运维必备:Zookeeper集群“脑裂”问题处理大全( 二 )
如果假设我们现在只有5台机器 , 也部署在两个机房: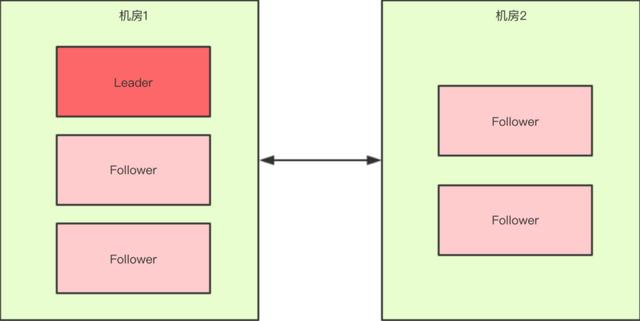 文章插图
文章插图
图3
此时过半机制的条件是 "节点数 > 2" , 也就是至少要3台服务器才能选出一个Leader 。
此时机房件的网络断开了 , 对于机房1来说是没有影响的 , Leader依然还是Leader;对于机房2来说是选不出来Leader的 , 此时整个集群中只有一个Leader 。
因此总结得出 , 有了过半机制 , 对于一个Zookeeper集群来说 , 要么没有Leader , 要么只有1个Leader , 这样Zookeeper也就能避免了脑裂问题 。
三、 Zookeeper集群"脑裂"问题处理
1、什么是脑裂?
简单点来说 , 脑裂(Split-Brain) 就是比如当你的 cluster 里面有两个节点 , 它们都知道在这个 cluster 里需要选举出一个 master 。 那么当它们两个之间的通信完全没有问题的时候 , 就会达成共识 , 选出其中一个作为 master 。
但是如果它们之间的通信出了问题 , 那么两个结点都会觉得现在没有 master , 所以每个都把自己选举成 master , 于是 cluster 里面就会有两个 master 。
对于Zookeeper来说有一个很重要的问题 , 就是到底是根据一个什么样的情况来判断一个节点死亡down掉了?在分布式系统中这些都是有监控者来判断的 , 但是监控者也很难判定其他的节点的状态 , 唯一一个可靠的途径就是心跳 , 所以Zookeeper也是使用心跳来判断客户端是否仍然活着 。
使用ZooKeeper来做Leader HA基本都是同样的方式:
- 每个节点都尝试注册一个象征Leader的临时节点 , 其他没有注册成功的则成为follower , 并且通过watch机制 (这里有介绍) 监控着leader所创建的临时节点;
- Zookeeper通过内部心跳机制来确定leader的状态 , 一旦Leader出现意外Zookeeper能很快获悉并且通知其他的follower , 其他flower在之后作出相关反应 , 这样就完成了一个切换 。 这种模式也是比较通用的模式 , 基本大部分都是这样实现的 。
Leader其实并未死掉 , 但是与ZooKeeper之间的网络出现问题导致Zookeeper认为其挂掉了然后通知其他节点进行切换 , 这样follower中就有一个成为了Leader 。
但是原本的Leader并未死掉 , 这时候client也获得Leader切换的消息 , 仍然会有一些延时 , Zookeeper通讯需要一个一个通知 。
这时候整个系统在混乱中 , 很有可能有一部分client已经通知到了连接到新的Leader上去了 , 而有的client仍然连接在老的Leader上 。
如果同时有两个client需要对Leader的同一个数据更新 , 并且刚好这两个client此刻分别连接在新老的Leader上 , 就会出现很严重问题 。
这里做下小总结:
- 假死:由于心跳超时(网络原因导致的)认为Leader死了 , 但其实leader还存活着;
- 脑裂:由于假死会发起新的Leader选举 , 选举出一个新的Leader , 但旧的Leader网络又通了 , 导致出现了两个Leader, 有的客户端连接到老的Leader , 而有的客户端则连接到新的leader 。
主要原因是Zookeeper集群和Zookeeper client判断超时并不能做到完全同步 , 也就是说可能一前一后 , 如果是集群先于client发现 , 那就会出现上面的情况 。
同时 , 在发现并切换后通知各个客户端也有先后快慢 。 一般出现这种情况的几率很小 , 需要Leader节点与Zookeeper集群网络断开 , 但是与其他集群角色之间的网络没有问题 , 还要满足上面那些情况 , 但是一旦出现就会引起很严重的后果 , 数据不一致 。
3、Zookeeper是如何解决"脑裂"问题的?
要解决Split-Brain脑裂的问题 , 一般有下面几种种方法:
- Quorums (法定人数) 方式: 比如3个节点的集群 , Quorums = 2, 也就是说集群可以容忍1个节点失效 , 这时候还能选举出1个lead , 集群还可用 。 比如4个节点的集群 , 它的Quorums = 3 , Quorums要超过3 , 相当于集群的容忍度还是1 , 如果2个节点失效 , 那么整个集群还是无效的 。 这是Zookeeper防止"脑裂"默认采用的方法;
- Redundant communications (冗余通信)方式:集群中采用多种通信方式 , 防止一种通信方式失效导致集群中的节点无法通信 。
- Fencing (共享资源) 方式:比如能看到共享资源就表示在集群中 , 能够获得共享资源的锁的就是Leader , 看不到共享资源的 , 就不在集群中 。
- 运维|全栈智能业务运维服务商云智慧完成 D3 轮 6000 万美元融资
- 领跑|云智慧完成D3轮6000万美元融资,继续领跑智能运维市场
- 又爆新作!阿里甩出架构师进阶必备神仙笔记,底层知识全梳理
- windows上必备的四款软件,一旦试用欲罢不能,建议收藏
- 安卓面试必备的JVM虚拟机制详解,看完之后简历上多一个技能
- 装机必备!解压缩神器Bandizip中文免费版|电脑软件
- 小米热卖米家耳温计实测:测温快,数值准,宝爸宝妈必备
- Kubernetes 运维小记:node 为系统保留最低资源
- 秋冬必备,一分钟暖脚神器:左点小仙智能蒸足器Z8使用体验
- 阿里内部Java应届生就业宝典,打摆子统统必备,内容太全面