技术分享 | 大数据量更新,回滚效率提升方法
【技术分享 | 大数据量更新,回滚效率提升方法】作者:周启超
爱可生北分团队 DBA , 主要负责项目前期建设及后期疑难问题支持 。 做事认真 , 对事负责 。
本文来源:原创投稿
*爱可生开源社区出品 , 原创内容未经授权不得随意使用 , 转载请联系小编并注明来源 。
我们经常会遇到操作一张大表 , 发现操作时间过长或影响在线业务了 , 想要回退大表操作的场景 。 在我们停止大表操作之后 , 等待回滚是一个很漫长的过程 , 尽管你可能对知道一些缩短时间的方法 , 处于对生产环境数据完整性的敬畏 , 也会选择不做介入 。 最终选择不作为的原因大多源于对操作影响的不确定性 。 实践出真知 , 下面针对两种主要提升事务回滚速度的方式进行验证 , 一种是提升操作可用内存空间 , 一种是通过停实例 , 禁用 redo 回滚方式进行进行验证 。
仔细阅读过官方手册的同学 , 一定留意到了对于提升大事务回滚效率 , 官方提供了两种方法:一是增加 innodb_buffer_pool_size 参数大小 , 二是合理利用 innodb_force_recovery=3 参数 , 跳过事务回滚过程 。 第一种方式比较温和 , innodb_buffer_pool_size 参数是可以动态调整的 , 可行性也较高 。 第二种方式相较之下较暴力 , 但效果较好 。
下面我们看下第一种方式的效果如何:
mysql>set global innodb_buffer_pool_size = 1073741824;Query OK, 0 rows affected (0.00 sec)mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> use sbtest;Database changedmysql> update sbtest1 set k=k+1;Query OK, 16023947 rows affected (7 min 23.23 sec)Rows matched: 16023947Changed: 16023947Warnings: 0mysql>mysql> set global innodb_buffer_pool_size = 5368709120;Query OK, 0 rows affected (0.00 sec)mysql> show variables like '%uffer_pool%';+-------------------------------------+----------------+| Variable_name| Value|+-------------------------------------+----------------+| innodb_buffer_pool_chunk_size| 134217728|| innodb_buffer_pool_dump_at_shutdown | ON|| innodb_buffer_pool_dump_now| OFF|| innodb_buffer_pool_dump_pct| 25|| innodb_buffer_pool_filename| ib_buffer_pool || innodb_buffer_pool_instances| 8|| innodb_buffer_pool_load_abort| OFF|| innodb_buffer_pool_load_at_startup| ON|| innodb_buffer_pool_load_now| OFF|| innodb_buffer_pool_size| 5368709120|+-------------------------------------+----------------+10 rows in set (0.02 sec)mysql> rollback;Query OK, 0 rows affected (6 min 39.41 sec)最初更新操作用时 7 min 23.23 sec 回滚操作用时 6 min 39.41 sec 相较于更新操作回滚操作耗时缩短了将近一分钟 , 效果似乎并不显著 。
当然回滚时间和更新操作时间进行对比不太严谨 , 下面对不同大小 innodb_buffer_pool_size 条件情况下更新和回滚操作时间进行一个汇总 。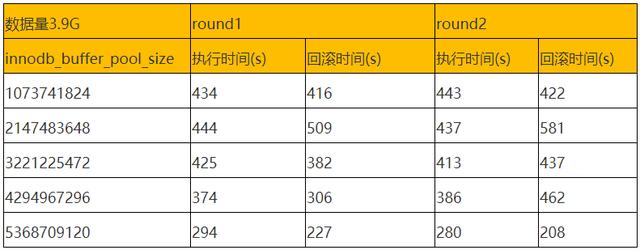 文章插图
文章插图 文章插图
文章插图
我们可以看到 innodb_buffer_pool_size 设置大于数据量大小时 , 大表操作时间才会有较明显的下降 。
实验的时候会发现 /opt/mysql/data/3400/ibdata1 系统表空间操作较多 , 这是在进行 double write 操作 。
# pt-ioprofile --profile-pid=7777 --aggregate=sum --cell=count --group-by=filename --save-samples=5.txt --run-time=500Sun Oct 11 12:55:35 UTC 2020Tracing process ID 7777totalreadpwrite64writefsyncopenlseek filename12287069410534600 /opt/mysql/data/3400/ibdata15010000501000 /opt/mysql/data/3400/sbtest/sbtest1.ibd4837004837000 /opt/mysql/tmp/3400/MLfgQmPl22910372013610558 /opt/mysql/data/3400/undo00310660421064500 /opt/mysql/log/redolog/3400/ib_logfile04101011 /opt/mysql/data/3400/mysql/slow_log.CSV1001000 /opt/mysql/data/3400/mysql-slow.log# pt-ioprofile --profile-pid=7777 --aggregate=sum --cell=count --group-by=filename --save-samples=6.txt --run-time=500Sun Oct 11 13:07:44 UTC 2020Tracing process ID 7777totalreadpread64pwrite64writefsynclseekftruncate filename112060064530475300 /opt/mysql/data/3400/ibdata1451503000448500 /opt/mysql/data/3400/sbtest/sbtest1.ibd12660100126500 /opt/mysql/data/3400/undo00391400361055300 /opt/mysql/log/redolog/3400/ib_logfile031001010 /opt/mysql/data/3400/mysql/slow_log.CSV30001011 /opt/mysql/tmp/3400/MLfgQmPl10001000 /opt/mysql/data/3400/mysql-slow.log禁用 double write 并不能给性能带来性能提升 。
如下为统计信息: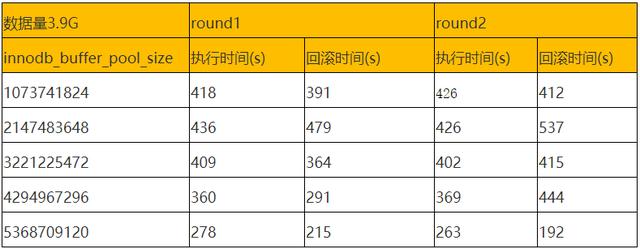 文章插图
文章插图 文章插图
文章插图
通过验证 , 在做大数据量操作临时调大 innodb_buffer_pool_size 对大事务更新和回滚是有一定效果的 。
第二种方法操作流程如下:
kill -9 MySQL 进程;备份 MySQL 数据及日志目录;为 mysql server 设置 innodb_force_recovery=3 参数;然后启动 MySQL 进程;正常关闭 MySQL Server 进程;去掉 innodb_force_recovery=3 参数启动 MySQL 进程 。 完成恢复过程 。 (innodb_force_recovery 这个参数一般用于"严重故障排除场景" , 生产环境慎用 , 若用于生产环境需首先明确 innodb_force_recovery 设置对现有环境数据可能的影响情况) 。
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 痛点|首个OTA智能社区诞生 解决行业四大痛点
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 长安|长安傍上华为这个大腿,市值暴涨500亿!可见华为影响力之大?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞