NET Core微服务之路:再谈分布式系统中一致性问题分析( 二 )
Q4.常见案例:掉单
掉单一般常见于协作工作的系统的流程中 , 分别对彼此的上游和下游 。 比如上面的案例 , 你已成功下单并支付 , 按照流程 , 平台应该告诉物流我有物品需要配送 , 过来取单 , 可物流终究收不到这个收单请求 , 导致物品配送失败 , 严重会导致赔付 , 这样的不一致性通常是一个系统中的两个请求不一致而造成的 。
Q5.系统案例:系统状态
这个案例跟上面的掉单案例类似 , 只是需要区分引起这个掉单的原因 , 其实就是两个系统的状态不一致所造成 。 比如上游及时收到请求并响应 , 而下游却因为某个状态(原因)而没响应这个请求 , 最终导致不一致形成 。
Q6.系统案例:本地缓存和数据库
现在存储都依赖于数据库 , 而关系型数据库都具备ACID特性 , 但是在大规模高并发的互联网系统里 , 一些特殊的场景对度的性能要求极高 , 为止 , 服务在这个上面的数据库将难以抗住大规模的读流量 , 为了应对这样的问题 , 一般都会在数据库前增加缓存 , 那么缓存和数据库之间的数据是如何保持一致?是需要强一致还是弱一致?
Q7.系统案例:节点缓存
一个服务域上的多个节点为了满足较高的性能要求 , 需要使用到本地缓存 , 使用了本地缓存 , 每个节点都会有一份缓存数据的拷贝 , 如果这些数据是静态的、不变的 , 那永远都不会有任何问题 。 但如果这些数据是动态的、经常更新的 。 那么问题就来了 , 当被更新的时候 , 各个节点的更新都会存在先后顺序 , 而正是这先后顺序的一瞬间 , 各个节点的数据将会不一致 。 想象一个高流量读的场景中 , 一个请求拿到的数据是1 , 而另一个请求拿到的是0 , 这将导致灾难性的后果 。
Q8.系统案例:超时
服务化的系统间调用常常因为网络问题导致系统间调用超时 , 这是在即便在网络最好的机房下、在上亿次的前提下 , 同步调用超时也是必然会存在的 , 正如上面提到的不同状态类似 , 假如当下单和物流存在极高请求的情况下 , 物流并未及时反馈响应 , 而下单却并不知道物流是否已经接到订单 , 或者定已收到订单 , 只是掉包了等现象 , 这样的不一致 , 也是会导致灾难性后果的 。
解决模型
对于Q1问题 , 我们可以有两套方案 , 一是不结了 , 不过显然这是行不通的;二是慢慢的补偿 , 先买个一般的 , 等手头资金充裕了 , 或者某天中了500万 , 或者天上掉个金块 , 再给她个惊喜 , 于是 , 这个问题解决了 , 大家的意愿都一致了 , 都开心了 。 可见 , 这样的解决模式会存在一个现象---过渡时期 , 当这个过渡时期到最终双方都达成一致时 , 问题就解决了 。 因此 , 我们不能要求在买对戒的时候 , 双方都达到强一致的要求 , 生活是必须要过下去的 , 不可能说散就散 , 那么我们要考虑去补偿她 , 尽最大的努力达到最终一致 。
在化学单词中 , “ACID”是酸 , 我想这绝对不是巧合 , 原文可参考百科
(computer_science) 。 在关系型数据库中我们都知道ACID原理 , 关系型数据库天生解决具有复杂场景问题 , 需要保证一致的 , 每个事务都是原子的 , 要么都成功或要么都失败 , 事务间是相互隔离的 , 而且相互完全不影响 , 而最终结果是持久的 。
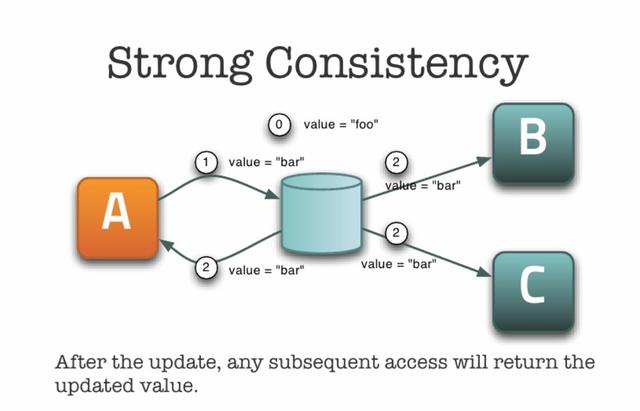 文章插图
文章插图
因此 , 数据库会从一个明确的状态到另外一个明确的状态 , 中间的临时状态是不会出现的 , EF的追踪功能也正是遵循这个原则进行设计 , 任何一个操作状态在中途是不会存在改变 , 如果出现改变 , 将会给你提示错误 , 当然 , 你可以关掉它 , 不过这样EF的核心点就不存在了 。