通过视频着色进行自监督跟踪( 二 )
 文章插图
文章插图
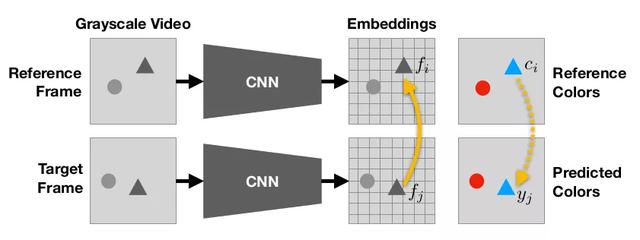
模型接收一个彩色帧和一个灰度视频作为输入 , 并预测下一帧的颜色 。 模型学会从参考系复制颜色 , 这使得跟踪机制可以在没有人类监督的情况下学习 。 [来源:]
我们不复制网络中的颜色 , 而是训练我们的CNN网络学习目标帧的像素和参考帧的像素之间的相似度(相似度是灰度像素之间) , 然后线性组合时使用此相似度矩阵参考帧中的真实颜色会给出预测的颜色 。 从数学上讲 , 设C?为参考帧中每个像素i的真实颜色 , C?为目标帧中每个像素j的真实颜色 。
 文章插图
文章插图
[资源链接:]
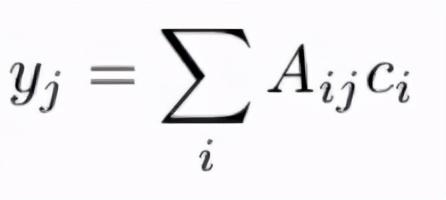 文章插图
文章插图
公式1:预测颜色与参考颜色的线性组合
如何计算相似度矩阵无论是图像、参考帧还是目标帧都经过模型学习后对每个像素进行了低层次的嵌入 , 这里f?是像素i在参考帧中的嵌入 , 类似地 , f是像素j在目标帧中的嵌入 。 然后 , 计算相似度矩阵:
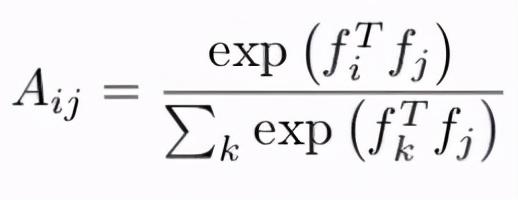 文章插图
文章插图
公式2:用softmax归一化的内积相似度
相似矩阵中的每一行表示参考帧的所有像素i和目标帧的像素j之间的相似性 , 因此为了使总权重为1 , 我们对每一行应用softmax 。
Lets look an example with dimension to make it clear,we try to find a similarity matrix of 1 pixel from target frame.An illustration of this example is shown below.Consider reference image and target image, size (5, 5) => (25,1)for each pixel, cnn gives embedding of size (64, 1), embedding for reference frame, size (64, 25), embedding for target frame, size (64, 25),embedding for 3rd pixel in target frame, size (64, 1)Similarity Matrix, between reference frame and target pixel, j=2=softmax, size (25, 64)(64, 1) => (25,1) =>(5, 5)we get a similarity between all the ref pixels and a target pixel at j=2.Colorization, To copy the color (here, colours are not RGB but quantized colour of with 1 channel) from reference frame,, Colors of reference frame size (5, 5) => (25, 1), Similarity matrix, size (5, 5) => (1, 25)Predicted color at j=2, , size (1, 25) (25, 1) => (1, 1)From the similarity matrix in below figure, we can see reference color at i=1 is dominant(0.46), thus we have a color copied for target, j=2 from reference, i=1PS:1. ? denotes transpose2. matrix indices starts from 0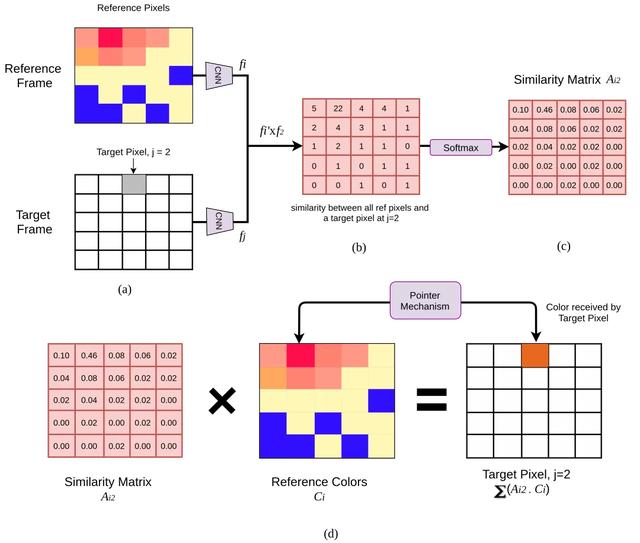 文章插图
文章插图
(a)为2帧大小(5,5) , (b)为参考帧嵌入与目标像素在j =2处嵌入的内积 , (c) softmax后的相似度矩阵 , (d)相似度矩阵与参考帧真颜色的线性组合[来源:]
同样,对于目标帧中的每个目标像素((5 , 5)=> 25个像素) , 我们将会有一个相似矩阵的大小(5,5),即大小为(5 , 5 , 25)的完整相似度矩阵A?? =(25 , 25) 。
在实现中 , 我们将使用(256 x 256)图像扩展相同的概念 。
图像量化
 文章插图
文章插图
第一行显示原始帧 , 第二行显示来自实验室空间的ab颜色通道 。 第三行将颜色空间量化到离散的容器中 , 并打乱颜色 , 使效果更加明显 。 [来源:]
- Dubai视频通话
- 对微前端的11个错误认识
- 看了PS5的拆机视频,下世代主机最重要的配件可能是空调
- 国务院通过最新规划,新能源汽车新风口定了
- 全球首个交互式全息视频显示器问世 有望嵌入智能手机
- MakerBot宣布通过尼龙12碳纤维扩大其材料供应范围
- 今天才知道,原来手机就能给视频添加字幕,手把手教会你
- 今天才发现,原来用微信拍视频还能添加字幕,既简单又好玩
- 高通骁龙888登场,雷军录祝贺视频并抢下全球首发,华为不能用
- BBC:为了应对气候变化,看视频时不要选“高清模式”