史上最全Python反爬虫方案汇总( 三 )
 文章插图
文章插图
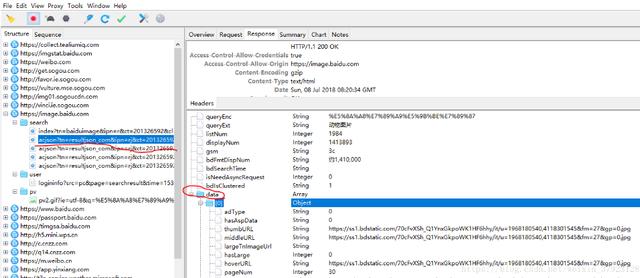
3. 打开一个浏览器页面 , 访问thumbURL=",4118301545&fm=27&gp=0.jpg" 发现搜索结果里的图片 。
4. 根据前面的分析 , 就可以知道 , 请求
URL="/search/acjsontn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf8&oe=utf8&adpicid=&st=-1&z=&ic=0&word=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1531038037275=" , 用浏览器访问这个链接确定他是公开的 。
5. 最后就可以寻找URL的规律 , 对URL进行构造便可获取所有照片 。
- 使用selenium
缺点:如果数据API没做加密处理 , 容易曝光接口 , 让爬虫用户更容易获取数据 。
实现难度:★数据加密-使用加密算法
- 前端加密
- 服务器端加密
爬虫方法:JS加密破解方式 , 就是要找到JS的加密代码 , 然后使用第三方库js2py在Python中运行JS代码 , 从而得到相应的编码 。
缺点:加密算法明文写在JS里 , 爬虫用户还是可以分析出来 。
实现难度:★★★数据加密-使用字体文件映射服务器端根据字体映射文件先将客户端查询的数据进行变换再传回前端 , 前端根据字体文件进行逆向解密 。
映射方式可以是数字乱序显示 , 这样爬虫可以爬取数据 , 但是数据是错误的 。
破解方式:
其实 , 如果能看懂JS代码 , 这样的方式还是很容易破解的 , 所以需要做以下几个操作来加大破解难度 。
- 对JS加密
- 使用多个不同的字体文件 , 然后约定使用指定字体文件方式 , 比如时间戳取模 , 这样每次爬取到的数据映射方式都不一样 , 映射结果就不一样 , 极大提高了破解的难度 。
缺点:需要生成字体文件 , 增加网站加载资源的体量 。
实现难度:★★★★非可视区域遮挡此方式主要针对使用senlium进行的爬虫 , 如果模拟界面未进入可视区域 , 则对未见数据进行遮挡 , 防止senlium的click()操作 。 这种方式只能稍稍降低爬虫的爬取速度 , 并不能阻止继续进行数据爬取 。
实现难度:★最后 , 小编想说:我是一名python开发工程师 , 整理了一套最新的python系统学习教程 ,
想要这些资料的可以关注私信小编“01”即可 , 希望能对你有所帮助 。
- 广告点击|广告效果评估:30天的广告时间评估最全面
- 主题|GNN、RL崛起,CNN初现疲态?ICLR 2021最全论文主题分析
- 史上最短命旗舰!为了华为P50:Mate40部分机型疑似停产
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础