方法|AWS Auto-Aug: 利用权重共享思想的新型自动数据增强方法解读( 二 )
在后期我们则会让分类器模型继承早期的共享权重,进行fine-tune和策略搜索:
由于早期训练使用的策略是共享策略,与搜索过程完全解耦,因此共享权重只需训练一次即可用于后续的全部搜索,显著提升了搜索效率。我们将这一权重共享思想称为“Augmentation-wiseWeightSharing”。
于是当前问题转化为:如何选取具有代表性的共享策略?经过推导发现,一个均匀分布下的策略,可以使单独训练和共享训练的增强操作采样分布之间的KL散度最小。至此,我们便可以得到完整的AWS Auto-Aug搜索算法: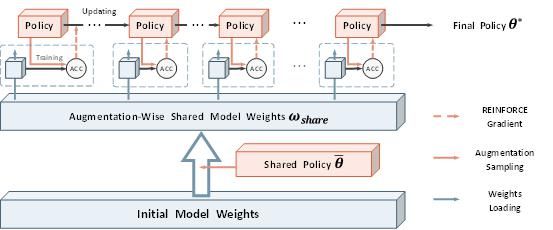
文章插图
2.搜索空间与搜索策略
为了与先前工作进行更公平的对比,我们选择了与其几乎一致的搜索空间(我们甚至在搜索空间中去掉了更强大的增强操作:Cutout与Sample Pairing)。对于搜索策略,由于我们提出的方法是通用的,任何启发式搜索算法均适用。实验中我们发现PPO强化学习算法(也是Google AutoAug使用的算法)已经有了足够好的表现。
实验结果
1.表现对比
我们在3个最主流的图像分类数据集和4个主流模型上进了算法表现对比。结果如下,在各数据集、各模型上我们均取得了最优表现;尤其是在未使用额外数据的CIFAR-10上,在我们搜索得到的数据增强策略下,PyramidNet取得了新的SOTA性能(旧的SOTA性能为Adv. AA [2] 策略下的PyramidNet):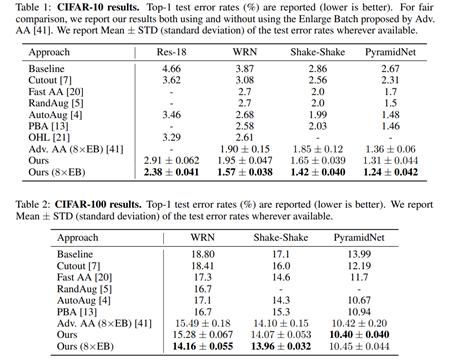
文章插图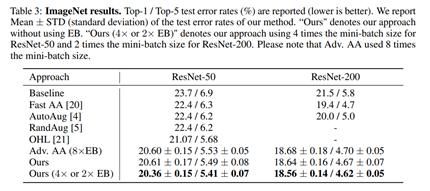
文章插图
2.时间开销对比
我们以OHL AutoAug [3] 的时间开销为基准(1x),以WideResNet-28x10在CIFAR-10上使用Cutout的错误率为基准(0%),对比各方法的时间开销和相对误差降低如下。可见我们的方法在可接受的计算量内取得了很好的表现。
3.代理任务可靠性对比
为了验证我们所选择代理任务相比其他代理任务的高可靠性,我们计算了在搜索过程中取得的准确度和最终准确度的相关性,结果如图所示: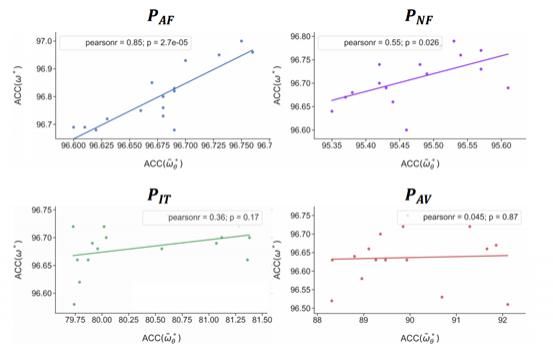
文章插图
4.消融实验
为了验证我们搜索得到的策略的有效性,我们将我们的策略和Google AutoAug的策略中概率最高的增强操作逐个去除,并观察性能的变化。结果如下表所示,可见我们搜索得到的策略确实更有效。
5.搜索过程展示
最后,我们还展示了我们的策略分布在整个搜索过程中的变化。如下图所示(左右分别对应CIFAR-10、ImageNet),增强操作在最初均为均匀分布(图中做了平滑);随着搜索进程推进,多数操作的概率开始趋向0,而为数不多的数个操作的概率则不断增大,体现出分化的过程。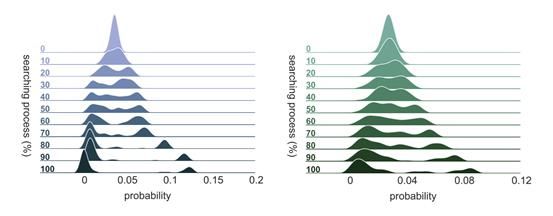
文章插图
结语
招聘信息
References
[1] Cubuk, Ekin D., et al. "Autoaugment: Learning augmentation policies from data."arXiv preprint arXiv:1805.09501(2018).
[2] Zhang, Xinyu, et al. "Adversarial autoaugment."arXiv preprint arXiv:1912.11188(2019).
[3] Lin, Chen, et al. "Online hyper-parameter learning for auto-augmentation strategy."Proceedings of the IEEE International Conference on Computer Vision. 2019.
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 空间|垃圾文件正在吞噬你的C盘空间用这四种方法,还你一个干净的C盘
- 工程师|AWS偏爱Rust,已将Rust编译器团队负责人收入囊中
- 值得|安全419宝典:如何做好文档的安全管理 这4个方法值得借鉴
- 框架|三种数据分析思维框架的构建方法
- 方法|财付通关联公司申请账单催收方法、装置及电子设备的专利
- 账单|财付通申请“账单催收方法、装置及电子设备”专利
- 大小|如何将皮料剪切成想要大小?制作皮具几种裁剪工具和使用方法!
- 打印机的共享设置方法,简单6部搞定!
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程