快速概览 + 详细了解N:N聚类算法是如何应用的( 二 )
简单介绍一下聚类分析:聚类分析是根据在数据中发现的描述对象及其关系的信息 , 将数据对象分组 。
目的是——组内的对象相互之间是相似的(相关的) , 而不同组中的对象是不同的(不相关的);组内相似性越大 , 组间差距越大 , 说明聚类效果越好 。
聚类效果的好坏依赖于两个因素:
- 衡量距离的方法(distance measurement) ;
- 聚类算法(algorithm) 。
其基本思想是从每个语片段中提取特征参数 , 例如梅尔倒谱参数 , 计算每两个语音段之间特征参数的相似度 , 并利用BIC判断相似度最高的两个语音段是否合并为同一类 。
对任意两段语音都进行上述判决 , 直到所有的语音段不再合并 。
——摘自“说话人聚类的初始类生成方法”
聚类&声纹识别的主要场景:在跨渠道、跨场景收集语音同时建立声纹库的时候;由于各场景应用的客户账号或许不同 , 说话人在不同场景中分别注册过声纹 , 难以筛除重复注册语音 , 建立统一声纹库 。
我们如何快速的去筛除属于某一个人在不同情况下录制的多条录音文件?也就是如何保证最终留下的录音文件(声纹库)是唯一的?
每一个人只对应一条音频 , 这就要用到聚类的算法;利用声纹识别N:N说话人聚类 , 对所有收集到的语音进行语音相似度检测 , 将同一说话人在不同场景中的多次录制的语音筛选出来;并只保留其中一条 , 从而保证了声纹库的独特性 , 节省了大量的人力成本、资源成本 。
对于目前的场景 , 我们选择凝聚层次聚类算法 , 在这种场景下 , 我们是要筛除重复人说话;那么我们可以将每一个录音文件都当作一个独立的数据点 , 看最后有凝聚出多少个独立的数据簇 , 此时可以理解为类内都是同一个人在说话 。
1)我们首先将每个数据点(每一条录音文件)视为一个单一的类 , 即如果我们的数据集中有 X 个数据点 , 那么我们就有 X 个类;然后 , 我们选择一个测量两个类之间距离的距离度量标准;作为例子 , 我们将用 average linkage , 它将两个类之间的距离定义为第一个类中的数据点与第二个类中的数据点之间的平均距离(这个距离度量标准可以选择其他的) 。
2)在每次迭代中 , 我们将两个类合并成一个;这两个要合并的类应具有最小的 average linkage , 即根据我们选择的距离度量标准 , 这两个类之间的距离最小;因此是最相似的 , 应该合并在一起 。
3)重复步骤 2 直到我们到达树根 , 即我们只有一个包含所有数据点的类 。 这样我们只需要选择何时停止合并类 , 即何时停止构建树 , 来选择最终需要多少个类(摘自知乎) 。
按照实际的场景 , 如果我们最终要得到1000个不重复的录音文件 , 为了防止过度合并 , 定义的退出条件是最后想要得到的录音文件数目 。
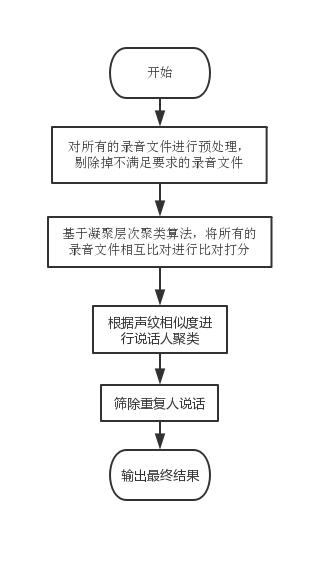 文章插图
文章插图处理的流程图
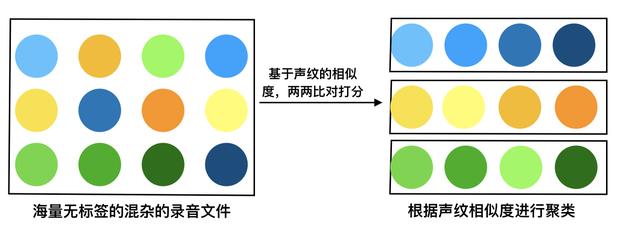 文章插图
文章插图聚类模拟图
五、声纹识别的几类攻击及其策略1. 录音重放攻击攻击者录制目标说话人的语音进行播放 , 以目标人身份试图通过声纹识别系统的认证 。
策略:基于随机内容声纹的检测技术 , 利用随机数字的不确定性 , 用户在规定的时间内(5-10S)需要念出指定的随机内容 , 如果超时 , 则随机内容更新;因为对于录音重放的内容是固定的 , 很不灵活 , 所以比较容易做限制 。
2. 波形拼接攻击攻击者将目标说话人的语音录制下来 , 通过波形编辑工具 , 拼接出指定内容的语音数据 , 以放音的方式假冒目标说话人 , 试图以目标人身份通过声纹识别系统的认证 。
策略:同录音重放 。
3. 语音合成攻击攻击者用语音合成技术生成目标说话人的语音 , 以放音的方式假冒目标说话人 , 试图以目标人的身份通过声纹识别系统的认证 。
策略:同录音重放;利用活体检测技术 , 加强算法的识别度 。
以上 , 是关于声纹识别的一些分享 , 希望大家可以多多交流 , 一同进步 。
本文由@寒白 原创发布于人人都是产品经理 。 未经许可 , 禁止转载
题图来自Unsplash , 基于CC0协议
- GB|备货充足要多少有多少,5000mAh+128GB,红米新机首销快速现货
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- DDR5内存曝光:16GB 4800MHz快速更省电
- 喵喵机错题打印机P1:随时打印,随时学习,快速整理错题
- 软件定义存储之ScaleIO,VMWare环境详细部署和使用
- 快速安装一个OpenShift 4 准生产集群
- Java模块系统新特性快速上手指南
- Corona6.1超详细安装步骤,全汉化最新CR版本