无监督领域自适应的对抗特征增强方法( 二 )
Step 1:训练模型 S , 以生成类似于源数据特征的特征样本 。 利用 CGAN 框架 , 定义极小化极大算法 。 在此步骤和后续步骤中 , 使用最小二乘 GANs , 因为在训练过程中发现 , 最小二乘 GANs 有更好的稳定性 。
【无监督领域自适应的对抗特征增强方法】特征生成:为了生成任意数量的新特征样本 , 这里只需要 S , 它将输出所需类别的特征向量 。
Step 2:在 Step 0 的权重优化进行初始化后 , 通过极小化极大算法 , 训练出具备领域不变性的编码器(达到最佳收敛) 。
实 验:为了评估提出的方法 , 该研究使用了领域自适应研究中经常采用的几种公共源/目标数据集 。
该研究为了评估提出的方法 , 首先证明了模型 S 能够生成以所需类为条件的一致且可区分的特征向量 。 然后 , 研究者进行了控制变量实验 , 以验证每个步骤对实验结果都是正向影响的 。 最后 , 将提出的方法与竞争算法在无监督领域自适应任务上进行比较 。
- 生成特征
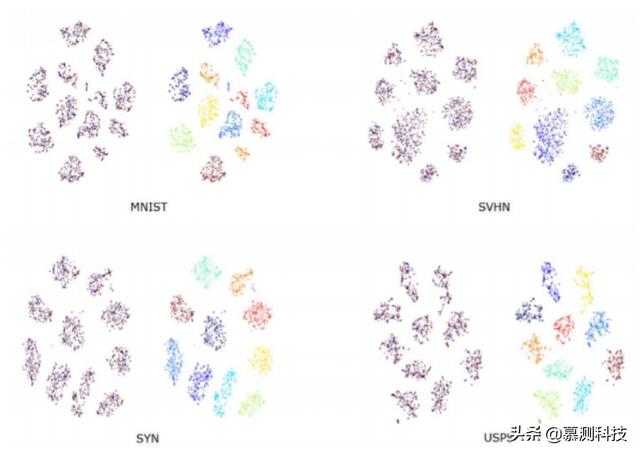 文章插图
文章插图图 2 不同数据集的真实特征和生成特征
表 1 实验结果
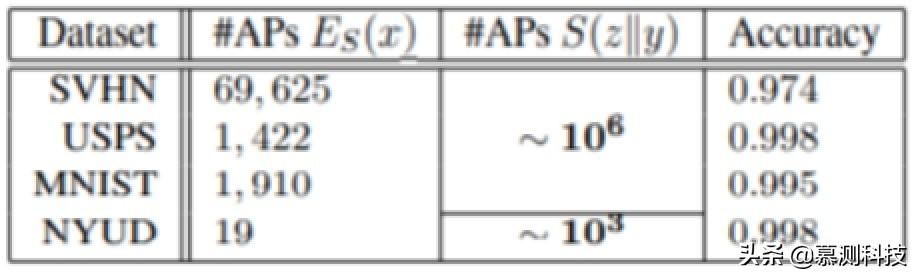 文章插图
文章插图然后 , 该研究评估了通过 S 生成的特征的可变性 , 以确定(i)模型是否存储了训练集中的特征 , 以及(ii)是否可以在特征空间进行数据增强 。 为了验证这两个问题 , 研究者进行了测试实验 , 证明了提出的方法的可靠性 。
- 控制变量研究
- 和其他方法的比较
总 结:在该研究中 , 研究者提出了两种技术来改进无监督领域自适应框架中 GAN 目标的指标表现 。 首先通过直接扩展原始算法来引入领域不变性 。 其次通过对 GANs 的创新应用 , 在特征空间中执行数据增强 。 结果证实这两种方法都可以提高在目标数据集上的准确性 。 在以后的工作中 , 可以考虑在更复杂的无监督领域自适应问题上测试论文提出的方法 , 并研究特征增强是否可以应用于不同的框架 。
本文由南京大学软件学院 2019 级硕士生许子桓翻译转述
- 无国界|嘴上说着支持华为,却为苹果贡献了2000亿!还真是科技无国界啊?
- 小店|抖音小店无货源是什么?与传统模式有什么区别?
- 自动驾驶汽车|海外|自动驾驶无法可依?美国多个团体联合发布自动驾驶立法大纲
- 率先|还在相片美颜?OPPO已进军视频美妆领域,周冬雨或率先体验
- 制药领域|为什么AI制药这么火,为什么是现在?
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 脸上|那个被1亿锦鲤砸中的“信小呆”:失去工作后,脸上已无纯真笑容
- 设置页面|QQ突然更新,加入了一项新功能,可以让你创建一个独一无二的QQID
- 产品|墨案Inkpad X超级阅读器:10英寸大屏,同品类号称无敌
- 部门|日本拟全面替换1000架中企无人机!在担心什么?