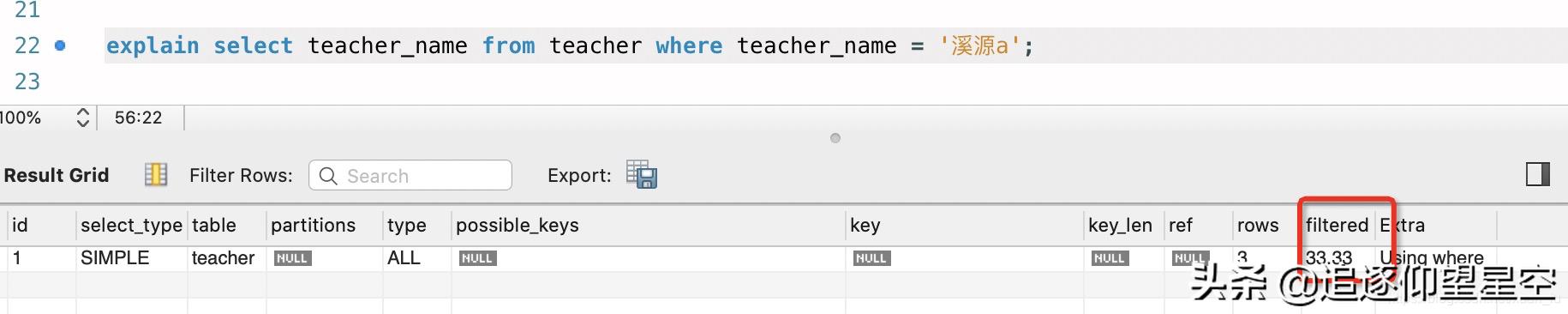
filtered指返回结果的行占需要读到的行(rows列的值)的百分比 。
 文章插图
文章插图从图中可以看到rows=3;指定数据溪源a记录数1条,故filtered = 1 / 3 * 100/100 = 33.33% , 保留两位小数 。
 文章插图
文章插图那这里为什么是1呢 , 因为覆盖索引列 , 不需要与全表对比;
Extra写到这里终于到最后一列啦 , 再坚持一下下~
- 混沌实施工具ChaosBlade实践
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- vivo|vivo影像+大师实践课的真正精髓:让更多人爱上手机影像
- 易观数科实践分享|教你 3 步快速搭建数据运营指标体系 | 观数
- 网易云音乐基于Flink实时数仓实践
- SpringCloud网关聚合Swagger接口文档实践
- 芦淞区第6届中小学生科技创新与实践技能大赛圆满闭幕
- 腾讯参与首届湾区创见安全大会,探讨云原生安全实践
- FedReID - 联邦学习在行人重识别上的首次深入实践
- 网易CI/CD实践(下):测试自动化及API版本管理