文本秒生成图像,震惊业界!详解OpenAI两大AI模型( 三 )
 文章插图
文章插图
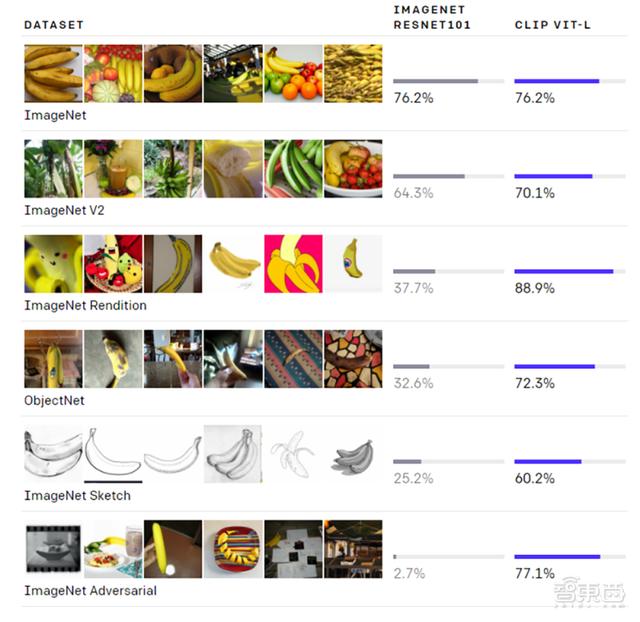
在众多数据集上 , CLIP都有着可以与ResNet50升级版ResNet101媲美的精度 , 其中ObjectNet数据集代表模型识别物体不同形态和背景的能力 , ImageNet Rendition和ImageNet Sketch代表模型识别抽象物体的能力 。
虽然二者在ImageNet测试集上的表现相差无几 , 但非ImageNet设置更能代表CLIP优秀的泛化能力 。
为了识别出未曾见过的类别(图像或文本) , Zero-shot这一概念可以追溯到十年前 , 而目前计算机视觉领域应用的重点是 , 利用自然语言作为灵活的预测空间 , 实现泛化和迁移 。
在2013年 , 斯坦福大学的Richer Socher教授就曾在训练CIFAR-10的模型时 , 在词向量嵌入空间中进行预测 , 并发现该模型可以预测两个“未见过”的类别 。
刚刚登上历史舞台、用自然语言学习视觉概念的CLIP则带上了更多现代的架构 , 如用注意力机制理解文本的Transformer、探索自回归语言建模的Virtex、研究掩蔽语言建模的ICMLM等 。
四、详细解析 , CLIP的“足”与“不足”在对CLIP有一个基本的认识后 , 我们将从四个方面详细剖析CLIP 。
1、从CLIP流程 , 看三大问题如何解决
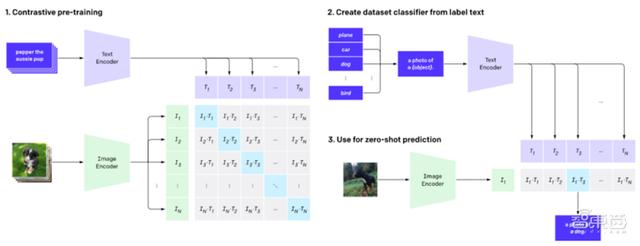
简单来说 , CLIP的任务就是识别一张图像所出现的各种视觉概念 , 并且学会它的名称 。 比如当任务是对猫和狗的图片进行分类 , CLIP模型就需要判断 , 目前处理的这张图片的文字描述是更偏向于“一张猫的照片” , 还是一张狗的照片 。
在具体实现上 , 有如下流程:预训练图像编码器和文本编码器 , 得到相互匹配的图像和文本 , 基于此 , CLIP将转换为zero-shot分类器 。 此外 , 数据集的所有类会被转换为诸如“一只狗的照片”之类的标签 , 以此标签找到能够最佳配对的图像 。
 文章插图
文章插图
在这个过程中 , CLIP也能解决之前提到的三大问题 。
1、昂贵的数据集:25000人参与了ImageNet中1400万张图片的标注 。 与此相比 , CLIP使用的是互联网上公开的文本-图像对 , 在标注方面 , 也利用自监督学习、对比方法、自训练方法以及生成建模等方法减少对人工标注的依赖 。
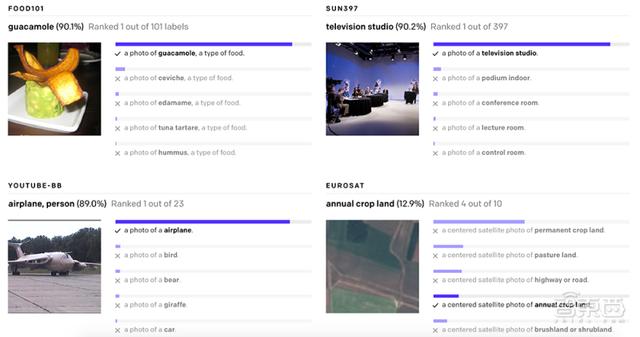
2、只适用于单一任务:由于已经学会图片中的各种视觉概念 , 所以CLIP可以执行各种视觉任务 , 而不需要额外的训练和调整 。 如下也展示了CLIP模型识别各类型图像中视觉概念,无论是食物、场景还是地图 , 都是有不错的表现 。
 文章插图
文章插图
3、实际应用性能不佳:基准测试中表现好的模型在实际应用中很可能并没有这么好的水平 。 就像学生为了准备考试 , 只重复复习之前考过的题型一样 , 模型往往也仅针对基准测试中的性能进行优化 。 但CLIP模型可以直接在基准上进行评估 , 而不必在数据上进行训练 。
2、CLIP的“足”:高效且灵活通用 。
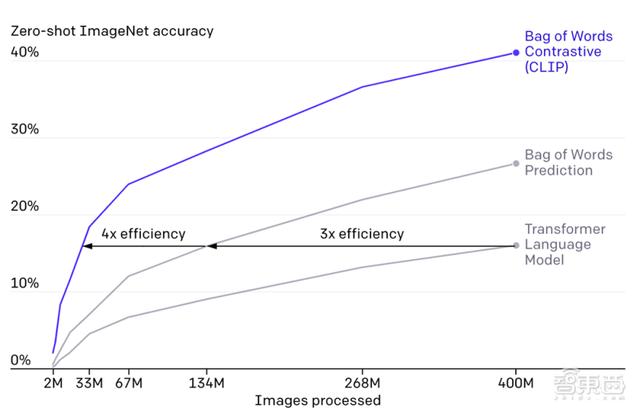
CLIP需要从未经标注、变化多端的数据中进行预训练 , 且要在“zero-shot” , 即零样本的情况下使用 。 GPT-2/3模型已经验证了该思路的可行性 , 但这类模型需要大量的模型计算 , 为了减少计算量 , OpenAI的研究人员采用了两种算法:对比目标(contrastive objective)和Vision Transformer 。 前者是为了将文本和图像连接起来 , 后者使计算效率比标准分类模型提高了三倍 。
 文章插图
文章插图
CLIP模型在准确率和处理图像大小上都优于其他两种算法 。
由于CLIP模型可以直接从自然语言中学习许多视觉概念 , 因此它们比现有的ImageNet模型更加灵活与通用 。 OpenAI的研究人员在30多个数据集上评估了CLIP的“zero-shot”性能 , 包括细粒度物体分类 , 地理定位 , 视频中的动作识别和OCR(光学字符识别)等 。
- 中低端手机的500万和800万像素的CIS严重短缺!报告称三星CMOS图像传感器已涨价40%
- 开会无需纸和笔!华为手机打开这个功能,会议纪要一键生成
- 开会再也不用手写,微信打开这个设置,会议纪要一键生成
- OpenAI推DALL-E模型:能根据文字描述生成图片
- 苹果地图车正在以色列、新西兰和新加坡售价Look Around图像
- 微软测试Outlook智能文本预测功能 帮助用户更快地撰写电子邮件
- Caviar恳请撤回Galaxy S21 Ultra限量版图像 外媒对此感到不解
- 喜马拉雅年终特别策划上线:你的2020年度收听报告已经生成
- “像”由“芯”生:中国打造自主高端图像传感器芯片
- Firefox 火狐浏览器将默认支持 AVIF 图像格式,教你在 84.0 版本开启