自监督式特征增强在大图像目标检测中的应用( 二 )
A、 网络体系结构
SFANet 的整体结构如图 2 所示 。 黄色虚线框中的组件为本文提出的 。 所提出的引导特征上采样模块位于主干网的自底向上路径之后 , 学习从大尺寸图像中提取的特征 C1 来引导的每一级({C2-C5})上采样特征 。 学习到的特征({F2-F5})被送入第二条自顶向下的路径 , 最后进入检测块 。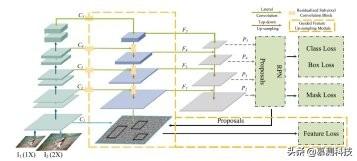 文章插图
文章插图
图二 SFANet 的整体结构
B、 引导特征上采样模块
使用特征上采样进行目标检测可以提高检测性能减少内存和计算开销 。 因此 , 我们提出了一个引导特征上采样模块 。 我们设计了如图 2 所示的引导特征上采样模块(用黄色虚线框标记) , 以有效地改进目标检测的特征表示 。 我们引入大尺寸图像特征作为辅助监督 , 通过特征上采样进行学习 。
我们采用横向上采样和自顶向下上采样 。 自上而下的路径将特征映射迭代到 F2 。 这些特征通过横向上采样的自底向上路径特征得到增强 。
C、 剩余亚像素卷积块
【自监督式特征增强在大图像目标检测中的应用】我们设计了一个残存的亚像素卷积块 , 将自上而下和横向连接路径有效地连接到上采样特征 。 与反卷积层进行特征上采样的方法不同 , 我们的方法采用亚像素卷积层对特征地图进行上采样 。 图 3 详细说明了这两种方法之间的区别 。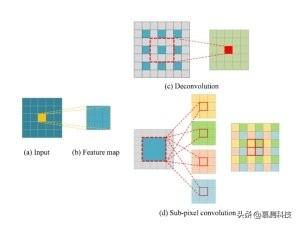 文章插图
文章插图
图 3 反卷积和亚像素卷积层如何进行上采样过程的比较 。
(a) 输入像素
(b) 3×3 卷积后输出特征图
(c) 反卷积
(d)亚像素卷积是两种不同的特征上采样方式 。
图 3(b)是图 3(a)与 3×3 核卷积后的结果 。 反卷积层(图 3(c))首先填充零(标记为灰色正方形) , 然后执行标准卷积 。 上采样要素图中的中心元素是从红色虚线框中的元素获得的 , 该框中只有一个元素(用蓝色填充) 。 与反卷积层相比 , 亚像素卷积层(图 3(d))首先使用 3×3×4 内核将信息嵌入到信道中 , 然后周期性地重新排列以生成一个放大的映射 。 使用图 3(b)中的所有元素计算中心区域中的每个元素 。
4、 实验我们采用基于 Pytorch 的 mmdetection 开源代码来训练网络 。 在实验中对于每个图像 , 我们采样 512 个 RoIs , 默认的正色调负比为 1:3 。 权重衰减设置为 00001 。实验在三个数据集上进行 , 分别是 MVD、Cityscapes 和 COCO 。
MVD 实验(一)数据集和指标:MVD 是一种新的街道级图像数据集 , 在天气和照明条件以及捕捉传感器特征方面具有多样性 。 该数据集包含大约 25k 个高分辨率图像 。 平均短边约为 2500 像素 。
(二)主要结果:图 5 中的验证子集上展示了我们方法的语义分段结果 。 文章插图
文章插图
图四 基于 MVD-val 子集的 SFANet 语义分割结果
Cityscapes 实验(一)数据集和指标:Cityscapes 是另一个流行的数据集 , 包含车载摄像头拍摄的街道场景 , 图像大小为 1024×2048 。 总共有 2975 个训练图像 , 500 个验证图像和 1525 个带有精细注释的测试图像 。 另一个 20k 图像具有粗略的注释 。
(二)结果和性能:我们使用从[800×1024]随机抽样的图像尺度(短边)进行训练 。 结果显示 , 我们的方法优于所有其他方法 。 我们将我们提出的模型与其他基于 FPN 的方法相结合 , 进一步验证了我们方法的有效性 。
COCO 实验1) 数据集和指标:COCO 数据集是实例分割和对象检测中最具挑战性和最受欢迎的数据集之一 。 它包含 115k 个用于培训的图像和 5k 个用于验证的图像 。
2) 结果和性能:我们将所有其他方法的输入尺度设置为 800 , 并使用从[400×800]随机抽样的尺度来验证所提出的自我监督特征增强 。 结果表明 , 我们的方法能够以较高的效率获得可比的结果 。
5、结论本文研究了目标检测流中图像尺寸的影响 , 提出了一种主要面向超大图像的 SFANet 。 从上采样特征和引入高分辨率图像信息的角度 , 设计了引导特征上采样模块 。 该模块通过使用所提出的残存亚像素卷积块来提升特征 , 并通过添加引导特征丢失分支引入高分辨率信息 。 特征上采样模块的目的是在大特征的监督下 , 以较小的网络输入学习与大图像匹配的实体特征 。 我们在 MVD 和城市景观上进行了多个实验 , 以证明该管道的有效性 。
本论文由 iSE 实验室 2019 级硕士生徐彬桐转述 。
- 商品|问道自有品牌,山姆多方博弈
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 自动|碳博士控股子公司推出最新款自动驾驶清扫车
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 公式|?有人把 5G 讲得这么简单明了
- 表达|重磅!2021世界安防博览会官方宣贯会正式召开,百余家企业表达参展意愿
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- YFI正式宣布与Sushiswap合作|金色DeFi日报 | 合作
- 小店|抖音小店无货源是什么?与传统模式有什么区别?
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”