几乎所有的强化学习论文都只考虑了很小动作集的情况 , 例如最常用的环境雅达利只有十几个动作 。 有部分论文考虑了较大动作集的环境 , 但一般也只有几百个 。 斗地主却有上万个可能的动作 , 并且不同状态有不同的合法动作子集 , 这无疑给设计强化学习算法带来了很大挑战 。 之前的研究表明 , 常用的强化学习算法 , 如 DQN 和 A3C , 在斗地主上仅仅略微好于随机策略[2][3] 。
「斗零」是怎么斗地主的?
比较有趣的是 , 斗零的核心算法极其简单 。 斗零的设计受启发于蒙特卡罗方法(Monte-Carlo Methods)[4] 。 具体来说 , 算法的目标是学习一个价值网路 。 网络的输入是当前状态和一个动作 , 输出是在当前状态做这个动作的期望收益(比如胜率) 。 简单来说 , 价值网络在每一步计算出哪种牌型赢的概率最大 , 然后选择最有可能赢的牌型 。 蒙特卡罗方法不断重复以下步骤来优化价值网络:
- 用价值网络生成一场对局
- 记录下该对局中所有的状态、动作和最后的收益(胜率)
- 将每一对状态和动作作为网络输入 , 收益作为网络输出 , 用梯度下降对价值网络进行一次更新
然而 , 作者却惊讶地发现蒙特卡罗方法非常适合斗地主 。 首先 , 斗地主可以很容易产生完整的对局 , 所以不存在不完整的状态序列 。 其次 , 作者发现蒙特卡罗方法的效率其实并没有很低 。 因为蒙特卡罗方法实现起来极其简单 , 我们可以很容易通过并行化来采集大量的样本以降低方差 。 与之相反 , 很多最先进的强化学习算法虽然有更好的采样效率 , 但是算法本身就很复杂 , 因此需要很多计算资源 。 综合来看 , 蒙特卡罗方法在斗地主上运行时间(wall-clock time)并不一定弱于最先进的方法 。 除此之外 , 作者认为蒙特卡罗方法还有以下优点:
- 很容易对动作进行编码 。 斗地主的动作与动作之前是有内在联系的 。 以三带一为例:如果智能体打出 KKK 带 3 , 并因为带牌带得好得到了奖励 , 那么其他的牌型的价值 , 例如 JJJ 带 3 , 也能得到一定的提高 。 这是由于神经网络对相似的输入会预测出相似的输出 。 动作编码对处理斗地主庞大而复杂的动作空间非常有帮助 。 智能体即使没有见过某个动作 , 也能通过其他动作对价值作出估计 。
- 不受过度估计(over-estimation)的影响 。 最常用的基于价值的强化学习方法是 DQN 。 但众所周知 , DQN 会受过度估计的影响 , 即 DQN 会倾向于将价值估计得偏高 , 并且这个问题在动作空间很大时会尤为明显 。 不同于 DQN , 蒙特卡罗方法直接估计价值 , 因此不受过度估计影响 。 这一点在斗地主庞大的动作空间中非常适用 。
- 蒙特卡罗方法在稀疏奖励的情况下可能具备一定优势 。 在斗地主中 , 奖励是稀疏的 , 玩家需要打完整场游戏才能知道输赢 。 DQN 的方法通过下一个状态的价值估计当前状态的价值 。 这意味着奖励需要一点一点地从最后一个状态向前传播 , 这可能导致 DQN 更慢收敛 。 与之相反 , 蒙特卡罗方法直接预测最后一个状态的奖励 , 不受稀疏奖励的影响 。
斗零系统的实现也并不复杂 , 主要包含三个部分:动作 / 状态编码、神经网络和并行训练 。
动作 / 状态编码
【GitHub|快手开源斗地主AI,入选ICML,能否干得过「冠军」柯洁?】如下图所示 , 斗零将所有的牌型编码成 15x4 的由 0/1 组成的矩阵 。 其中每一列代表一种牌 , 每一行代表对应牌的数量 。 例如 , 对于 4 个 10 , 第 8 列每一行都是 1;而对于一个 4 , 第一行只有最后一行是 1 。 这种编码方式可适用于斗地主中所有的牌型 。
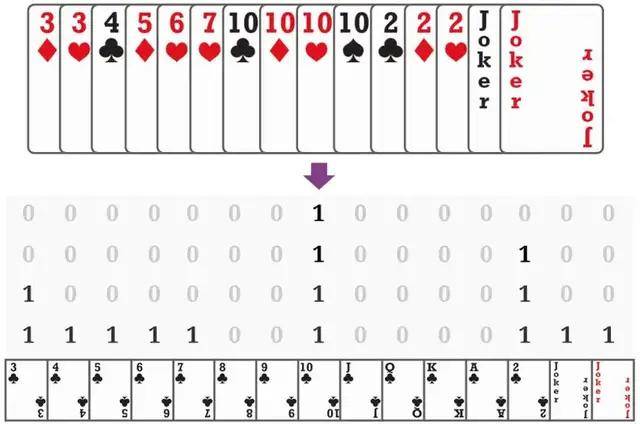
文章图片
斗零提取了多个这样的矩阵来表示状态 , 包括当前手牌 , 其他玩家手牌之和等等 。 同时 , 斗零提取了一些其他 0/1 向量来编码其他玩家手牌的数量、以及当前打出的炸弹数量 。 动作可以用同样的方式进行编码 。
- 电竞|因和平精英赛事,快手再获电竞大奖,年底还要搞大动作?
- 平台|快手游戏荣获2021年度电竞赛事合作平台奖,深耕国际赛事共建电竞生态
- 玩法|快手官宣春节活动瓜分 22 亿红包,19 日晚 8 点上线
- 运送员|科学精准防疫微镜头丨样本运送员邵元亮——“残缺”快手的120次“摆渡”
- 经营|快手游戏业务寻突破,海外FPS能否助其打开局面
- 投资|魂世界获快手投资,曾研发流水数亿的模拟经营游戏
- 王姐|甲状腺癌,我需要尽快手术
- 焯水|冬季,宁可不吃肉也要吃这菜,鲜美营养又快手,应季而食,身体棒
- 广君|这款红了13年的游戏,让我看到快手上更多元的游戏文化
- 快手极速版邀请一个新人能赚多少钱?