大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率( 二 )
高通量输入流程为了解决数据输入的性能瓶颈 , 研究人员使用了机器学习任务专用的数据存储系统Reverb 。 但仅仅使用单个Reverb回放缓存服务是不足以支撑大规模分布式强化学习系统的性能要求的 , 来自数千个行为器的数据写入效率会被大大拉低 。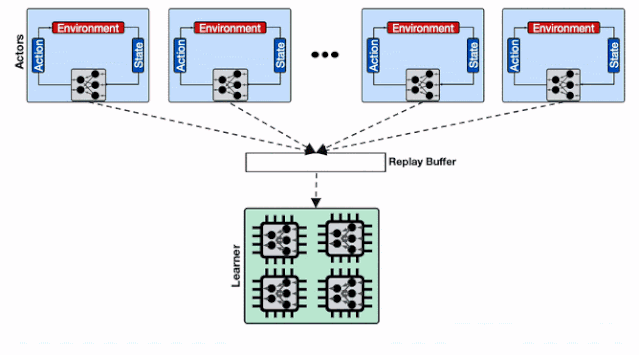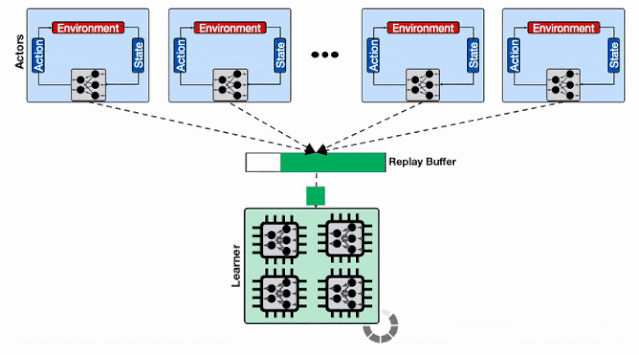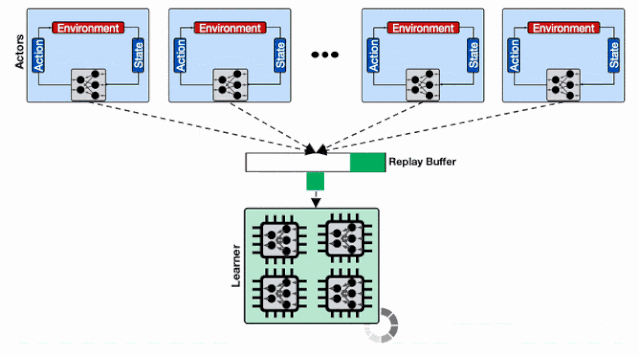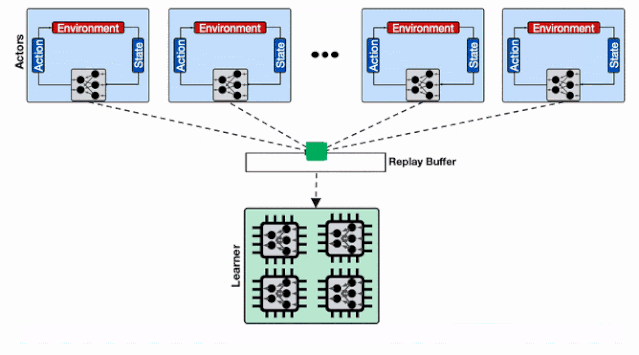 文章插图
文章插图
仅仅存在单个回放缓存时 , 数千个行为器的数据被拖慢 。 训练系统使用了多个计算核 , 那么仅仅使用一个数据回放缓存是不足以支撑高性能计算的 。
为了更好地理解分布式系统中回放缓存 (replay buffer) 的性能 , 研究人员利用不同的模型大小和行为器数量在相同的设备上进行了比较试验 。
实验表明 , 随着行为器数量从16增长到2048 , 模型大小从16M增加到512M的过程中 , 平均延时增加了6.2倍和18.9倍 , 这种写入数据的延迟大幅度降低了行为器从环境中收集数据的效率 , 并造成了整体训练过程的低效 。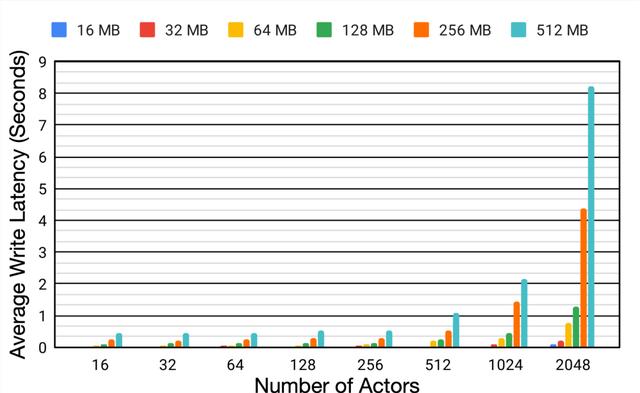 文章插图
文章插图
单个Reverb缓冲器的性能变化
为了解决这一问题 , 研究人员利用了Reverb的分片能力来增加行为器和学习器以及回放缓存服务间的数据通量 。 分片功能平衡了数量巨大的行为器与多个缓存器间的负载 , 避免了单个缓存器造成的瓶颈 , 最小化了写延时 。 这种方式使得Menger可以在不同Borg计算单元上大规模地进行拓展 。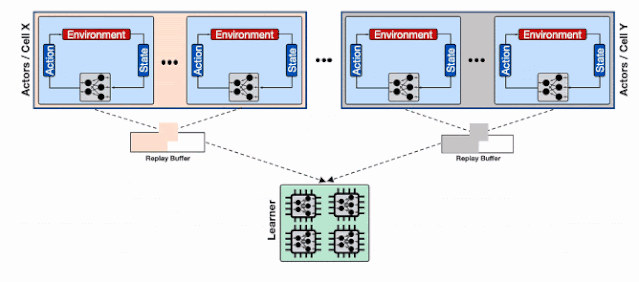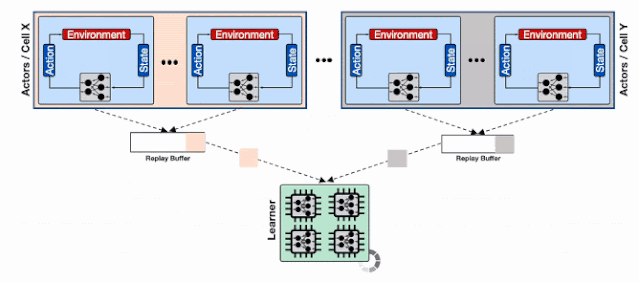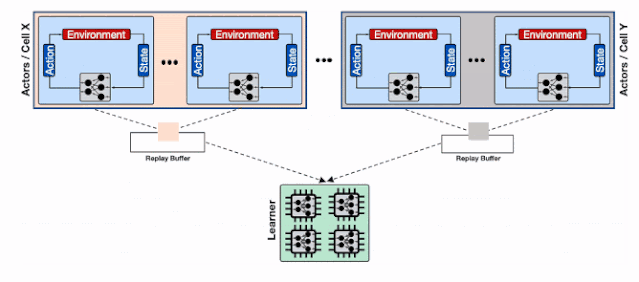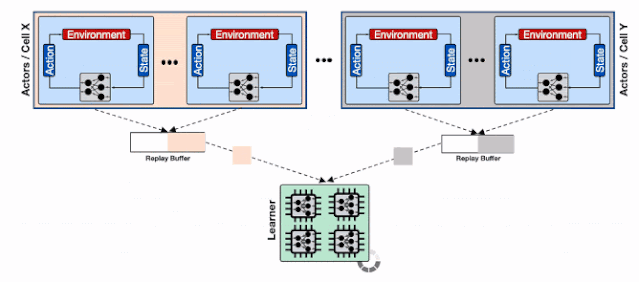 文章插图
文章插图
基于分片重放缓存的分布式强化学习系统 , 每个缓存收集来自多个学习器的数据 , 为输入学习器的加速硬件提供了更高的数据通量 。
案例分析:芯片布局任务研究人员将这套算法应用于芯片设计中布局任务的优化中 , 实验表明针对实际任务这种方法将训练时间从8.6小时减低为一个小时 。 虽然Menger在TPU上进行了优化 , 但同时作者认为在GPUs上也会有相似地性能提升 。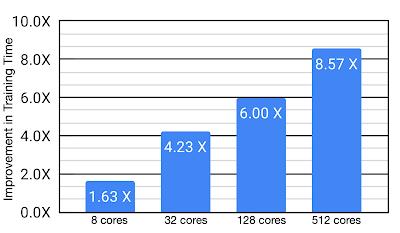 文章插图
文章插图
这种框架为大规模强化学习提供了有益的方向 , 虽然仅仅在芯片设计的位置布局上成功应用 , 但这也从一个侧面反映出强化学习与这套系统在各个领域较好的应用前景 。 未来如果想利用成百上千个智能体进行任务训练提升训练性能 , 这套分布式高速训练系统是不错的选择 。
ref:
ChipPlace:
Borg:
Reverb: 文章插图
文章插图 文章插图
文章插图
扫码观看!
本周上新! 文章插图
文章插图
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构 , 旗下涵盖将门创新服务、将门技术社群以及将门创投基金 。 将门成立于2015年底 , 创始团队由微软创投在中国的创始团队原班人马构建而成 , 曾为微软优选和深度孵化了126家创新的技术型创业公司 。
将门创新服务专注于使创新的技术落地于真正的应用场景 , 激活和实现全新的商业价值 , 服务于行业领先企业和技术创新型创业公司 。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容 , 使创新成为持续的核心竞争力 。
将门创投基金专注于投资通过技术创新激活商业场景 , 实现商业价值的初创企业 , 关注技术领域包括机器智能、物联网、自然人机交互、企业计算 。 在近四年的时间里 , 将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司 。
【大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率】如果您是技术领域的初创企业 , 不仅想获得投资 , 还希望获得一系列持续性、有价值的投后服务 , 欢迎发送或者推荐项目给“门”: 文章插图
文章插图
- 全自动|马斯克:特斯拉两周内大规模推送全自动驾驶(FSD)测试版
- 蔚来和小鹏|小鹏蔚来大规模断网,最后背锅的竟是中国移动
- 分布式锁的这三种实现90%的人都不知道
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 小基站带来新机遇!明年5G大规模室内建设将开始
- 为什么分布式应用程序需要依赖管理?
- 腾讯云造了一个“智慧胶囊”,打开了5G大规模应用的大门
- 分布式云对智能化战争有何影响
- 四核强性能,华硕XD4灵耀AX魔方分布式路由评测