python写一个豆瓣短评通用爬虫并可视化分析( 二 )
在具体的实现上 , 我们使用requests发送请求获取结果 , 使用BeautifulSoup去解析html格式文件 。 而我们所需要的数据也很容易分析对应部分 。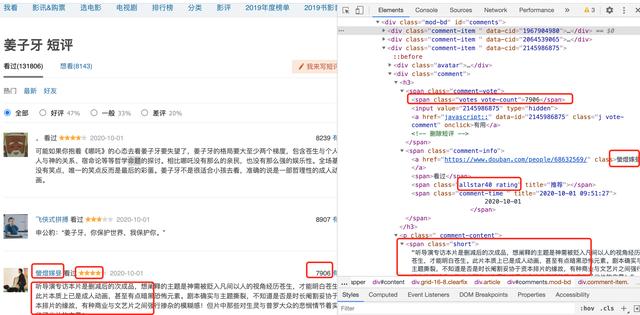 文章插图
文章插图
实现的代码为:
import requestsfrombs4 import BeautifulSoupurl=';start=0 WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',}req = requests.get(url,headers=header,verify=False)res = req.json() # 返回的结果是一个jsonres = res['html']soup = BeautifulSoup(res, 'lxml')node = soup.select('.comment-item')for va in node:name = va.a.get('title')star = va.select_one('.comment-info').select('span')[1].get('class')[0][-2]comment = va.select_one('.short').textvotes=va.select_one('.votes').textprint(name, star,votes, comment)这个测试的执行结果为: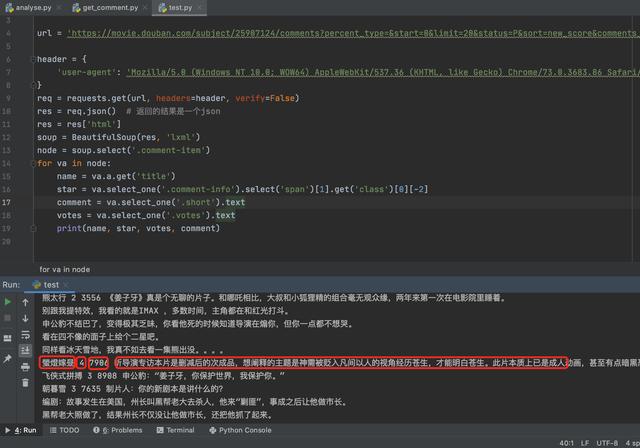 文章插图
文章插图
储存数据爬取完就要考虑存储 , 我们将数据储存到cvs中 。
使用xlwt将数据写入excel文件中 , xlwt基本应用实例:
import xlwt#创建可写的workbook对象workbook = xlwt.Workbook(encoding='utf-8')#创建工作表sheetworksheet = workbook.add_sheet('sheet1')#往表中写内容,第一个参数 行,第二个参数列,第三个参数内容worksheet.write(0, 0, 'bigsai')#保存表为test.xlsxworkbook.save('test.xlsx')使用xlrd读取excel文件中 , 本案例xlrd基本应用实例:
import xlrd#读取名称为test.xls文件workbook = xlrd.open_workbook('test.xls')# 获取第一张表table =workbook.sheets()[0]# 打开第1张表# 每一行是个元组nrows = table.nrowsfor i in range(nrows):print(table.row_values(i))#输出每一行到这里 , 我们对登录模块+爬取模块+存储模块就可把数据存到本地了 , 具体整合的代码为:
import requestsfrom bs4 import BeautifulSoupimport urllib.parseimport xlwtimport xlrd# 账号密码def login(username, password):url = ''header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36','Referer': '','Origin': '','content-Type': 'application/x-www-form-urlencoded','x-requested-with': 'XMLHttpRequest','accept': 'application/json','accept-encoding': 'gzip, deflate, br','accept-language': 'zh-CN,zh;q=0.9','connection': 'keep-alive', 'Host': 'accounts.douban.com'}# 登陆需要携带的参数data = http://kandian.youth.cn/index/{'ck' : '','name': '','password': '','remember': 'false','ticket': ''}data['name'] = usernamedata['password'] = passworddata = http://kandian.youth.cn/index/urllib.parse.urlencode(data)print(data)req = requests.post(url, headers=header, data=data, verify=False)cookies = requests.utils.dict_from_cookiejar(req.cookies)print(cookies)return cookiesdef getcomment(cookies, mvid):# 参数为登录成功的cookies(后台可通过cookies识别用户 , 电影的id)start = 0w = xlwt.Workbook(encoding='ascii')# #创建可写的workbook对象ws = w.add_sheet('sheet1')# 创建工作表sheetindex = 1# 表示行的意思 , 在xls文件中写入对应的行数while True:# 模拟浏览器头发送请求header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',}# try catch 尝试 , 一旦有错误说明执行完成 , 没错误继续进行try:# 拼凑url 每次star加20url = '' + str(mvid) + '/comments?start=' + str(start) + ' --tt-darkmode-color: #A3A3A3;">执行之后成功存储数据: 文章插图
文章插图
可视化分析我们要对评分进行统计、词频统计 。 还有就是生成词云展示 。 而对应的就是matplotlib、WordCloud库 。
实现的逻辑思路:读取xls的文件 , 将评论使用分词处理统计词频 , 统计出现最多的词语制作成直方图和词语 。 将评星数量做成饼图展示一下 , 主要代码均有注释 , 具体的代码为:
其中代码为:
import matplotlib.pyplot as pltimport matplotlibimport jiebaimport jieba.analyseimport xlwtimport xlrdfrom wordcloud import WordCloudimport numpy as npfrom collections import Counter# 设置字体 有的linux字体有问题matplotlib.rcParams['font.sans-serif'] = ['SimHei']matplotlib.rcParams['axes.unicode_minus'] = False# 类似comment 为评论的一些数据 [['1','名称' , 'star星','赞同数','评论内容'],['2','名称' , 'star星','赞同数','评论内容'] ]元组def anylasescore(comment):score = [0, 0, 0, 0, 0, 0]# 分别对应0 1 2 3 4 5分出现的次数count = 0# 评分总次数for va in comment:# 遍历每条评论的数据['1','名称' , 'star星','赞同数','评论内容']try:score[int(va[2])] += 1# 第3列 为star星 要强制转换成int格式count += 1except Exception as e:continueprint(score)label = '1分', '2分', '3分', '4分', '5分'color = 'blue', 'orange', 'yellow', 'green', 'red'# 各类别颜色size = [0, 0, 0, 0, 0]# 一个百分比数字 合起来为100explode = [0, 0, 0, 0, 0]# explode :(每一块)离开中心距离;for i in range(1, 5):# 计算size[i] = score[i] * 100 / countexplode[i] = score[i] / count / 10pie = plt.pie(size, colors=color, explode=explode, labels=label, shadow=True, autopct='%1.1f%%')for font in pie[1]:font.set_size(8)for digit in pie[2]:digit.set_size(8)plt.axis('equal')# 该行代码使饼图长宽相等plt.title(u'各个评分占比', fontsize=12)# 标题plt.legend(loc=0, bbox_to_anchor=(0.82, 1))# 图例# 设置legend的字体大小leg = plt.gca().get_legend()ltext = leg.get_texts()plt.setp(ltext, fontsize=6)plt.savefig("score.png")# 显示图plt.show()def getzhifang(map):# 直方图二维 , 需要x和y两个坐标x = []y = []for k, v in map.most_common(15):# 获取前15个最大数值x.append(k)y.append(v)Xi = np.array(x)# 转成numpy的坐标Yi = np.array(y)width = 0.6plt.rcParams['font.sans-serif'] = ['SimHei']# 用来正常显示中文标签plt.figure(figsize=(8, 6))# 指定图像比例: 8:6plt.bar(Xi, Yi, width, color='blue', label='热门词频统计', alpha=0.8, )plt.xlabel("词频")plt.ylabel("次数")plt.savefig('zhifang.png')plt.show()returndef getciyun_most(map):# 获取词云# 一个存对应中文单词 , 一个存对应次数x = []y = []for k, v in map.most_common(300):# 在前300个常用词语中x.append(k)y.append(v)xi = x[0:150]# 截取前150个xi = ' '.join(xi)# 以空格 ` `将其分割为固定格式(词云需要)print(xi)# backgroud_Image = plt.imread('')# 如果需要个性化词云# 词云大小 , 字体等基本设置wc = WordCloud(background_color="white",width=1500, height=1200,# min_font_size=40,# mask=backgroud_Image,font_path="simhei.ttf",max_font_size=150,# 设置字体最大值random_state=50,# 设置有多少种随机生成状态 , 即有多少种配色方案)# 字体这里有个坑 , 一定要设这个参数 。 否则会显示一堆小方框wc.font_path="simhei.ttf"# 黑体# wc.font_path="simhei.ttf"my_wordcloud = wc.generate(xi)#需要放入词云的单词, 这里前150个单词plt.imshow(my_wordcloud)# 展示my_wordcloud.to_file("img.jpg")# 保存xi = ' '.join(x[150:300])# 再次获取后150个单词再保存一张词云my_wordcloud = wc.generate(xi)my_wordcloud.to_file("img2.jpg")plt.axis("off")def anylaseword(comment):# 这个过滤词 , 有些词语没意义需要过滤掉list = ['这个', '一个', '不少', '起来', '没有', '就是', '不是', '那个', '还是', '剧情', '这样', '那样', '这种', '那种', '故事', '人物', '什么']print(list)commnetstr = ''# 评论的字符串c = Counter()# python一种数据集合 , 用来存储字典index = 0for va in comment:seg_list = jieba.cut(va[4], cut_all=False)## jieba分词index += 1for x in seg_list:if len(x) > 1 and x != '\r\n':# 不是单个字 并且不是特殊符号try:c[x] += 1# 这个单词的次数加一except:continuecommnetstr += va[4]for (k, v) in c.most_common():# 过滤掉次数小于5的单词if v
- 车企|华为不造车!但任正非加了一个有效期,3年
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 发展|新基建发展迅猛,必然会是一个巨大的市场机遇
- 易来|RA95显色只是起步,2020双12选灯必逛好店!
- 缺点|骁龙865+12GB已降至2399,X轴马达+55W快充,缺点只有一个
- 空间|垃圾文件正在吞噬你的C盘空间用这四种方法,还你一个干净的C盘
- 商业|AC有望建立一个商业帝国吗?
- 中国汽车|2020年,我们攒了一个局,串了一条链,下了一盘棋