技术分享 | MySQL:count(*)、count(字段) 实现上区别( 二 )
bool Item_sum_count::add(){if (aggr->arg_is_null(false))return 0;count++;return 0;}END LOOP
最终我们只需要返回这个计数就可以了 。 下面是发送的数据 , 断点可以设置在 Query_result_send::send_data 中 。
$22 = Item::SUM_FUNC_ITEM(gdb) p ((Item*)(items)->first->info)->field_type()$23 = MYSQL_TYPE_LONGLONG(gdb) p ((Item*)(items)->first->info)->val_int()$24 = 3(gdb) p (items)->first->info$26 = (void *) 0x7ffe7c006580(gdb) p ((Item_sum_count*)$26)->count$28 = 3我们可以发送的数据实际就是这个计数器 , 最终值为 3 。
三、示例中 count(c) 获取数据流程的不同实际上整个流程基本一致 , 但是区别在于:
- 构建的 read_set 不同 , 模板个数自然不同 , 因为需要 2 个字段 , 即 b、c 两个字段 , 其中 b 列用于 where 条件过滤 , 而 b 列用于统计是否有 NULL 值 , 因此模板数量为 2 , 如下:
(gdb) p prebuilt->n_template$29 = 2- 做 COUNT 计数器的时候会根据 c 列的 NULL 值做实际的过滤 , 操作只要是 NULL 则 count 计数不会增加 1 , 这个还是参考这段代码:
bool Item_sum_count::add(){if (aggr->arg_is_null(false)) //过滤NULL值return 0;count++;return 0;}最终会调入函数 Field::is_null 进行 NULL 值判断 , 断点可以设置在这里 。四、不同点总结示例中的语句 count(c) 返回为 0 。 现在我们很清楚了 , 这些数据什么时候过滤掉的 , 总结如下:
- Innodb 层返回了全部的行数据 。
- MySQL 层通过 where 条件过滤 , 剩下了 b='g' 的行 。
- MySQL 层通过 NULL 判断 , 将剩下的 count(c) 中为 NULL 的行也排除在计数之外 。
然后的不同点就是在返回的字段上:
- count(c) 很明显除了 where 条件以外 , 还需要返回 c 列给 MySQL 层
- count(*) 则不需要返回额外的字段给 MySQL 层 , 只需要 MySQL 层过滤需要的b列即可 。
五、备用栈帧(下图需点击放大查看)NULL 值计数过滤栈帧
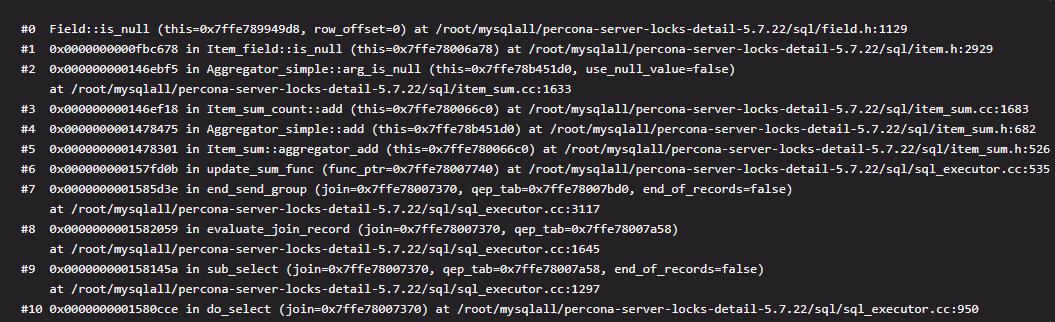 文章插图
文章插图最后推荐高鹏的专栏《深入理解 MySQL 主从原理 32 讲》 , 想要透彻了解学习 MySQL 主从原理的朋友不容错过 。
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 中国|浅谈5G移动通信技术的前世和今生
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 视频社会生产力报告|视频社会雏形已成,绿厂或凭这技术抢占先机
- 职工组一等|全国人工智能应用技术技能大赛落幕 青岛四名选手获一等奖
- 中国视频|人日评论点赞!OPPO成视频手机先行者,新技术或下月发布
- 介绍|5分钟介绍各种类型的人工智能技术
- 重庆市工业互联网技术创新战略联盟:构建万物互联智能工厂 助力先进制造发展
- 热点功能|旧手机别乱处理,分享旧手机6个小妙用,放在家里好值钱