文本秒生成图像,震惊业界!详解OpenAI两大AI模型( 四 )
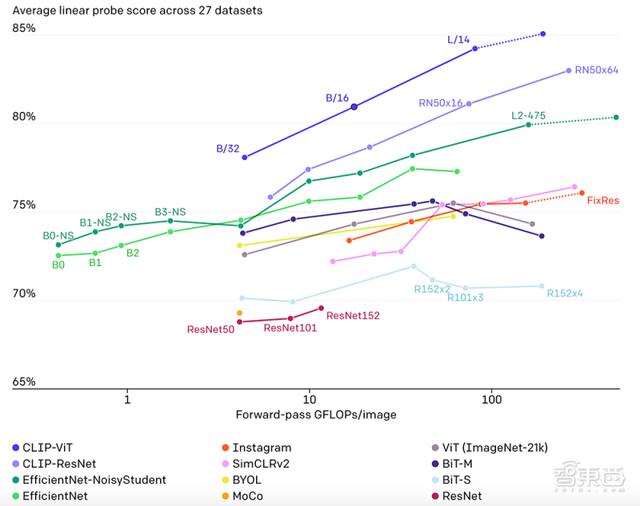
下图也展示了12种模型在27种数据集准确率和处理图像大小的比较 。 CLIP-ViT和CLIP-ResNet两类CLIP方法都遥遥领先 。
 文章插图
文章插图
3、CLIP的“不足”:复杂任务仍有差距
尽管CLIP在识别常见物体上表现良好 , 但在如计算图像中物品数量、预测图片中物品的位置距离等更抽象、复杂的任务上 , “zero-shot”CLIP表现仅略胜于随机分类 , 而在区分汽车模型、飞机型号或者花卉种类时 , CLIP也不好 。
且对于预训练阶段没有出现过的图像 , CLIP泛化能力也很差 。 例如 , 尽管CLIP学习了OCR , 但评估MNIST数据集的手写数字上 , “zero-shot”CLIP准确率只达到了88% , 远低于人类在数据集中的99.75%精确度 。 最后 , 研究人员发现 , CLIP的“zero-shot”分类器对单词构造或短语构造比较敏感 , 但有时还是需要试验和错误“提示引擎”的辅助 , 才能表现良好 。
4、CLIP未来:算法公正仍需努力
研究人员也在博客中提到 , CLIP更大的潜力是允许人们设计自己的分类 , 无需使用特定任务的训练数据 。 因为分类的定义方法会影响模型的性能和偏差 。
如果CLIP中添加的标签包括Fairface种族标签(FairFace是一个涵盖不同人种、性别的面部图像数据集)和少数负面名词 , 例如“犯罪” , “动物”等 , 那么很可能大约32.3%年龄为0至20岁的人像会被划分到负面类别中 , 但在添加“儿童”这一标签后 , 负面类别的比例大约下降到8.7% 。
此外 , 由于CLIP不需要针对特定任务训练数据 , 所以能够更轻松地完成一些任务 。 但这些任务会不会涉及到特定的隐私和监视风险 , 需要进一步的研究 。
结语:模型很厉害 , 监管需谨慎无论是DALL·E还是CLIP , 都采用不同的方法在多模态学习领域跨出了令人惊喜的一步 。
但OpenAI的研究人员也反复强调 , 越强大的模型一旦失控 , 后果也越加可怕 , 所以两个模型后续的关于“公平性”、“隐私性”等问题研究也会继续进行 。
今后 , 文本和图像的界限是否会进一步被打破 , 我们能否能顺畅地用文字“控制”图像的分类和生成 , 在现实生活中将会带来怎样的改变 , 都值得我们期待 。
来源:OpenAI
 文章插图
文章插图
- 中低端手机的500万和800万像素的CIS严重短缺!报告称三星CMOS图像传感器已涨价40%
- 开会无需纸和笔!华为手机打开这个功能,会议纪要一键生成
- 开会再也不用手写,微信打开这个设置,会议纪要一键生成
- OpenAI推DALL-E模型:能根据文字描述生成图片
- 苹果地图车正在以色列、新西兰和新加坡售价Look Around图像
- 微软测试Outlook智能文本预测功能 帮助用户更快地撰写电子邮件
- Caviar恳请撤回Galaxy S21 Ultra限量版图像 外媒对此感到不解
- 喜马拉雅年终特别策划上线:你的2020年度收听报告已经生成
- “像”由“芯”生:中国打造自主高端图像传感器芯片
- Firefox 火狐浏览器将默认支持 AVIF 图像格式,教你在 84.0 版本开启