谷歌联手DeepMind提出Performer:用新方式重新思考注意力机制( 二 )
性能
我们首先对Performer的空间和时间复杂度进行基准测试 , 结果表明 , 注意力加速和内存减少几乎是最优的 , 也就是说 , 结果非常接近于在模型中根本不使用注意力机制 。
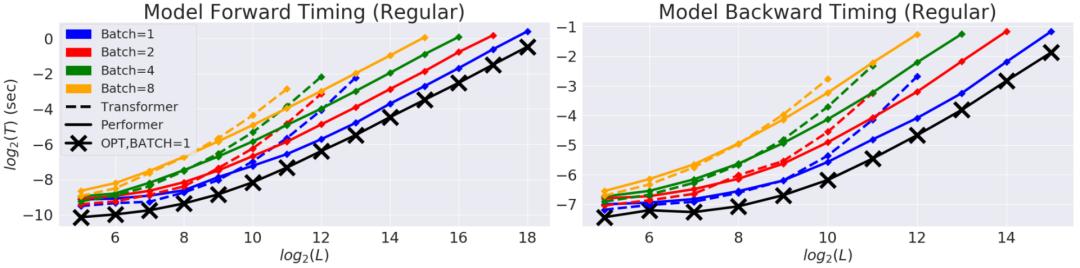 文章插图
文章插图
研究人员又进一步展示了 Performer , 使用无偏 softmax 逼近 , 向后兼容经过一点微调的预训练Transformer模型 , 可以通过提高推断速度降低成本 , 而不需要完全重新训练已有的模型 。
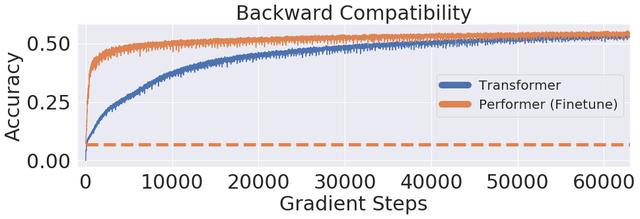 文章插图
文章插图
案例:蛋白质序列建模
蛋白质是具有复杂三维结构和特定功能的大分子 , 对生命来说至关重要 。 与单词一样 , 蛋白质被指定为线性序列 , 其中每个字符是20个氨基酸构建块中的一个 。
将 Transformers 应用于大型未标记的蛋白质序列产生的模型可用于对折叠的功能性大分子进行准确的预测 。
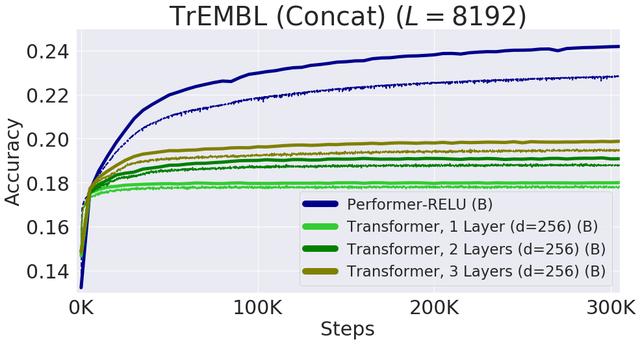
Performer-ReLU (使用基于 relu 的注意力 , 这是一个不同于 softmax 的广义注意力)在蛋白质序列数据建模方面有很强的表现 , 而 Performer-Softmax 与 Transformer 的性能相匹配 , 正如理论所预测的结果那样 。
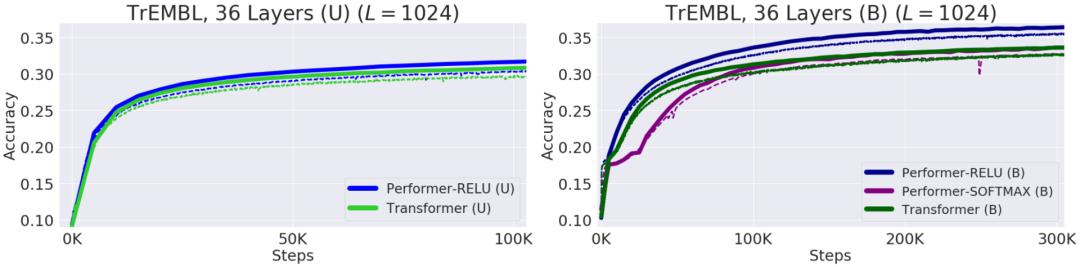 文章插图
文章插图
下面 , 我们可视化一个蛋白质Performer模型 , 使用基于 relu 的近似注意力机制进行训练 , 使用 Performer 来估计氨基酸之间的相似性 , 从序列比对中分析进化替换模式得到的替换矩阵中恢复类似的结构 。
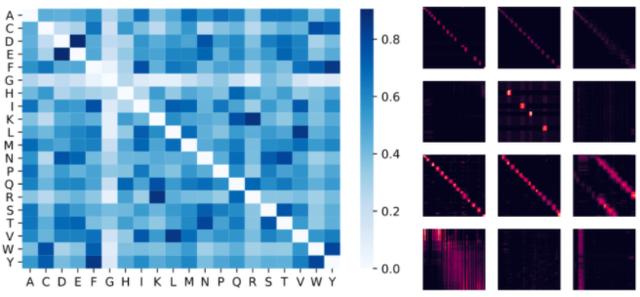 文章插图
文章插图
更一般地说 , 我们发现局部和全局注意力机制与用蛋白质数据训练的Transformer模型一致 。 Dense Attention的近似Performer有可能捕捉跨越多个蛋白质序列的全局相互作用 。
 文章插图
文章插图
作为概念的验证 , 对长串联蛋白质序列进行模型训练 , 会使得常规 Transformer 模型的内存过载 , 但 Performer模型的内存不会过载 , 因为它的空间利用很高效 。
结论
Google AI的这项工作有助于改进基于非稀疏的方法和基于Kernel的Transformer , 这种方法也可以与其他技术互操作 , 研究人员甚至还将 FAVOR 与Reformer的代码集成在一起 。 同时研究人员还提供了论文、 Performer的代码和蛋白质语言模型的代码链接 。
Google AI的研究人员相信 , 他们对于Performer的研究开辟了一种关于Attention、Transformer架构甚至Kernel的全新的思维方式 , 对于进一步的改进有巨大的启示作用 。 文章插图
文章插图
- 联手|政企联动、市区联手,共享计划促进大中小企业融通发展
- Facebook|谷歌、Facebook未来几周将面临更多的反垄断诉讼
- 谷歌|小米10i惊现谷歌商店,网友:这不就是我们的Redmi Note 9?
- 搞事|法国人又搞事了!将命令谷歌、脸书、亚马逊等科技公司支付数字税
- 机构|英拟设新机构监管谷歌等科技巨头
- 反垄断|好日子到头?谷歌等美企将面临美国4起诉讼,30国已站在对立面
- 倡议|谷歌、FB等签署新倡议承诺积极缴税,亚马逊、苹果缺席
- 产业带|拼多多计划5年扶持100个产业带 联手5000家制造企业共创新品牌
- 反垄断|谷歌和Facebook或于明年1月在美面临新的反垄断诉讼
- 解决|谷歌人工智能解决蛋白质折叠问题