「轻阅读」基于 Flink SQL CDC的实时数据同步方案( 二 )
选择 Flink 作为 ETL 工具 当选择 Flink 作为 ETL 工具时 , 在数据同步场景 , 如下图同步结构: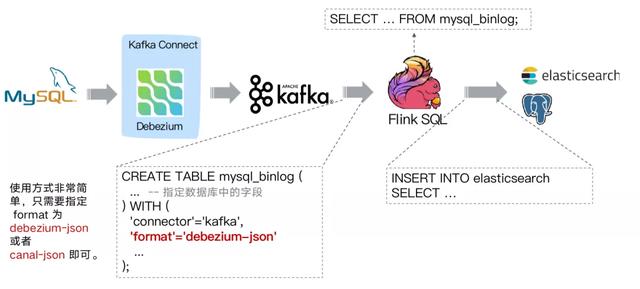 文章插图
文章插图
通过 Debezium 订阅业务库 MySQL 的 Binlog 传输至 Kafka, Flink 通过创建 Kafka 表指定 format 格式为 debezium-json, 然后通过 Flink 进行计算后或者直接插入到其他外部数据存储系统 , 例如图中的 Elasticsearch 和 PostgreSQL 。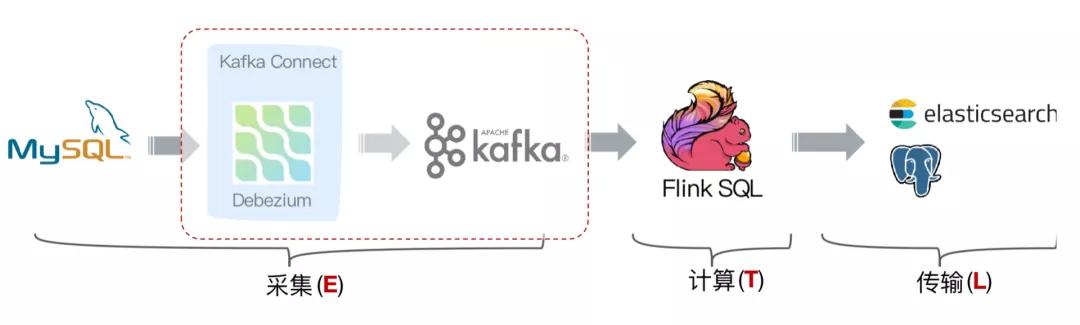 文章插图
文章插图
但是这个架构有个缺点 , 我们可以看到采集端组件过多导致维护繁杂 , 这时候就会想是否可以用 Flink SQL 直接对接 MySQL 的 binlog 数据呢 , 有没可以替代的方案呢?
答案是有的!经过改进后结构如下图: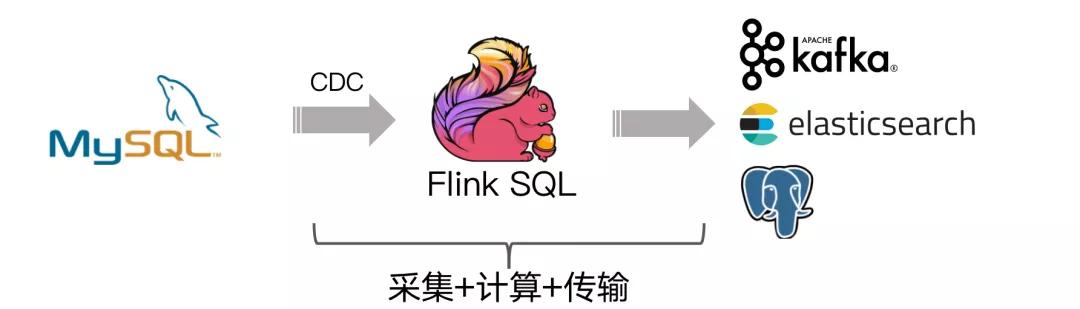 文章插图
文章插图
社区开发了 flink-cdc-connectors 组件 , 这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件 。 目前也已开源 , 开源地址:
flink-cdc-connectors 可以用来替换 Debezium+Kafka 的数据采集模块 , 从而实现 Flink SQL 采集+计算+传输(ETL)一体化 , 这样做的优点有以下:
- 开箱即用 , 简单易上手
- 减少维护的组件 , 简化实时链路 , 减轻部署成本
- 减小端到端延迟
- Flink 自身支持 Exactly Once 的读取和计算
- 数据不落地 , 减少存储成本
- 支持全量和增量流式读取
- binlog 采集位点可回溯*
数据同步方案实践
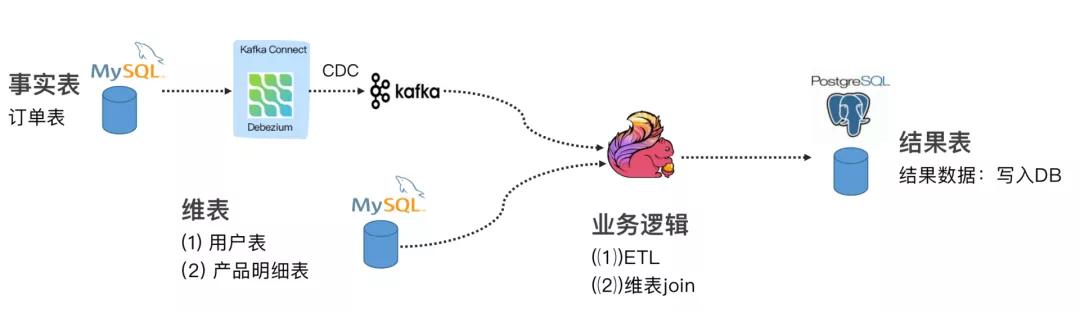
下面给大家带来 3 个关于 Flink SQL + CDC 在实际场景中使用较多的案例 。 在完成实验时候 , 你需要 Docker、MySQL、Elasticsearch 等组件 , 具体请参考每个案例参考文档 。 案例 1 : Flink SQL CDC + JDBC Connector这个案例通过订阅我们订单表(事实表)数据 , 通过 Debezium 将 MySQL Binlog 发送至 Kafka , 通过维表 Join 和 ETL 操作把结果输出至下游的 PG 数据库 。 具体可以参考 Flink 公众号文章:《Flink JDBC Connector:Flink 与数据库集成最佳实践》案例进行实践操作 。
 文章插图
文章插图案例 2 : CDC Streaming ETL模拟电商公司的订单表和物流表 , 需要对订单数据进行统计分析 , 对于不同的信息需要进行关联后续形成订单的大宽表后 , 交给下游的业务方使用 ES 做数据分析 , 这个案例演示了如何只依赖 Flink 不依赖其他组件 , 借助 Flink 强大的计算能力实时把 Binlog 的数据流关联一次并同步至 ES。
 文章插图
文章插图例如如下的这段 Flink SQL 代码就能完成实时同步 MySQL 中 orders 表的全量+增量数据的目的 。
CREATE TABLE orders (order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN) WITH ('connector' = 'mysql-cdc','hostname' = 'localhost','port' = '3306','username' = 'root','password' = '123456','database-name' = 'mydb','table-name' = 'orders');SELECT * FROM orders为了让读者更好地上手和理解 , 我们还提供了 docker-compose 的测试环境 , 更详细的案例教程请参考下文的视频链接和文档链接 。视频链接:
文档教程:
/wiki/中文教程
案例 3 : Streaming Changes to Kafka下面案例就是对 GMV 进行天级别的全站统计 。 包含插入/更新/删除 , 只有付款的订单才能计算进入 GMV, 观察 GMV 值的变化 。
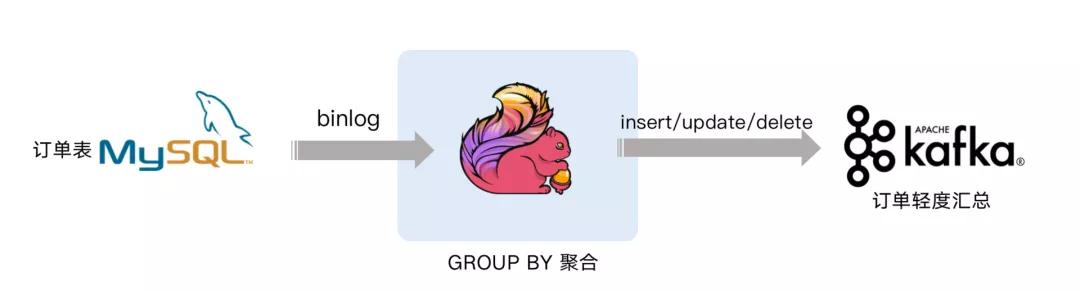 文章插图
文章插图视频链接:
文档教程:
/wiki/中文教程
Flink SQL CDC 的更多应用场景
Flink SQL CDC 不仅可以灵活地应用于实时数据同步场景中 , 还可以打通更多的场景提供给用户选择 。
Flink 在数据同步场景中的灵活定位
- 如果你已经有 Debezium/Canal + Kafka 的采集层 (E) , 可以使用 Flink 作为计算层 (T) 和传输层 (L)
- 也可以用 Flink 替代 Debezium/Canal, 由 Flink 直接同步变更数据到 Kafka , Flink 统一 ETL 流程
- 如果不需要 Kafka 数据缓存 , 可以由 Flink 直接同步变更数据到目的地 , Flink 统一 ETL 流程
- 实时数据同步 , 数据备份 , 数据迁移 , 数仓构建优势:丰富的上下游(E--tt-darkmode-color: #595959;">数据库之上的实时物化视图、流式数据分析
- 索引构建和实时维护
- 业务 cache 刷新
- 审计跟踪
- 微服务的解耦 , 读写分离
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 死亡|这届年轻人不讲武德,旧消费主义社会性死亡
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 轻松|使用 GIMP 轻松地设置图片透明度
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 确认|三星确认正在开发“轻薄轻巧”的可折叠手机
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- mini|电影、mini 与「当日完稿」工作流
- 字化转型|疫情重构经济,传统企业「数字化」的通关密码是什么?
- 产品|墨案Inkpad X超级阅读器:10英寸大屏,同品类号称无敌