面试阿里被质问:ConcurrentHashMap线程安全吗( 二 )
2.2 bug 分析ConcurrentHashMap就像是一个大篮子 , 现在这个篮子里有900个桔子 , 我们期望把这个篮子装满1000个桔子 , 也就是再装100个桔子 。 有10个工人来干这件事儿 , 大家先后到岗后会计算还需要补多少个桔子进去 , 最后把桔子装入篮子 。ConcurrentHashMap这篮子本身 , 可以确保多个工人在装东西进去时 , 不会相互影响干扰 , 但无法确保工人A看到还需要装100个桔子但是还未装时 , 工人B就看不到篮子中的桔子数量 。 你往这个篮子装100个桔子的操作不是原子性的 , 在别人看来可能会有一个瞬间篮子里有964个桔子 , 还需要补36个桔子 。
ConcurrentHashMap对外提供能力的限制:
- 使用不代表对其的多个操作之间的状态一致 , 是没有其他线程在操作它的 。 如果需要确保需要手动加锁
- 诸如size、isEmpty和containsValue等聚合方法 , 在并发下可能会反映ConcurrentHashMap的中间状态 。 因此在并发情况下 , 这些方法的返回值只能用作参考 , 而不能用于流程控制 。 显然 , 利用size方法计算差异值 , 是一个流程控制
- 诸如putAll这样的聚合方法也不能确保原子性 , 在putAll的过程中去获取数据可能会获取到部分数据
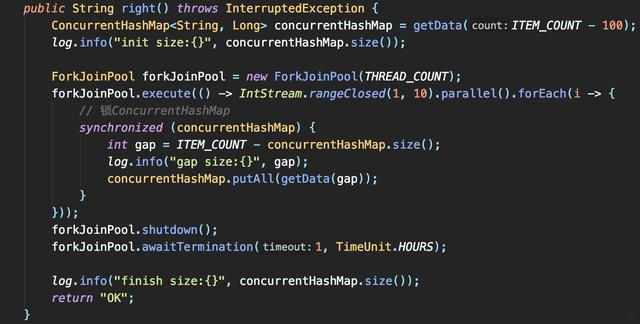 文章插图
文章插图- 只有一个线程查询到需补100个元素 , 其他9个线程查询到无需补 , 最后Map大小1000
ConcurrentHashMap提供了一些原子性的简单复合逻辑方法 , 用好这些方法就可以发挥其威力 。 这就引申出代码中常见的另一个问题:在使用一些类库提供的高级工具类时 , 开发人员可能还是按照旧的方式去使用这些新类 , 因为没有使用其真实特性 , 所以无法发挥其威力 。
3 知己知彼 , 百战百胜3.1 案例使用Map来统计Key出现次数的场景 。
- 使用ConcurrentHashMap来统计 , Key的范围是10
- 使用最多10个并发 , 循环操作1000万次 , 每次操作累加随机的Key
- 如果Key不存在的话 , 首次设置值为1 。
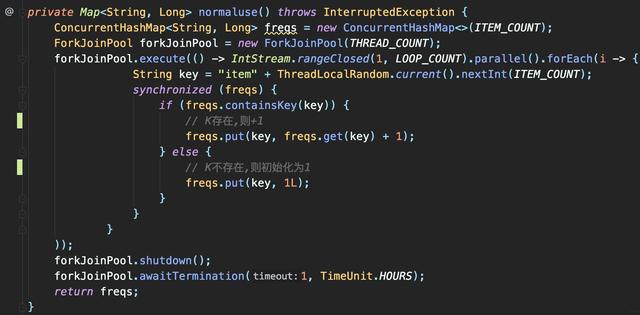 文章插图
文章插图有了上节经验 , 我们这直接锁住Map , 再做
- 判断
- 读取现在的累计值
- +1
- 保存累加后值
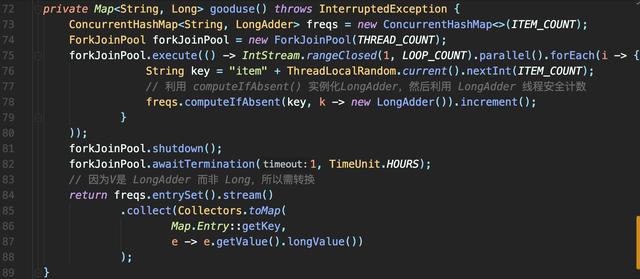 文章插图
文章插图- ConcurrentHashMap的原子性方法computeIfAbsent做复合逻辑操作 , 判断K是否存在V , 若不存在 , 则把Lambda运行后结果存入Map作为V , 即新创建一个LongAdder对象 , 最后返回V 因为computeIfAbsent返回的V是LongAdder , 是个线程安全的累加器 , 可直接调用其increment累加 。
3.2 性能测试
- 使用StopWatch测试两段代码的性能 , 最后的断言判断Map中元素的个数及所有V的和是否符合预期来校验代码正确性
- 性能测试结果:
3.3 computeIfAbsent高性能之道Java的Unsafe实现的CAS 。它在JVM层确保写入数据的原子性 , 比加锁效率高:
static final boolean casTabAt(Node[] tab, int i,Node c, Node v) {return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);} 所以不要以为只要用了ConcurrentHashMap并发工具就是高性能的高并发程序 。辨明 computeIfAbsent、putIfAbsent
- 当Key存在的时候 , 如果Value获取比较昂贵的话 , putIfAbsent就白白浪费时间在获取这个昂贵的Value上(这个点特别注意)
- Key不存在的时候 , putIfAbsent返回null , 小心空指针 , 而computeIfAbsent返回计算后的值
- 当Key不存在的时候 , putIfAbsent允许put null进去 , 而computeIfAbsent不能 , 之后进行containsKey查询是有区别的(当然了 , 此条针对HashMap , ConcurrentHashMap不允许put null value进去)
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 面临|“熟悉的陌生人”不该被边缘化
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 美国|印度宣布彻底突破5G难关,美英加澳一片欢呼,一周后白宫怒斥被骗
- 责令|1336款APP被责令整改,三大问题突出
- iPhone|接近8千万!苹果被罚款了!中国iPhone用户这次真的该生气了!
- 误导|苹果又吃巨额罚单,因iPhone防水宣传有误导被重罚9400万
- 覆盖|iPhone13Pro概念机:机身正面被屏幕全覆盖,库克想搞事情?
- 敢动|女生最害怕被“偷看”的3软件,QQ不算啥,第二敢动就“翻脸”