手把手教你基于深度学习构建推荐系统( 二 )
下面的代码将使用"留一法leave-one-out"方法将我们的收视率数据集划分为训练和测试集 。
ratings['rank_latest'] = ratings.groupby(['userId'])['timestamp'].rank(method='first', ascending=False)train_ratings = ratings[ratings['rank_latest'] != 1]test_ratings = ratings[ratings['rank_latest'] == 1]# drop columns that we no longer needtrain_ratings = train_ratings[['userId', 'movieId', 'rating']]test_ratings = test_ratings[['userId', 'movieId', 'rating']]将数据集转换为隐式反馈数据集如前所述 , 我们将使用隐式反馈来训练推荐系统 。但是 , 我们正在使用的MovieLens数据集基于显式反馈 。要将此数据集转换为隐式反馈数据集 , 我们只需对评分进行二值化并将其转换为" 1"(即肯定类别) 。值" 1"表示用户已与商品进行了互动 。
重要的是要注意 , 使用隐式反馈会重新构造我们的推荐程序试图解决的问题 。我们不是在使用显式反馈时尝试预测电影收视率 , 而是在尝试预测用户是否将与每部电影进行交互(即点击/购买/观看) , 以向用户展示具有最高交互可能性的电影 。
train_ratings.loc[:, 'rating'] = 1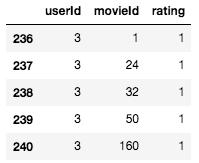 文章插图
文章插图
我们现在确实有问题 。对数据集进行二值化后 , 我们看到数据集中的每个样本现在都属于正类 。但是 , 我们还需要负样本来训练我们的模型 , 以指示用户尚未与之互动的电影 。我们假设这类电影是用户不感兴趣的电影 , 尽管这可能是不正确的假设 , 但通常在实践中效果很好 。
下面的代码为每行数据生成4个负样本 。换句话说 , 阴性样本与阳性样本的比率为4:1 。该比率是任意选择的 , 但我发现它在实践中效果很好(您可以自行找到最佳比率!) 。
# Get a list of all movie IDsall_movieIds = ratings['movieId'].unique()# Placeholders that will hold the training datausers, items, labels = [], [], []# This is the set of items that each user has interaction withuser_item_set = set(zip(train_ratings['userId'], train_ratings['movieId']))# 4:1 ratio of negative to positive samplesnum_negatives = 4for (u, i) in user_item_set:users.append(u)items.append(i)labels.append(1) # items that the user has interacted with are positivefor _ in range(num_negatives):# randomly select an itemnegative_item = np.random.choice(all_movieIds)# check that the user has not interacted with this itemwhile (u, negative_item) in user_item_set:negative_item = np.random.choice(all_movieIds)users.append(u)items.append(negative_item)labels.append(0) # items not interacted with are negative赞! 现在 , 我们具有模型所需格式的数据 。在继续之前 , 我们先定义一个PyTorch数据集以方便训练 。下面的类将我们上面编写的代码简单地封装到PyTorch Dataset类中 。
import torchfrom torch.utils.data import Datasetclass MovieLensTrainDataset(Dataset):"""MovieLens PyTorch Dataset for TrainingArgs:ratings (pd.DataFrame): Dataframe containing the movie ratingsall_movieIds (list): List containing all movieIds"""def __init__(self, ratings, all_movieIds):self.users, self.items, self.labels = self.get_dataset(ratings, all_movieIds)def __len__(self):return len(self.users)def __getitem__(self, idx):return self.users[idx], self.items[idx], self.labels[idx]def get_dataset(self, ratings, all_movieIds):users, items, labels = [], [], []user_item_set = set(zip(ratings['userId'], ratings['movieId']))num_negatives = 4for u, i in user_item_set:users.append(u)items.append(i)labels.append(1)for _ in range(num_negatives):negative_item = np.random.choice(all_movieIds)while (u, negative_item) in user_item_set:negative_item = np.random.choice(all_movieIds)users.append(u)items.append(negative_item)labels.append(0)return torch.tensor(users), torch.tensor(items), torch.tensor(labels)我们的模型-神经协同过滤(NCF)虽然有很多基于深度学习的推荐系统架构 , 但我发现He等人提出的框架 。是最简单的方法 , 它足够简单 , 可以在这样的教程中实现 。
用户嵌入在深入研究模型的体系结构之前 , 让我们熟悉一下嵌入的概念 。嵌入是一个低维空间 , 可捕获高维空间中矢量的关系 。为了更好地理解这一概念 , 让我们仔细研究一下用户嵌入 。
想象一下 , 我们想根据用户对两类电影的喜好来代表他们—动作和浪漫电影 。假设第一维度是用户喜欢动作片的程度 , 第二维度是用户喜欢浪漫片的程度 。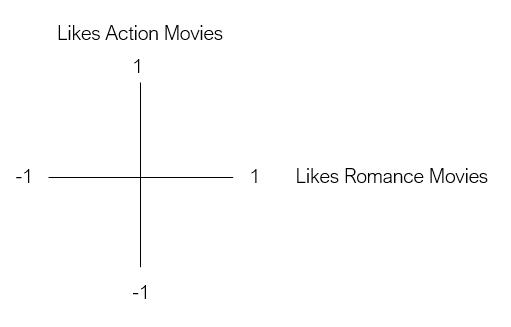 文章插图
文章插图
现在 , 假设Bob是我们的第一个用户 。鲍勃喜欢动作片 , 但不喜欢浪漫片 。为了将Bob表示为二维向量 , 我们根据其偏好将其放置在图形中 。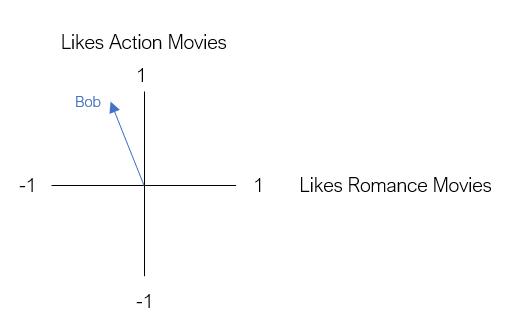 文章插图
文章插图
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 走心|平安夜还在送苹果?太不走心了,教你几招,快来物色一个
- 云图|不会制作词云图?我来教你
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- 如何基于Python实现自动化控制鼠标和键盘操作
- 手机|手机文件夹都是英文,占空间还不敢删除,教你一招省下10G内存
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 蓝鲸专访|水滴CTO邱慧:基于业务场景做技术创新,用户需求可分析并唤醒
- iPhone装了App却在桌面找不到?教你如何解决
- iOS 14小部件如何展示自己心爱的照片?我来教你这个办法