并发容器ConcurrentHashMap( 二 )
JDK 1.8 结构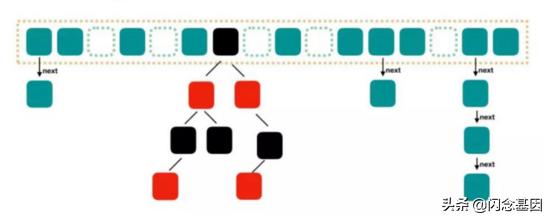 文章插图
文章插图
图中的节点有三种类型:
HashMapConcurrentHashMap链表长度大于某一个阈值(默认为 8) , 满足容量从链表的形式转化为红黑树的形式 。
红黑树是每个节点都带有颜色属性的二叉查找树 , 颜色为红色或黑色 , 红黑树的本质是对二叉查找树 BST 的一种平衡策略 , 我们可以理解为是一种平衡二叉查找树 , 查找效率高 , 会自动平衡 , 防止极端不平衡从而影响查找效率的情况发生 , 红黑树每个节点要么是红色 , 要么是黑色 , 但根节点永远是黑色的 。
ConcurrentHashMap 源码常量说明/*** table 桶数最大值 , 且前两位用作控制标志*/private static final int MAXIMUM_CAPACITY = 1 << 30;/*** table 桶数初始化默认值 , 需为2的幂次方*/private static final int DEFAULT_CAPACITY = 16;/*** 数组可能最大值 , 需要与toArray()相关方法关联*/static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;/***并发级别 , 遗留下来的 , 为兼容以前的版本*/private static final int DEFAULT_CONCURRENCY_LEVEL = 16;/*** 加载因子 , 扩容的阀值 , 可在构造方法定义*/private static final float LOAD_FACTOR = 0.75f;/*** 链表转红黑树阀值, 超过 8 链表转换为红黑树*/static final int TREEIFY_THRESHOLD = 8;/*** 树转链表阀值 , 小于等于6(tranfer时 , lc、hc=0两个计数器分别++记录原bin、新binTreeNode数量 , <=UNTREEIFY_THRESHOLD 则untreeify(lo))*/static final int UNTREEIFY_THRESHOLD = 6;/*** 树化阀值2 , 当数组桶树达到64以上才允许链表树化*/static final int MIN_TREEIFY_CAPACITY = 64;初始化 tableprivate final Nodeget 方法public V get(Object key) {Node总结一下 get 的过程:
- 计算 Hash 值 , 并由此值找到对应的槽点;
- 如果数组是空的或者该位置为 null , 那么直接返回 null 就可以了;
- 如果该位置处的节点刚好就是我们需要的 , 直接返回该节点的值;
- 如果该位置节点是红黑树或者正在扩容 , 就用 find 方法继续查找;
- 否则那就是链表 , 就进行遍历链表查找
public V put(K key, V value) {return putVal(key, value, false);}final V putVal(K key, V value, boolean onlyIfAbsent) {// 计算 key 的 hashCodeint hash = spread(key.hashCode());int binCount = 0;// 循环直到插入成功 ,for (Node[] tab = table;;) {Node f; int n, i, fh;if (tab == null || (n = tab.length) == 0)// 初始化 tabletab = initTable();// tabAt 调用 getObjectVolatile// 当前位置为空可以直接插入的情况else if ((f = tabAt(tab, i = (n - 1)}// 下面是位置已经有值的情况// MOVED 表示当前 Map 正在进行扩容else if ((fh = f.hash) == MOVED)// 帮助进行扩容 , 然后进入下一次循环尝试插入tab = helpTransfer(tab, f);// 未在扩容的情况else {V oldVal = null;// 对f加锁 , f 是存储在当前位置的 Node 的头节点synchronized (f) {// 双重检查 , 保证 Node 头节点没有改变if (tabAt(tab, i) == f) {if (fh >= 0) {// 对链表进行操作binCount = 1;for (Node e = f;; ++binCount) {// 更新值(判断 onlyIfAbsent)或插入链表尾部 ...break;}}else if (f instanceof TreeBin) {// 对树进行操作 ...}}}// 判断是否需要 treeifyif (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;} 总结一下 put 的过程:- 判断Node[] 数组是否初始化 , 没有则进行初始化操作
- 通过 hash 定位数组的索引坐标 , 是否有 Node 节点 , 如果没有则使用 CAS 进行添加(链表的头节点) , 添加失败则进入下次循环 。
- 检查到内部正在扩容 , 就帮助它一块扩容 。
- 如果 f != null, 则使用 synchronized 锁住 f 元素(链表/红黑二叉树的头元素)如果是 Node (链表结构)则执行链表的添加操作如果是 TreeNode (树形结构)则执行树添加操作 。
- Store|苹果将在韩国开设第二家Apple Store直营店 并发布纪念壁
- Linux(服务器编程):百万并发服务器系统参数调优
- 3D打印高性能可拉伸微型超级电容器
- 为什么 Redis 单线程能支撑高并发?
- IT工程师都需要掌握的容器技术之Docker容器管理
- 除非有理由使用其他容器,优先使用STL vector
- 分布式锁结合SpringCache
- 苹果将在韩国开设第二家Apple Store直营店 并发布纪念壁纸
- Redis集群做法的难点,百万并发客户端「实战」
- 高并发的可见性搞不明白,就不用再研发了