使用半监督学习从研究到产品化的3个教训( 四 )
特别是在物体检测中 , 当物体的位置和大小在你的应用领域中遵循某些规则时 , 你可以定义类似这样的启发式方法来优化嘈杂的伪标签 , 并帮助你的学生模型学习到教师模型不能学到的更好的表示 。
使用启发式伪标签改进 , 我们能够在Noisy Student模型中取得更好的表现 , 在某些情况下 , 未标记数据比标记数据少个数量级 。 我们还发现 , 这个结论听起来与Rosenberg等人 , 2005年发表的一篇论文的观察结果惊人地相似 。
一个独立于检测器的训练数据选择度量方法大大优于基于检测器生成的检测置信度的选择度量方法 。
这是所有数据和建模问题的解决方案吗?当然不是 —— 但它说明了启发式在深度(半监督)学习管道中仍然是一个有用的部分 。 同样 , 这里应用的启发式是特定于领域的 , 只有仔细研究你的数据和模型的偏差才能得到有用的伪标签改进 。
Lesson #3: 使用半监督在图像分类上的进步很难迁移到物体检测中我们在SSL研究中取得的大部分进展都是基于对图像分类性能的测量 , 希望能够轻松地对其他任务(如物体检测)进行类似的改进 。 然而 , 在我们尝试采用图像分类方法进行目标检测时 , 我们遇到了几个挑战 —— 这导致我们坚持使用Lesson #1中提到的最简单的半监督目标检测方法 。
以下是其中的一些挑战:
- Online vs. Offline 伪标签生成
FixMatch和UDA是SSL技术的例子 , 它们利用在线学习来达到一个阈值 , 只允许预测超过某个阈值的未标记样本来帮助训练 —— 在Noisy Student和STAC (FixMatch的一个对物体测变体)中 , 然而 , 伪标签是离线生成的 。
虽然在线学习似乎是有利的 —— 允许在训练早期差的伪标签在以后的训练步骤中得到纠正 —— 它使得训练的计算成本更高 , 对于训练物体检测模型更是如此 。 为什么?两件事:数据增强和批处理大小 。 关于数据增强 , 让我们回顾一下在 lesson #1关于FixMatch的的图 。
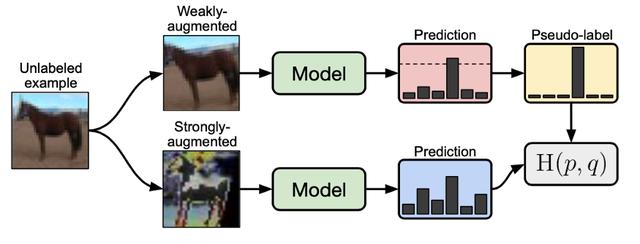 文章插图
文章插图在FixMatch中没有标记的图像对损失函数的贡献
我们可以看到 , 每个未标记的样本在训练时都是“弱增强”和“强增强” , 需要将两张增强的图像通过网络前向传播 , 计算损失 。 这样的数据增强是许多SSL方法的基础 , 虽然对于图像分类来说是可行的 , 但对于大图像(512x512+)上的目标检测任务 , 训练时的处理时间的增加显著降低了训练速度 。
在batch size方面 , 许多文章(MixMatch, UDA, FixMatch, Noisy Student)和我们自己的实验也强调了没有标记的数据的batch size是标记的数据的几倍对SSL方法的成功是至关重要的 。 这种对目标检测任务的要求 , 加上内存中的大图像 , 以及对未标记batch size中的所有样本的必要扩充 , 造成了极大的计算负担 。 这两个挑战 , 数据增加和未标记数据的batch size , 使得我们不能将比如FixMatch一对一的迁移到物体检测中 。
在与STAC的作者的讨论中 , 他们还注意到 , 在半监督物体检测领域 , 在线学习带来的巨大资源开销 。 我们希望未来的工作能更深入地研究这个问题 , 并且希望在未来几年的成果能让研究人员更容易地了解这个问题 。
- 管理长尾与类别均衡
- 不看不知道 80%的人使用耳机的习惯都错了
- 研究发现许多iOS加密措施实际上未被使用
- 雷蛇RGB口罩真的来了!N95级别可重复使用
- 学习了大数据开发知识,但是面试却屡屡碰壁该怎么办
- 大一上学期学了Python,希望主攻大数据还应该学习什么语言
- 大一下学期转入计算机专业,寒假期间该重点学习什么内容
- Android 12或让未使用的App休眠以节省系统资源
- iOS 14.4版开始将对使用非原装摄像头的iPhone弹出警告
- 从运维岗转向开发岗,该选择学习Java还是Python
- 想学习编程,该从哪开始