埋点模型|如何科学地输出一份的埋点需求文档?( 三 )
例:以购买成功为例看事件的触发逻辑。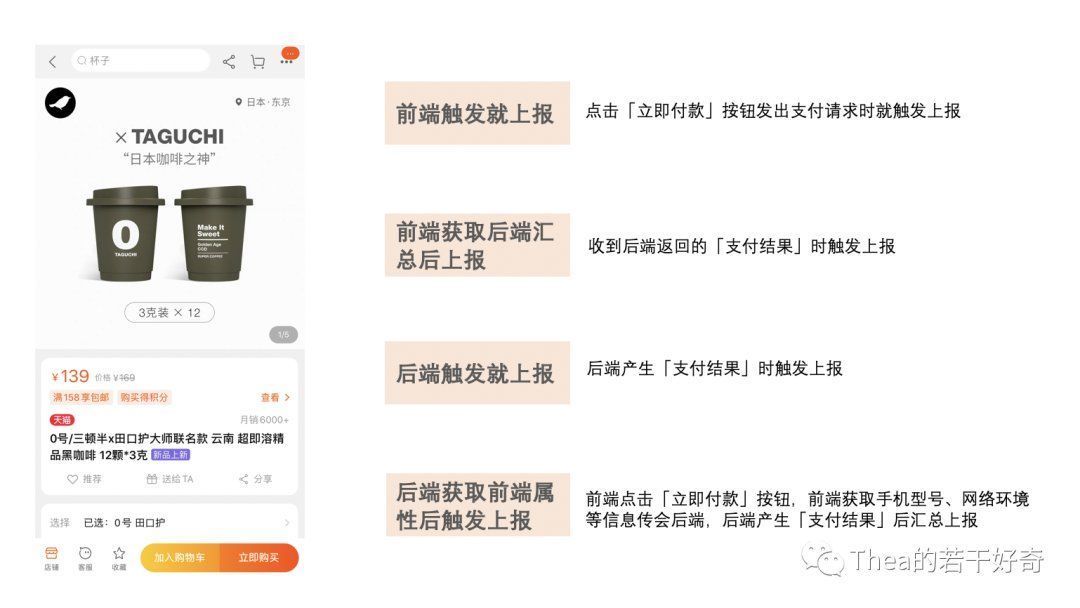
文章插图
前端触发就上报:点击「立即付款」按钮就触发,这是最常见的前端采集方式,如果业务方是想了解「用户是否有意愿支付」,那么当用户点击「支付订单」这个按钮或者发出支付请求就采集即可。
前端获取后端汇总后上报:这种方式一般是由于除了记录用户操作外,还需要获取用户操作的结果;比如需要收到后端结果的返回,以判断用户是否支付成功,以及失败情况下具体的报错原因,那么其触发机制必须等到前端拿到后端服务器处理结果后,再进行上报。
后端触发就上报:这种方式是指后端处理后直接上报,比如后端处理付款请求出结果时直接后端触发上报;采用这种方式的主要好处是数据不会出现漏报,但也由于是后端直接上报,基本是拿不到用户的设备终端及软硬件环境属性的,比如用户在支付时使用的是什么设备、网络环境是什么等信息。
后端获取前端属性且触发上报:这种情况就是为了解决后端埋点的软硬件环境属性问题,让前端在用户点击「立即支付」时,将相应的属性一并传回服务器,服务器发生「支付成功」时,带上相应的前端属性上报数据;当然这种方式理论上时数据准确度、完备性最高的,但同时这种方式的采集成本会比较高,意味着所有端的前后端接口需要做变更,建议是只在数据准确性、前端属性获取两个需求都非常强烈时采用。
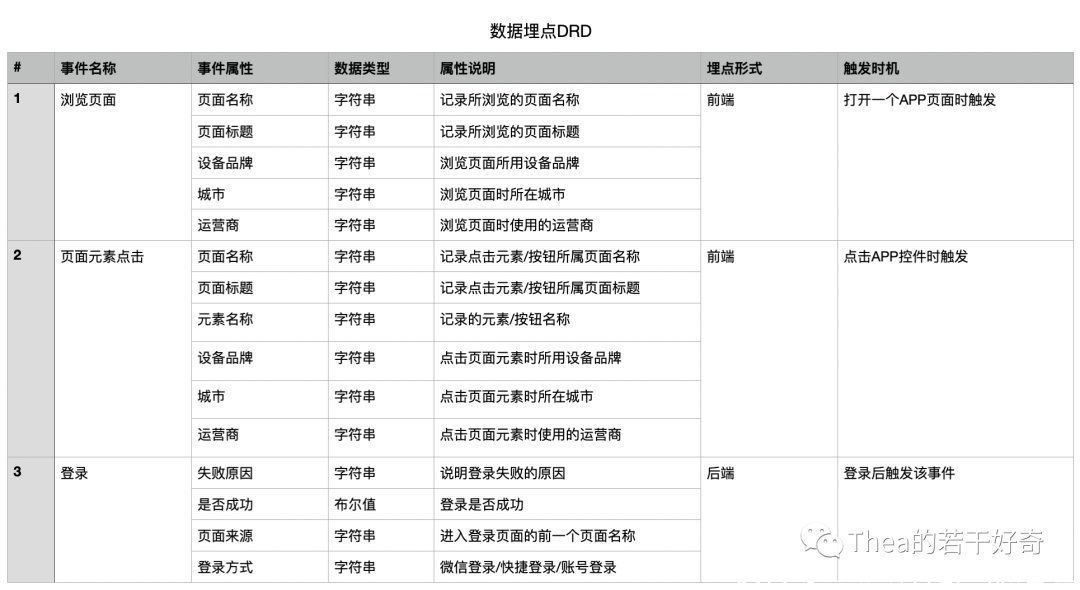
4. 属性设计埋点设计的最后一步是在每个事件下设计包含的属性,这里的属性到后续的数据分析中,就是维度和修饰词,对应到 SQL 查询语句中就是 where 和 group by。
回到电商搜索的例子,要深入分析用户对不同商品的需求情况、不同关键词的健康度,需要对比分析不同关键词的数据表现;那么关于关键词的维度属性,例如关键词内容、关键词分类(推荐词、热门词)等属性就非常关键。
需要强调的是——在属性设计时,除了维度全面之外,还必须保证每个属性都是独立采集,比如关键词分类和关键词内容不能合并为一个字段采集,以保证后续灵活的下钻分析;一般可以把属性分为用户属性、事件属性、对象属性、环境属性,下面列举出每个分类下常见的属性,供大家参考。
当然,要想把属性设计好,关键是要对业务场景和数据分析的诉求非常熟悉,知道哪些维度会影响业务的数据表现。
- 用户属性:用户ID、新老用户、活跃天数等
- 事件属性:前向页面、功能入口、操作方式等
- 对象属性:商品名称、商品分类、商品金额等
- 环境属性:设备型号、平台、城市、运营商等
文章插图
三、数据埋点,一次讲个够这是《数据埋点,一次讲个够》系列文章的第二篇,第一篇讨论了数据埋点体系建设的三个核心问题,点击阅读:当我们在谈论数据埋点时,我们在谈论些什么?
这一系列的文章会和大家系统地分享我对埋点体系建设的实践与思考,后续的文章会进一步和大家讨论这些问题:
- 如何让业务线的产品/运营更高效地提埋点需求?
- 如何更快的响应业务需求,输出 DRD?
- 如何设计更简洁、更灵活、拓展性更强的埋点模型?
- 如何协调好参与埋点工作的各方,快速产出高质量的埋点?
- 如何有效地管理成千上万个已线上、未上线、需要下线的埋点?
Thea,微信公众号:Thea的若干好奇;从事大数据产品工作六年,设计、管理埋点已有三年,经手过上万个埋点,经历过从 0 到 1 自建埋点体系,也使用过第三方的埋点服务。
本文由@Thea 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐